-
-
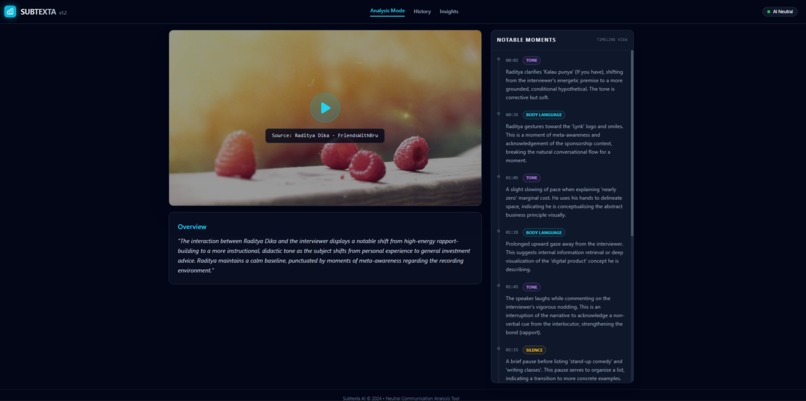
Subtexta is an MVP powered by Gemini 3, focused on Analysis Mode to analyze podcast videos. Other sections are placeholders.
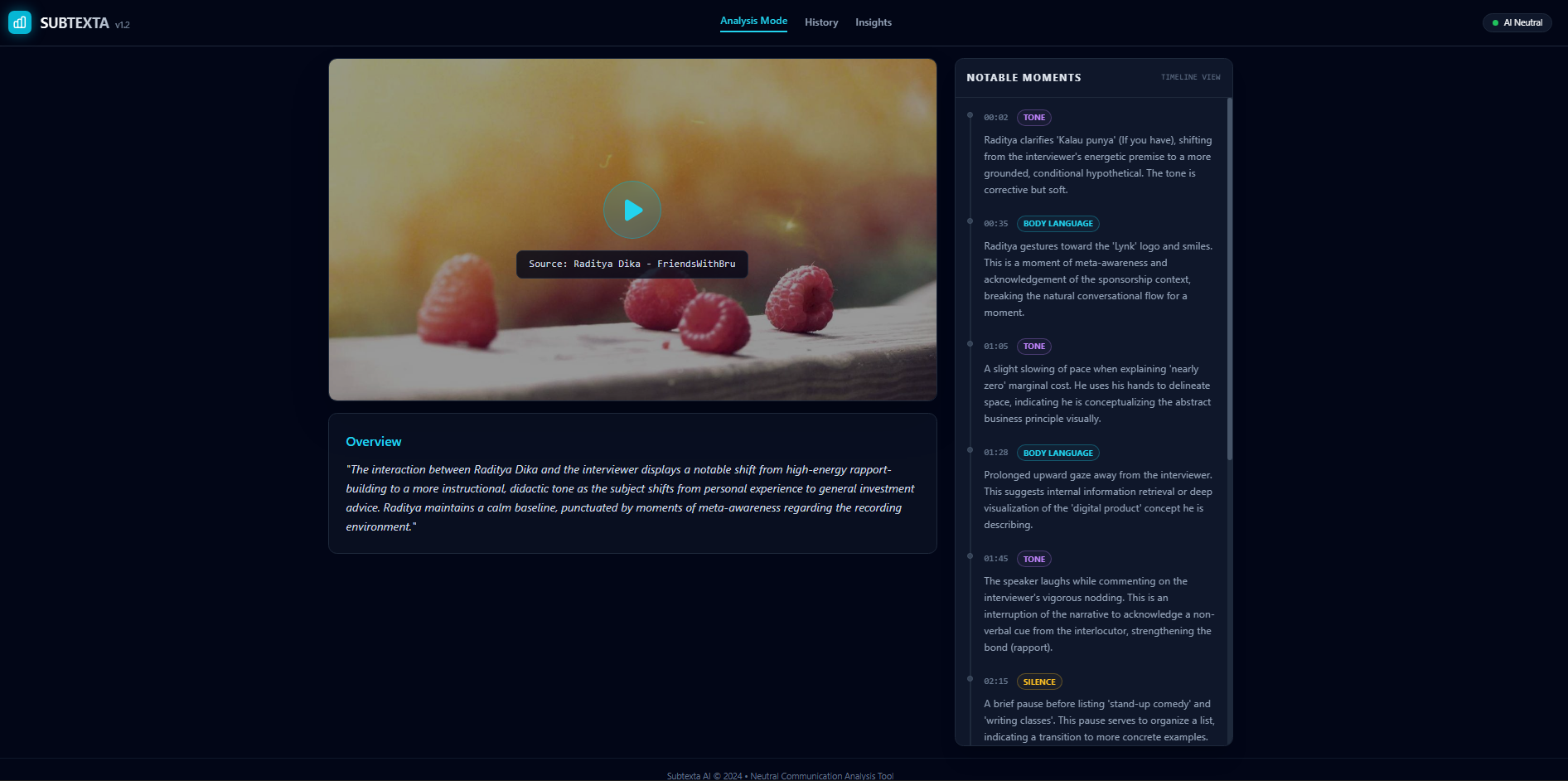
Inspiration
Human communication is not only shaped by words, but by what happens between them. In interviews, debates, podcasts, and everyday conversations, silence, hesitation, tone shifts, and facial expressions often carry more meaning than spoken language. However, most AI systems today focus exclusively on text or speech content, ignoring these subtle but critical signals.
Subtexta was inspired by this gap. We wanted to explore whether AI could help people better understand unspoken signals without making assumptions or judgments. By leveraging advances in multimodal reasoning, Subtexta aims to surface interpretative insights rather than definitive conclusions, encouraging reflection instead of verdicts.
What it does
Subtexta analyzes video and audio recordings of human communication to highlight meaningful moments that are often overlooked. It examines pauses, changes in voice intonation, facial expressions, and the alignment (or misalignment) between what is said and how it is expressed.
Instead of labeling intent or truthfulness, Subtexta produces: - A timeline of significant non-verbal moments - Explanations of why these moments may be meaningful - Clear uncertainty indicators to avoid overinterpretation
This makes Subtexta suitable for interviews, discussions, public speaking analysis, and communication studies.
How we built it
Subtexta is built around the Gemini 3 API as its core reasoning engine. Video and audio inputs are processed to extract visual cues, vocal patterns, and textual meaning. Gemini 3 performs cross-modal reasoning across these inputs, allowing the system to interpret relationships between silence, tone, expression, and language.
Gemini 3’s low latency enables interactive exploration, while its advanced reasoning capabilities allow Subtexta to generate transparent, explainable insights rather than opaque outputs.
Challenges we ran into
One major challenge was avoiding overconfidence in interpretation. Non-verbal signals are inherently ambiguous, so we designed Subtexta to emphasize uncertainty and explanation rather than conclusions. Another challenge was synchronizing multiple modalities—ensuring that audio, visual, and textual signals were interpreted within the same temporal context.
Accomplishments that we're proud of
- Building a non-chatbot AI experience centered on reasoning
- Successfully analyzing silence and hesitation as meaningful signals
- Creating an ethical design that avoids definitive psychological claims
- Delivering an interactive, low-latency multimodal prototype
What we learned
We learned that multimodal AI becomes far more powerful when it focuses on relationships between signals, not isolated features. Transparency and uncertainty are critical when dealing with human behavior, and AI can support understanding without replacing human judgment.
What's next for Subtexta
Next, we plan to expand Subtexta’s temporal analysis, improve micro-expression sensitivity, and introduce comparative analysis across multiple conversations. We also aim to explore applications in education, communication training, and research, while maintaining ethical boundaries in interpretation.
Built With
- css
- fastapi
- ffmpeg
- gcp
- google-ai-studio
- google-gemini3api
- html
- javascript
- python
- web-audioapi

Log in or sign up for Devpost to join the conversation.