Inspiration
- Healthcare systems around the world face a quiet but dangerous problem: Many patients receive complex lab reports filled with acronyms, numbers, and reference ranges, then leave with little understanding of what those results **actually mean.
- In Vietnam, France, the Arab world, and beyond, patients often hold a PDF showing creatinine or eGFR values and have no idea whether they should be concerned. Doctors may only have a few rushed minutes. Search engines often create more panic than clarity.
- Therefore, we built ClinicLens as we believe AI can close that gap, not by replacing clinicians, but by acting as an always-available, non-judgmental translator that helps people understand their own health before they step into the consultation room.
- The inspiration is both personal and universal: the confusion on a parent’s face while holding a report they cannot read, the anxiety between receiving results and seeing a doctor, and the truth that early awareness saves lives. AI can finally make that awareness accessible to everyone, regardless of language or health literacy.
What it does
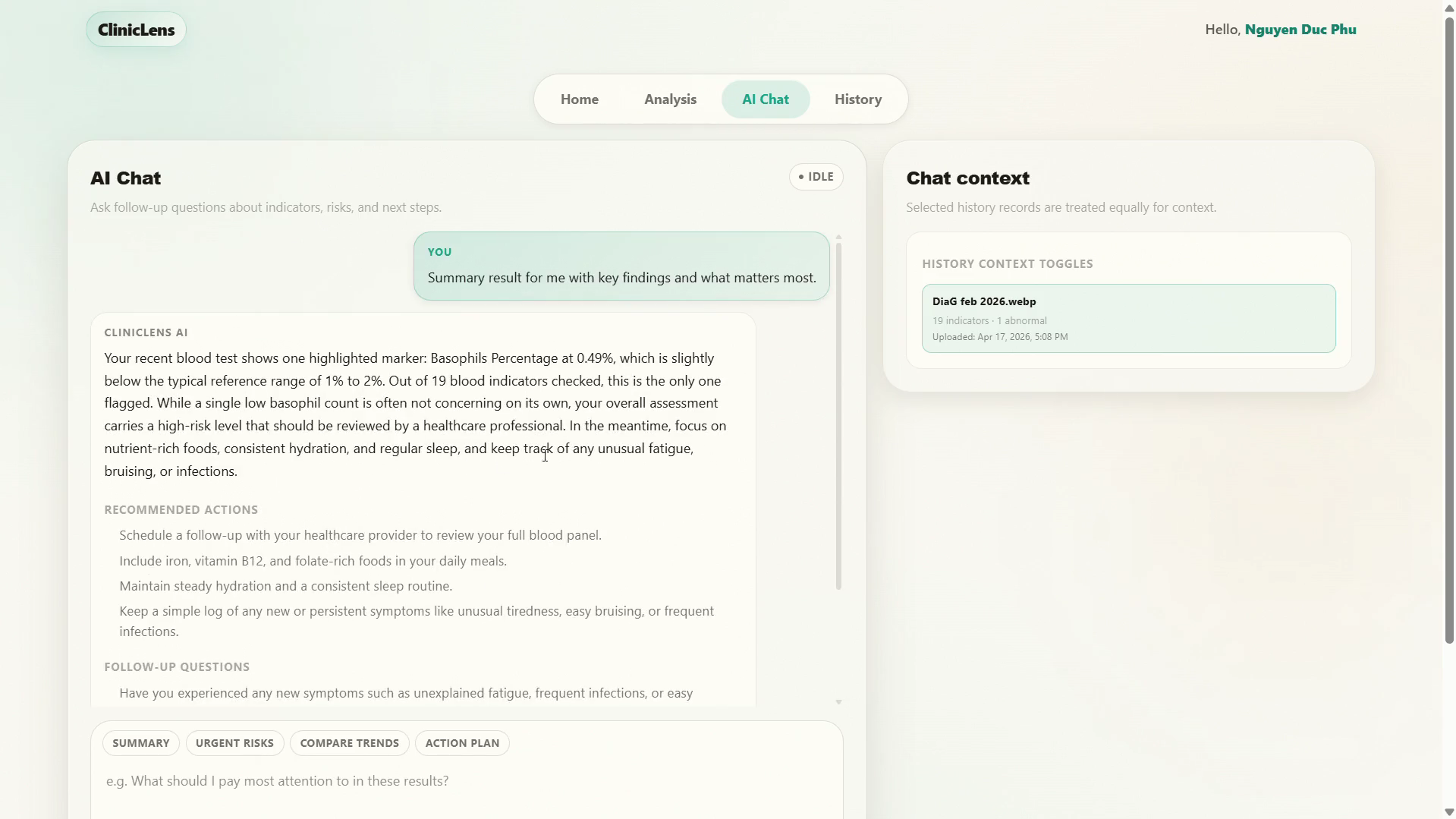
ClinicLens allows users to upload a lab report as a PDF or image. The system extracts all lab indicators, classifies them by organ and severity, and returns a structured, patient-readable breakdown in real time. Users can then ask follow-up questions through a chat interface grounded exclusively on their extracted results.
Key features:
File upload with secure OSS storage - Files are uploaded directly from the browser to Alibaba Cloud OSS using short-lived STS credentials. The backend never holds file bytes in memory.
Real-time streaming analysis - Progress is delivered via Server-Sent Events (SSE) with named stages, so users see incremental status rather than a loading spinner.
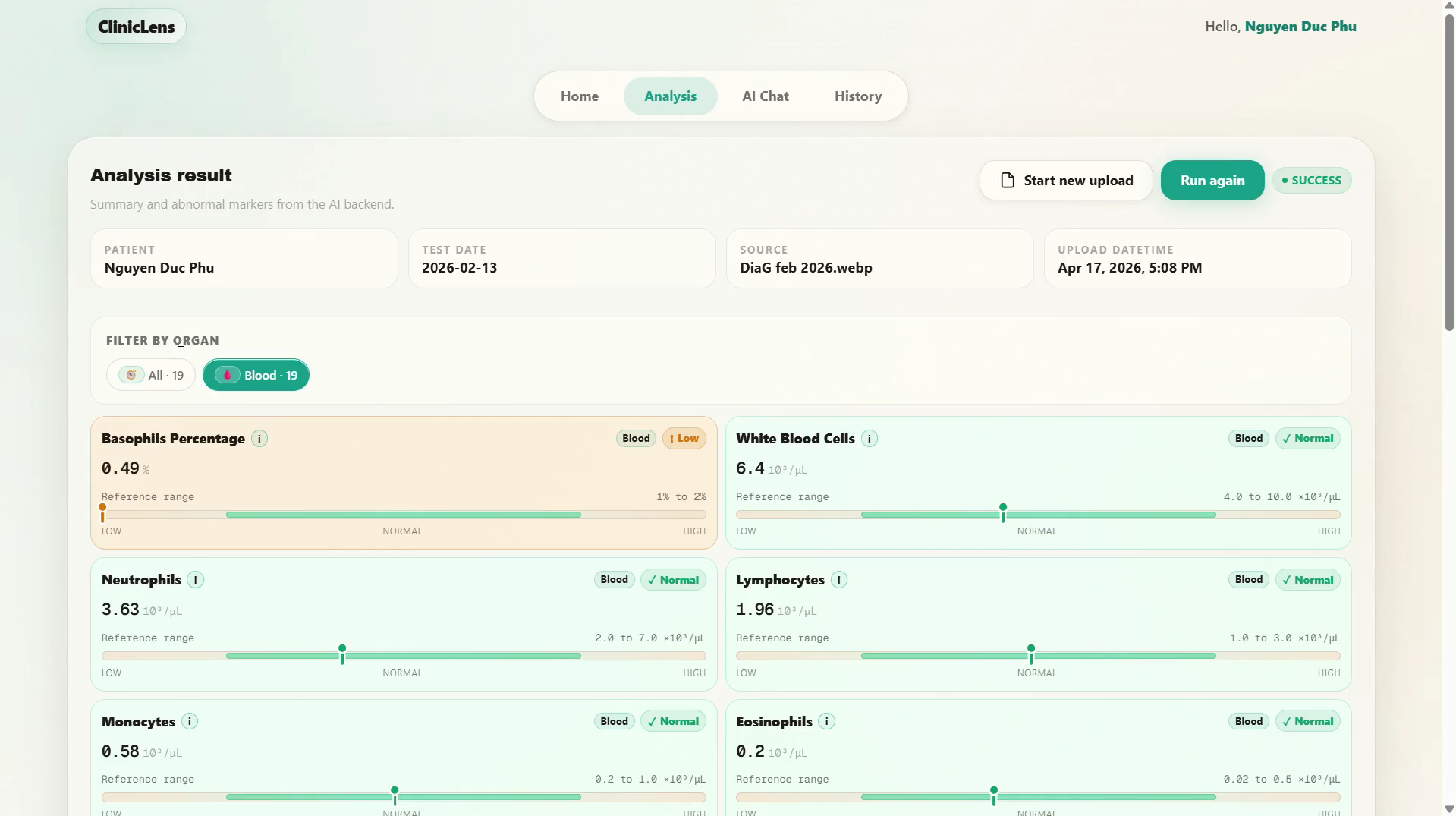
Structured indicator extraction - Each lab result is tagged with: organ system (10 categories), severity classification (normal / abnormal_high / abnormal_low / critical / unknown), reference range (numeric, threshold, or qualitative), bilingual indicator name, and a short patient-facing advice note.
Organ-level overview - Results are grouped by organ and sorted by severity, with a summary panel showing total, abnormal, and critical counts.
AI chat - Context-grounded chat using Qwen, with multi-turn memory, emergency keyword detection, and structured output including risk level, recommended actions, a 7-day plan, and a medical disclaimer.
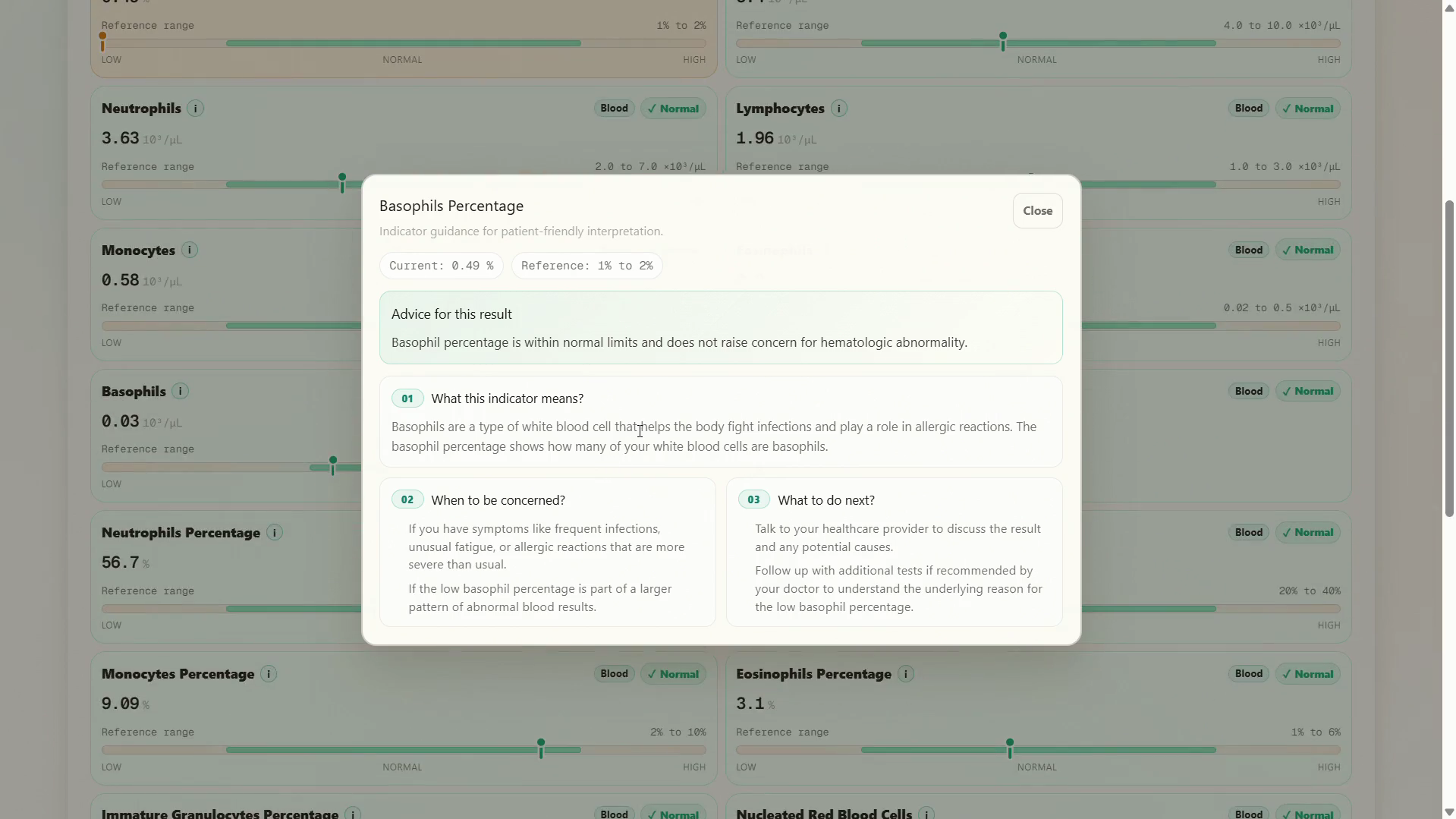
Indicator drill-down - Any individual indicator can be expanded to show what it measures, when the value is concerning, and what to do next. Responses are cached in memory.
Multi-record chat context - Users can select up to 5 historical records to include as context, and the system computes a trend snapshot when the same patient has multiple analyses.
How we built it
Frontend
Next.js 14 + TypeScript 5.8.
A central SmartLabsApp component manages all app state; tab-scoped child components (OverviewTab, ChatTab, HistoryTab) receive typed props.
SSE consumption is implemented as async generators on the client. Session history is stored in
sessionStorage to survive page refreshes.
Backend
Node.js 20 / Express 4. Two distinct analysis paths:
- Image path - The signed OSS URL is passed directly to
qwen-vl-plusfor streaming extraction. - PDF path - A Python subprocess (
analysis_pdf_pipeline.py) converts each page to PNG using PyMuPDF, classifies pages asmedical_dataornon_medical_page, detects document language (EN / VI / FR / AR), extracts each relevant page individually, then merges and deduplicates results by a canonical composite key.
Four Qwen models are used for different tasks:
| Model | Task |
|---|---|
qwen3-vl-plus |
Multimodal indicator extraction |
qwen3.6-flash |
Summary and clinical advice generation |
qwen3.6-flash |
Multi-turn chat |
qwen-turbo |
Indicator explanations (cost-optimised, cached) |
Post-processing (analysis_runtime.js) handles organ/severity alias resolution,
structured reference range parsing, severity re-derivation from computed value-vs-range arithmetic,
non-English text detection and fallback, and a bracket-matching JSON extractor tolerant of markdown
fences and prose preamble.
Prompt design
The extraction prompt (analysis_system_prompt.md) is a typed contract, defining the output JSON
schema, organ-to-indicator mappings, severity rules, and explicit constraints against hallucination
and reference-range inference. It is version-controlled and loaded at boot without code changes.
Cloud & Deployment
| Service | Role |
|---|---|
| Alibaba DashScope (SG) | All AI inference via OpenAI-compatible endpoint |
| Alibaba OSS | File storage (private bucket, HTTPS enforced) |
| Alibaba STS | Short-lived write-only browser upload credentials |
| Render | Backend (Node.js, Alpine, render.yaml Blueprint) |
| Vercel | Frontend (Next.js) |
Challenges we ran into
Multi-page PDF extraction. A single pass to Qwen on a full PDF URL was unreliable for complex multi-page documents. We rebuilt the pipeline as a per-page classify-then-extract flow, which improved completeness but added latency and AWS API call volume.
Model output variability. Qwen VL returns JSON in various formats — raw, markdown-fenced, embedded in prose, or truncated at token limits. We wrote a bracket-matching extractor in both Python and JavaScript, with a fallback to a summary file written to disk if stdout parsing fails.
Non-English field pollution. Advice and explanation fields sometimes contained Vietnamese or French text despite English-only instructions. We added Unicode script detection and heuristic keyword lists to identify and replace non-English strings in all English-constrained output fields.
Response format compatibility. The json_schema and json_object response formats are not
uniformly supported across Qwen model tiers. We added a fallback that detects the 400/422 rejection
and retries without the format constraint.
Chat hallucination. Early versions of the chat prompt produced responses citing indicator values
not present in the report. We restructured the context payload to pass only extracted abnormal
results, added explicit constraint fields to the user message JSON, and implemented allowlist
validation in sanitizeChatResult to strip any cited indicators or organs not found in the analysis.
Accomplishments that we're proud of
End-to-end multilingual pipeline: Detects document language, classifies pages, extracts and normalizes indicators, translates names to English, and returns structured JSON - across Vietnamese, French, Arabic, and English documents - without manual intervention.
Severity re-derivation: When the model's reported severity conflicts with the extracted reference range, the system re-derives severity from value-vs-bounds arithmetic. This is a concrete clinical safety mechanism, not just a display feature.
Structured SSE architecture: All long-running operations use named SSE events with typed payloads, abort controller integration, client-disconnect detection, and Qwen stream cancellation. Both the analysis and chat endpoints follow the same contract.
Security design: STS tokens are scoped to write-only access with a 15-minute expiry. Signed read URLs are generated on demand. No raw credentials are passed to the browser.
What we learned
Prompts as typed contracts. The most reliable extractions came when the system prompt defined an exact JSON schema, explicit field constraints, and error output format — essentially a typed API contract in natural language. Vague instructions produced inconsistent outputs.
Multi-pass pipelines trade latency for accuracy. Processing PDFs page-by-page (language detection → classification → extraction → merge) increased accuracy on complex documents, but requires 4–10+ API calls per upload. This trade-off needs to be managed carefully at scale.
Hallucination prevention is an engineering task. Reliable grounding required all four of: (1) explicit prompt constraints, (2) JSON schema validation in the runtime, (3) allowlist filtering of cited entities, and (4) structured fallbacks. No single mechanism was sufficient on its own.
DashScope VL models handle real medical documents well. Qwen VL correctly extracted indicator values from Vietnamese-language PDFs, distinguished data pages from cover pages and signature pages, and handled misaligned table columns with reasonable accuracy.
What's next for ClinicLens
Near-term
- Persistent storage (PostgreSQL / Supabase) to replace the flat JSON file and sessionStorage
- User accounts and access control
- Mobile app (React Native) with camera-based document capture
Medium-term
- Clinician dashboard (B2B SaaS tier): patient list, critical value alerts, trend comparison
- Longitudinal trend charts when the same patient has 3+ records
- Support for Thai, Indonesian, and Hindi lab reports
Long-term
- HIPAA / ISO 13485 compliance review for clinical deployment
- FHIR / HL7 import from hospital information systems
- Developer API to expose the extraction pipeline to third-party health apps
Built With
- alibaba
- css
- dashscope
- events
- express.js
- next.js
- node.js
- oss
- pymupdf
- python
- qwen
- react
- render
- server-sent
- sts
- typescript
- vercel
- vl




Log in or sign up for Devpost to join the conversation.