
StudyMind — AI Second Brain for Students
Inspiration
The idea came from a frustration I knew too well personally: spending hours highlighting textbooks and re-reading notes the night before an exam, only to forget most of it by morning. Research shows students forget roughly 70% of new information within 24 hours — a problem known as the Ebbinghaus Forgetting Curve, modelled as:
$$R = e^{-t/S}$$
where (R) is retention, (t) is time elapsed, and (S) is memory strength.
I wanted to build something that actively fights this curve — not just a note-taking app, but an AI that transforms passive reading into active learning: summaries, flashcards, quizzes, and a conversational tutor, all from a single file upload. DigitalOcean Gradient AI made it possible to run all of this on a reliable, developer-first cloud platform without worrying about infrastructure.
What It Does
StudyMind lets students upload any PDF or text file and instantly get:
- Smart summaries — bullet-point key ideas extracted by Llama 3 via DigitalOcean Gradient AI
- Flashcards — auto-generated Q&A cards for active recall
- Quizzes — multiple-choice questions with instant grading
- Chat with notes — RAG-powered Q&A so students can ask anything about their material
- ELI10 explanations — any complex concept re-explained in plain language
How I Built It
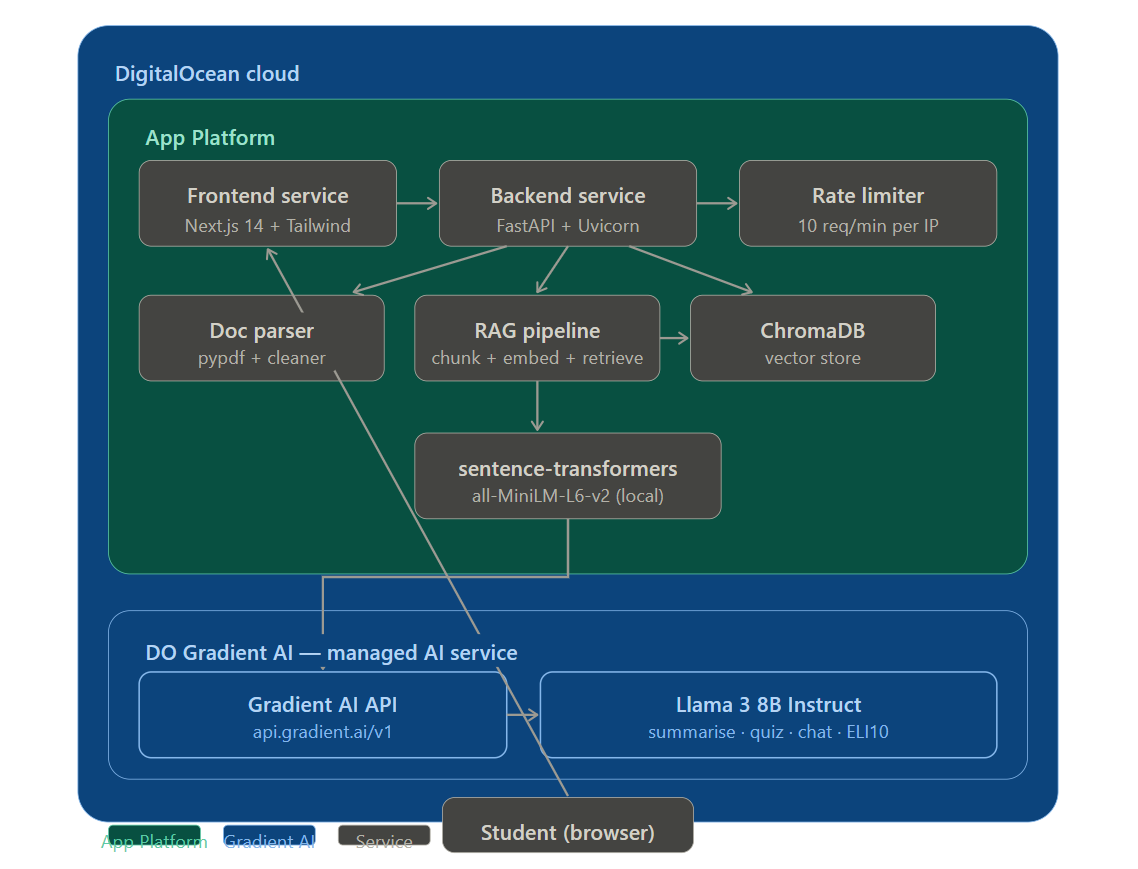
The stack is deliberately minimal and easy to run on DigitalOcean:
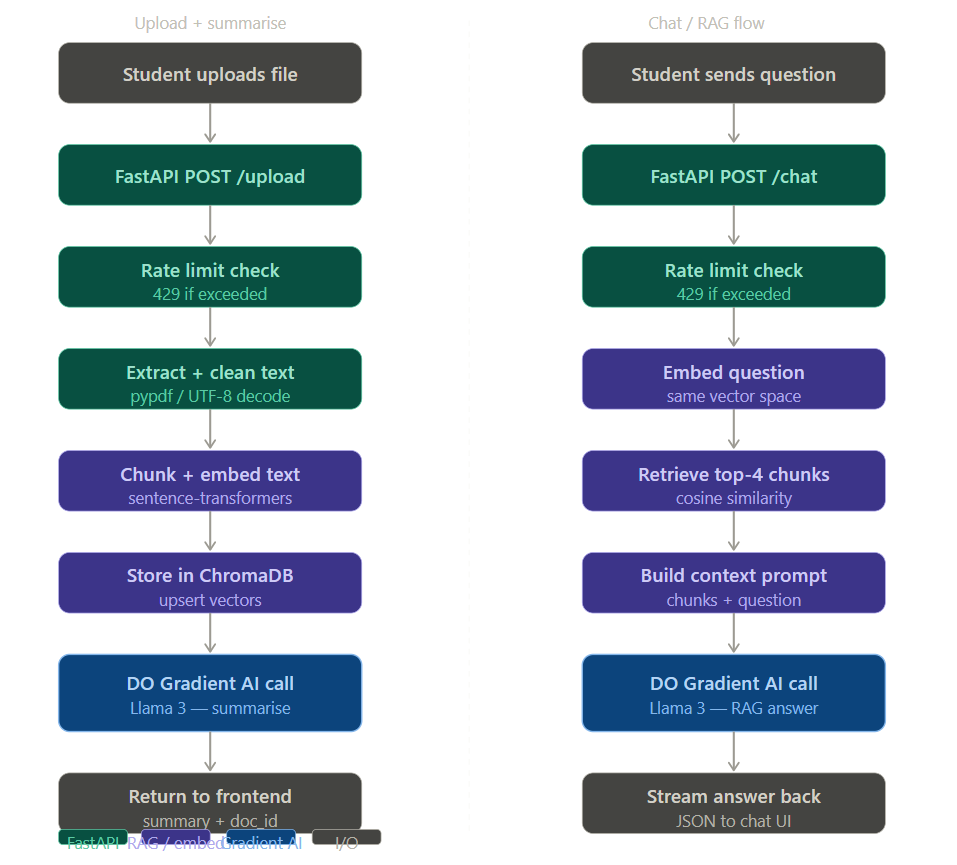
Backend — FastAPI (Python) handles file uploads, calls the DigitalOcean
Gradient AI API, manages embeddings, and enforces rate limiting. Text is
extracted from PDFs using pypdf, cleaned, and chunked. Embeddings are
generated locally using sentence-transformers (all-MiniLM-L6-v2) and
stored in ChromaDB for retrieval-augmented generation (RAG).
The RAG pipeline splits documents into overlapping character chunks of size (C = 400) with overlap (\delta = 80):
$$\text{chunks} = \left\lceil \frac{|D| - \delta}{C - \delta} \right\rceil$$
where (|D|) is document length. At query time, cosine similarity is used to retrieve the top (k = 4) most relevant chunks before passing them as context to the Gradient AI model.
Frontend — Next.js 14 with TailwindCSS. State is shared across pages via React Context so a document uploaded once is available everywhere. Features include flip-card animations, a live quiz grader, and a real-time chat interface.
AI — DigitalOcean Gradient AI (llama3-3b-instruct) via the
OpenAI-compatible /v1/chat/completions endpoint. All prompts are centralised
in ai_service.py for easy tuning. No extra SDK is needed — the integration
uses Python's built-in urllib, making the backend lightweight and
dependency-free on the AI layer.
Deployment — The FastAPI backend is deployed on DigitalOcean App Platform
with the DO_GRADIENT_API_KEY set as an environment variable. The Next.js
frontend is deployed as a separate App Platform component, with
NEXT_PUBLIC_API_URL pointed at the backend service URL.
Challenges I Faced
1. Parsing messy PDFs — Real-world PDFs have garbled text, weird encoding,
and blank pages. I built a clean_text() function to strip non-printable
characters, collapse whitespace, and validate that enough text was extracted
before calling the AI.
2. Rate limiting — To stay within responsible usage limits, I implemented a sliding-window rate limiter in FastAPI that tracks requests per IP and returns HTTP 429 with a friendly retry message rather than crashing. The frontend displays a clear "AI is busy" warning instead of a broken UI.
3. RAG accuracy — Early versions returned irrelevant chunks because chunks
were too large. Tuning chunk size and overlap significantly improved answer
quality, and running all-MiniLM-L6-v2 locally meant zero additional API cost
for embeddings.
4. Structured AI output — Getting Llama 3 via Gradient AI to return consistently parseable flashcard and quiz formats required careful prompt engineering with exact format templates and fallback parsers when the model deviated from the expected structure.
What I Learned
- How to build a full RAG pipeline from scratch using open-source tools
- Integrating DigitalOcean Gradient AI using its OpenAI-compatible REST API
- Prompt engineering for structured output from a generative model
- FastAPI middleware patterns for rate limiting and CORS
- How the Ebbinghaus forgetting curve maps directly to spaced repetition — which is exactly what flashcards implement
- Deploying a full-stack AI app on DigitalOcean App Platform end-to-end
Built With
- Next.js — Frontend framework
- TailwindCSS — Styling
- FastAPI — Backend API
- Python — Backend language
- DigitalOcean Gradient AI — AI model (Llama 3 8B Instruct)
- DigitalOcean App Platform — Deployment
- ChromaDB — Vector database for RAG
- sentence-transformers — Local embeddings (
all-MiniLM-L6-v2) - pypdf — PDF text extraction
- Uvicorn — ASGI server
Built With
- chromadb
- fastapi
- google-gemini-api
- next.js
- pypdf
- python
- sentence-transformers
- tailwindcss
- uvicorn

Log in or sign up for Devpost to join the conversation.