-
-

-

-

MLRun pipeline
-

Model training flow
-

Heroku webpage
-

Iguzio data science platform





Overview
💡Inspiration
Suicide might be considered as one of the most serious social health problems in modern society. Every year, almost 800,000 people commit suicide. Suicide remains the second leading cause of death among a young generation with an overall suicide rate of 10.5 per 100,000 people. Especially in this pandemic suicide rate has increased due to people stressing alot about their career and family. Many factors can lead to suicide, for example, personal issues, such as hopelessness, severe anxiety, or impulsivity; social factors, like social isolation and overexposure to deaths; or negative life events, and previous suicide attempts, etc. Millions of peoples around the world fall victims to suicide every year, making suicide prevention become a critical global public health mission.
🧐What it does
Early detection and treatment are regarded as the most effective ways to prevent suicidal ideation and potential suicide attempts—two critical risk factors resulting in successful suicides.
In this project, we propose an API that can be used to tag any textual data with a potential suicidal thought tag or neutral tag.
We used supervised Machine learning to train our model which can detect the Suicidal severity of the post.
We also deployed our model on Heroku using Flask and mlrun alongwith MongoDB Atlas to demonstrate the applicability of the project.
🖥How we built it
We took a tweet dataset published on this Github repository. We trained our model on two different models SGD classifier and the simple preceptor model.
We used mlrun to automate our pipeline. We first fetch the dataset from the MongoDB Atlas database, pre-process it, and trained two models discussed earlier, and finally, the best model is used for serving.
We also deployed it on Heroku to display the applicability of the API.
Our pipeline is fully automated and robust to data accusation when someone uses our API, it stores each instance in a CSV file on the server and once it reached a limit, the pipeline automatically pushes the data to the MongoDB database and retrain the models. Also, choose the best model out of two for severing, so basically we are doing Semi-Supervise learning to make our model better.
📚 Data we used
We used data of the posts by the people posting suicidal and normal tweets. This data is kept on MongoDB Atlas . label '1' from the dataset represents suicidal and label '0' as neutral. The total number of samples is 9119 and it is distributed as 4000 and 5119 for suicidal and neutral ones respectively.
eg. I'll kill myself am tired of living depressed and alone _Suicidal
eg. It's such a hot day, I'd like to have ice cream and visit the park _Neutral
⛓Pipeline workflow
For the pipeline automation and tracking of logs, we used an open-sourced mlrun library which gives us the flexibility to create a Machine learning pipeline, manage the pipeline logs, and deploy it in a production environment.
The features we leveraged from this library are automated data fetching and preparation, model training and testing, deployment of real-time production pipelines, and end-to-end monitoring using Heroku server logs.
The image below depicts our MLRun pipeline workflow

We successfully implemented the following process with help of mlrun.
⚙️ Fetching data.
Data are stored in MongoDB atlas on a cloud database. When the mlrun pipeline is executed the fetch function will download the suicide dataset from the MongoDB Atlas database, convert it into DataFrame and serve it for data transformation.

🔩 Transformation of data.
The process of pre-processing is added to tranform function of the pipeline, we took advantage of the mlrun's PlotArtifacts API to plot some insight of the dataset. Finally the function pre-process our dataset and serve it for model training.
![]()
⏱Model training and evaluation.
In this pipeline we are training our data on multiple models
- SGD classifier
- Preceptron model

The dataset is trained on both models, then after evaluation, the accuracy is compared in the pipeline. And the best model is saved and used for serving with the help of mlrun.
The logs of the model training were tracked by mlrun for both models. Here also we took advantage of mlrun's PlotArtifacts API to plot the accuracies of the model. Below is an example of the log.

🍛Model serving.
After pre-processing and model training , best model was selected by the pipeline and used for inference. With help of mlrun with serve our model for testing. Example is dmonstrated below.

🛠Model retraining.
This one of the main features of our pipeline. We integrated retraining of our models using two different processes-
- Inference time data: We collected the data produce during inference time, we stored the input data and predicted labels on our server in a
CSVfile. Once the data reaches a limit of 1000 samples. Our pipeline pushes the dataset toMongoBD atlason the cloud and begins the retraining process, discussed earlier. - Bulk training: We also integrated bulk training in our pipeline. When we collect datasets from other sources in bulk, we can use
/bulktrainingAPI. We can pass the CSV file, our pipeline will store the dataset on the cloud and begin the retraining process, discussed earlier.
> Bulk training API is not live for the public as it can be miss-use, and it can temper out dataset and model.
🌐Iguazio Data Science platform
We were fortunate to get access to the Iguazio data science platform to demonstrate our project. We deployed and ran our pipeline on the Iguazio Data science platform.
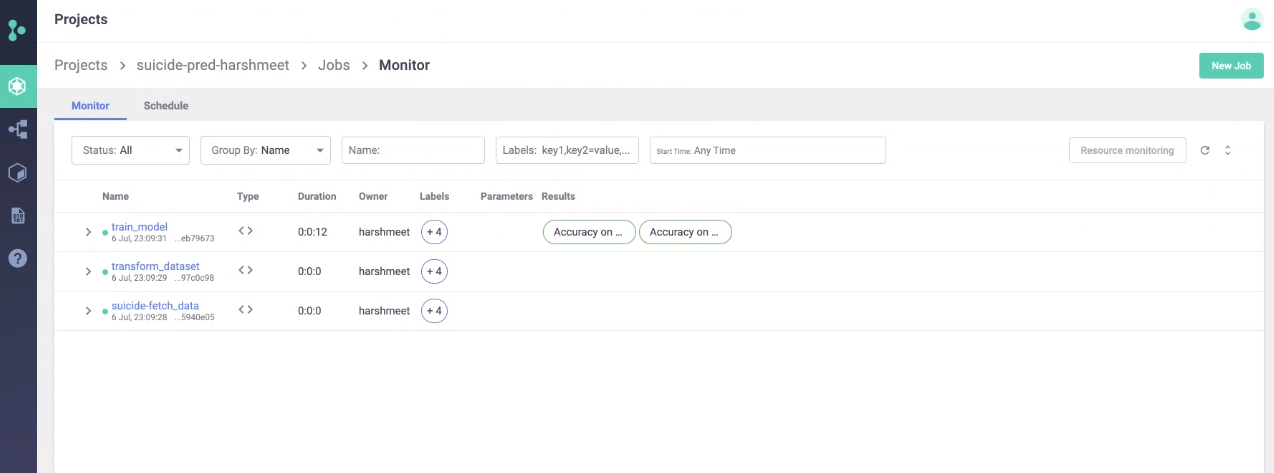
Below are some of the screenshot which demonstrates artifacts, result, and logs produce during training.
Monitor dashboard for tracking the pipeline.

Training artifact are stored here.

Training results are also shown in real-time.

Training logs can be seen here in real time.

🔥Accomplishments that we're proud of
- This project can help in
Early detectionof suicidal thoughts which is one of the ways for suicide prevention - Our project demonstrates a robust pipeline that is automated with help of
mlrunlibrary. - Our project has multiple independent steps for data acquisition from ` MongoDB Atlas database, pre-processing, and training of the model.
- We also include multiple models in our project for training so as to get a better model for serving.
- For data acquisition, we included functionality in our pipeline to retrain the model once a certain amount of data is collected.
- We incorporated bulk training facility in our pipeline.
- Our pipeline is deployed on
Herokuin real-time with help ofFlaskandmlrunlibrary. - We included our notebook which will help others to convert their project into
MLRUNpipeline. - We also include all code and documentation on Github on how to deploy the pipeline on Heroku.
❓What's next for Suicide predictions
We plan to incorporate a few more classification classes so as to get more information out of the text, which will help in better prediction of the suicidal severity. We also planned to create a Qn/A chatbot, which will be helpful for people dealing with suicidal thoughts.
This project is not limited to only Suicide post prediction, in this new age social media world, textual data is being generated every second. These data can be leveraged in many ways, like deep sentiment analysis, healthcare-related problems can be solved, hate and toxicity of the post can be detected to stop bullying, etc.
🧾 Project documentation
- All code used in this project available in our GitHub repo
- Jupyter Notebook used in the project is also available GitHub repo
- We also provide the documentation on How to deploy the Pipeline on Heroku using Flask.
🔬 References
- https://docs.atlas.mongodb.com/
- https://github.com/mlrun/mlrun
- https://devcenter.heroku.com/categories/python-support
- https://github.com/AminuIsrael/Predicting-Suicide-Ideation
👥Team members
- Mohammad Ahmad
- Krutarth Bhatt
- Harshmeet singh
- Vaidehi Rathor
Feel free to ask any thing about the project.












Log in or sign up for Devpost to join the conversation.