
Inspiration
Nowadays, video chats have become the norm in communication - for obvious reasons. We don’t think people should be expected to be presentable for all these calls, so we wanted a way for people to look their best at morning standup while also lying in bed.
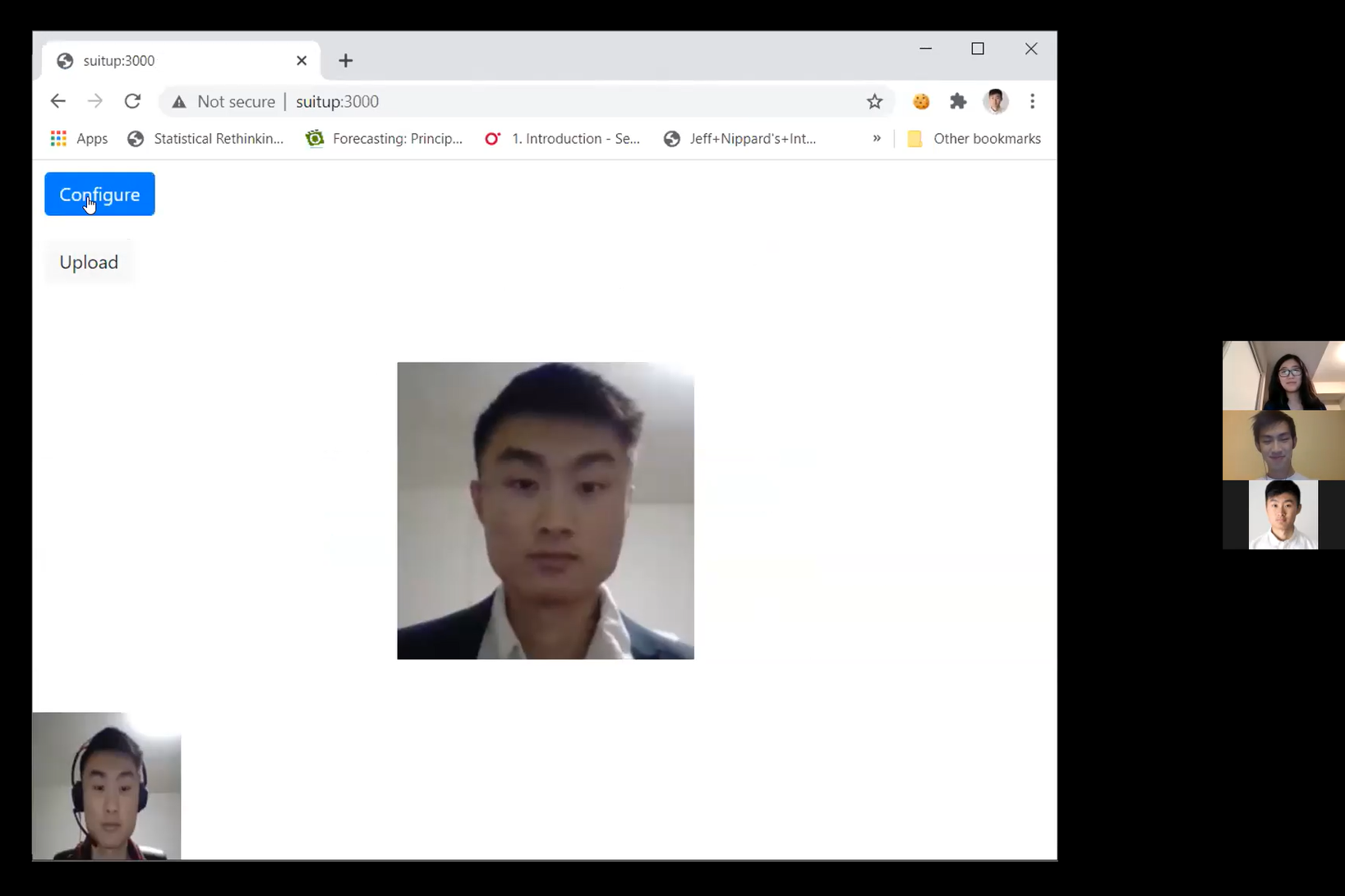
What it does
Suit Up! dresses you up on camera so you can do morning standup in bed. It's an app that allows you to animate a source image (as long as it’s of yourself) according to a driving video received from your device’s camera. The animated video can then be used for your video call on any platform, such as Zoom or Discord. We use server-side neural networks powered by GPUs to track “keypoints” on the source image’s face and match it with the input video. We also use this neural network to do facial recognition between the source image and driving video -- this way you can only ever suit up using a photo of yourself.
How we built it
The client and servers were built using Flask as a lightweight wrapper around our both IO and compute intensive demands. We have 3 main neural networks leveraging GPU, a keypoint model, image generation model, and facial embedding model. The main animation modelling is based off the First Order Model for image animation by Siarohin et al. The main innovation of our project was implementing real time image animation, without allowing misuse. We focused on lowering latency from video streaming as well as latency in the neural network computation involved in the image animation.
Challenges we ran into
Our biggest issue was probably latency. For each frame of the input video, we needed to do some heavy computations server-side to properly animate the source image. The result of this was laggy and sometimes iffy animations. We worked around this in a couple of ways:
- We experimented with a bunch of protocols for rapid data transfer between the server and client. Among this were websockets, polling, and just spam POST-requesting.
- We streamlined the way the model was animating the source image to match the driving video by precomputing as much as possible while making best use of GPU memory and efficient image processing.
Accomplishments that we're proud of
We’re pretty happy we got a functional app that could generate some pretty convincing videos in real-time!
What we learned
We learned a whole bunch about web data transfer protocols, as well as the bottlenecks in realtime ML. Real-time GPU processing always has the overhead of data transfer into GPU memory, it’s important to understand what operations are worth paying that overhead. In addition, it’s incredibly important to realistically profile your model in a production environment, the impact of locality and caching can be huge. In terms of smoothness, we experienced a trade off between latency and signal. If we used more frames to smooth out the next frame, we’d react slower to changing in the driving video.
What's next for Suit Up!
A feature we really wanted to implement but ran out of time for was to improve the way we were animating the source image. In general, only the face is really changing in the driving video so we’d like a way to isolate the face of the source image and only animate that instead of the background. We think this both makes the video more convincing and also allows us to do the animations while not requiring as much processing power.





Log in or sign up for Devpost to join the conversation.