Inspiration
Reading through large sections of a textbook can often be tedious and time-consuming, and extracting concise and encompassing contents of a section for note taking is even worse. We wanted to create an application that made note taking a more pleasant and efficient process. Textbooks can contain information that you don’t necessarily need and it can be a huge waste of time when trying to study.
What it does
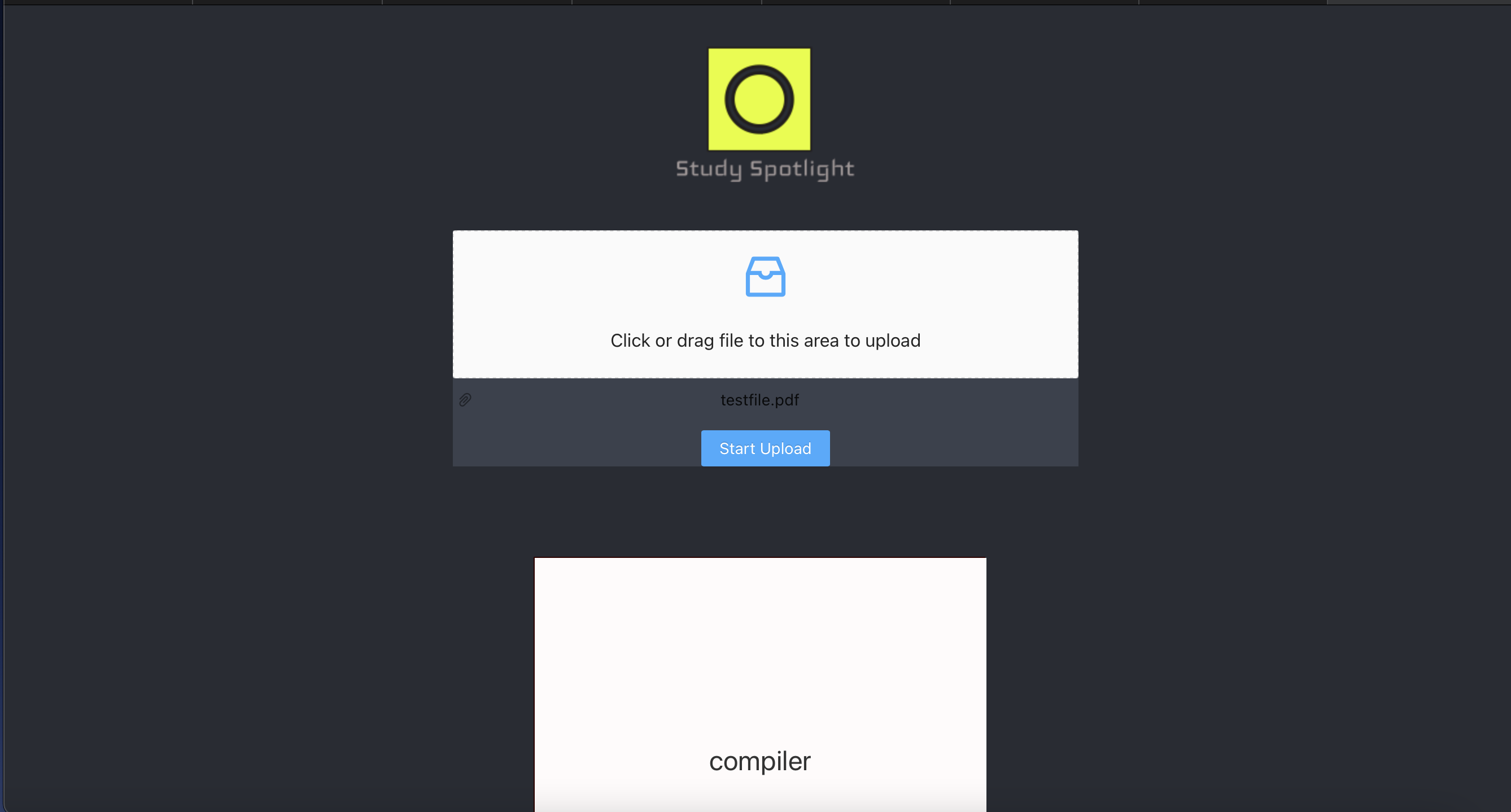
Our application takes the PDFs of textbooks and converts them into notecards that are easy to use. Specifically, it extracts key definitions from a select passage and turns them into digestible notecards. This will allow students to get the most important information from textbooks without having to read through the whole thing. This not only saves time but also makes it a convenient tool to make flashcards that are made quickly.
How we built it
We used Google Cloud Vision API to convert the uploaded PDF into raw text, and then passed that text to our AutoML Natural Language to extract the terms and definitions. The AutoML and Vision API code was hosted on a backend Firebase. We implemented the frontend using React and used Ant Design to make our website look nice.
Challenges we ran into
By far our biggest challenge we faced was training the neural network. We were unable to find a dataset that matched the problem we were trying to solve, and we had to manually create our own datasets using textbooks from our previous classes. Further, though AutoML is extremely convenient and easy to use, the Entity Extraction model didn’t exactly fit what we were trying to accomplish, so we had to make many adjustments as we were training the neural network. Further, it was our first time using Google’s Firebase platform, so setting up the backend code for that also proved to have its challenges.
Accomplishments that we're proud of
We are proud of being able to deploy our first ML model as well as a Firebase backend that holds our application together. We are also proud of digestible and easy to use interfaces with flashcards as well as a progress bar that shows the user the full process of converting the PDF into text and extracting the definitions from the text.
What we learned
For some of us, this was our first time doing web development so it was a learning experience using the React framework to develop a frontend. We were able to figure out how to implement interactive components like flashcards and progress checking on upload and term scanning in real time.
What's next for Study Spotlight
Though our neural network was serviceable, we plan to retrain our network through Tensorflow to increase accuracy and customizability. We’d also like to support multiple file uploads as well as allowing users to upload only a portion of a textbook PDF as opposed to having to manually resave a section of a desired PDF. Finally, a google extension that highlighted terms and definitions in a browser is something we would like to accomplish in the future as well.

Log in or sign up for Devpost to join the conversation.