-

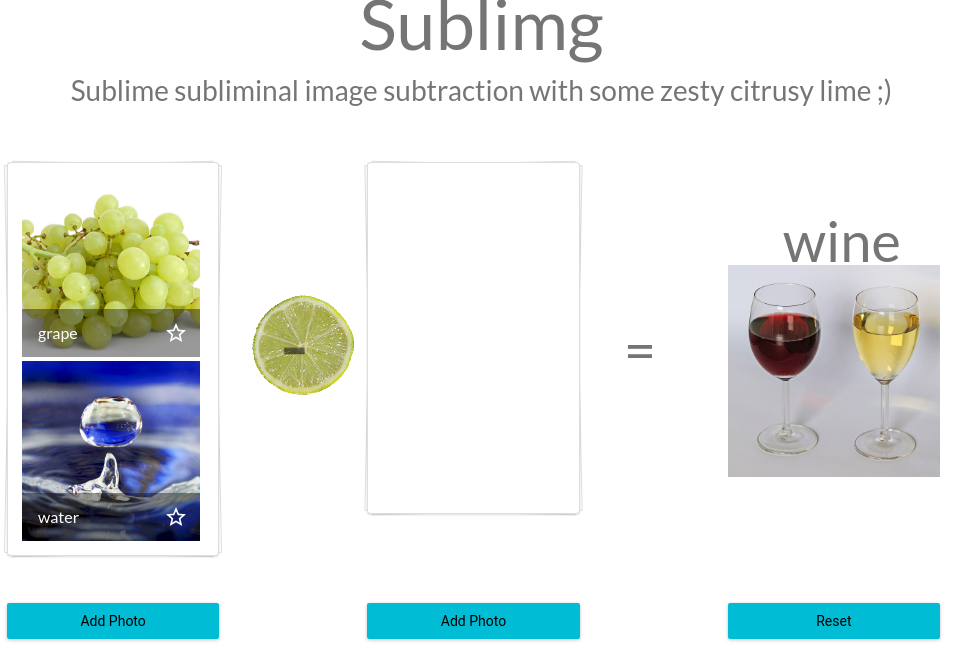
"Grape" + "Water" = "Wine"
-
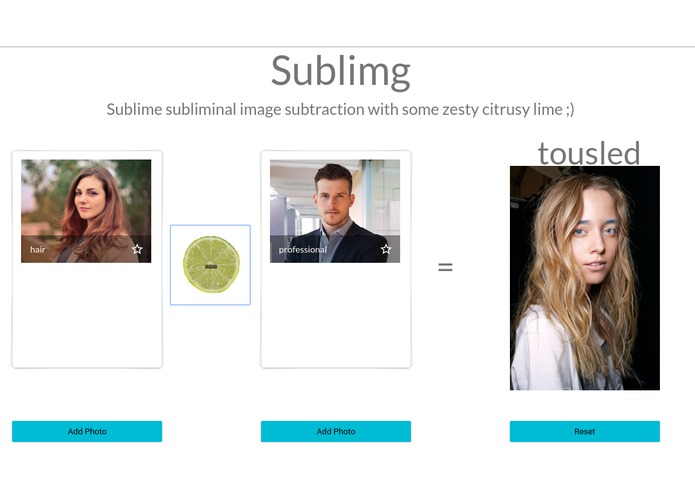
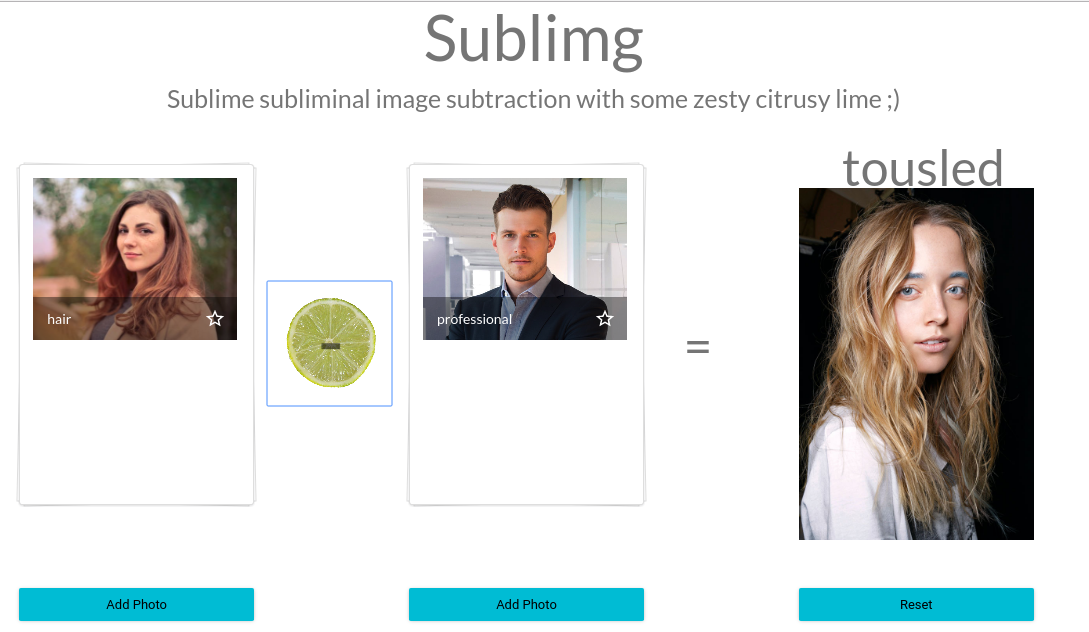
"Hair" - "Professional" = "Tousled"
The Pitch
Semantic image composition. Word embeddings trained on large corpora are well-known to contain semantic information about the embedded words. This allows us to perform interesting operations on the meanings of words.
An example: "Water" + "Grape" = "Wine".
Another one that needs a bit more work to figure out: "Hair" - "Professional" = "Tousled" (which means messy).
What it does and how it's done
- Input images are fed into Google's cloud vision API, which labels the images.
- Labels are transformed into 200-dimensional vectors in Stanford's GloVe word embedding vector space.
- Vector addition and subtraction are performed on the 200-dimensional input vectors to give one output vector.
- The nearest word in the vector space is obtained using k-nearest neighbors (k=1) in the GloVe vector space.
- The word is used as a search query in a standard Google image search and the top image is returned as the final result.
The Stack
- Google Cloud Vision API
- Firebase backend
- Firestore database
- Node.js backend
- React frontend
- Python running the Glove model using word2vec
Log in or sign up for Devpost to join the conversation.