-
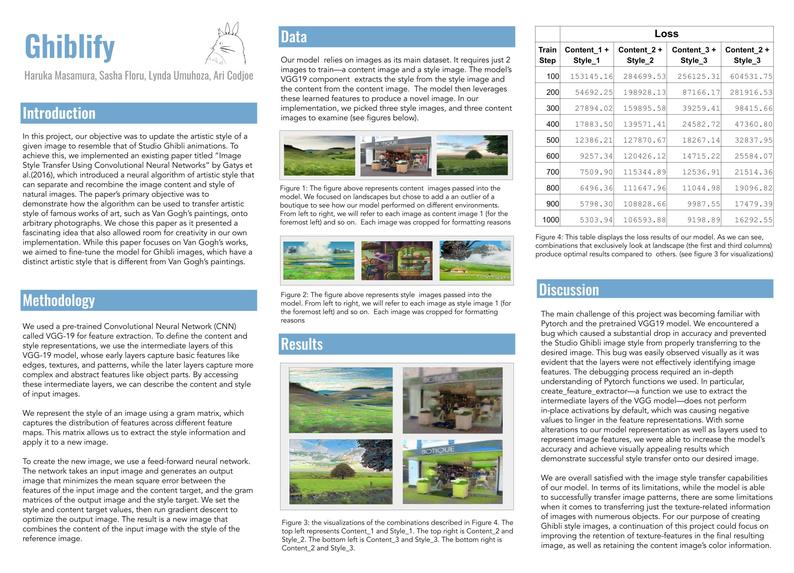
Ghiblify poster
Ghibli Image Style Transfer
Other reflections are linked in updates.
Team:
- Ariana Codjoe : acodjoe
- Lynda Winnie Umuhoza : lumuhoza
- Haruka Masamura: hmasamur
- Alexandra (Sasha) Floru: afloru1
Introduction
Given an image, we will update the image’s artistic style to resemble that of Studio Ghibli Animations
Inspired by "Image Style Transfer Using Convolutional Neural Networks"
The paper’s objective is to introduce a Neural Algorithm of Artistic Style that can ‘separate and recombine the image content and style of natural images.’ Using this algorithm, which allows us to combine the content of an arbitrary photograph with the appearance of well-known artworks, the paper discusses the implementation of a model that transfers the artistic style of Van Gough’s works onto given images. We chose this paper because the idea was very interesting, and its descriptions of its algorithm seemed rather comprehensive. It also focuses on Van Gough, which gives us room to not just implement the paper as is, but fine-tune the model for Ghibli images, which are very different in style from Van Gough’s paintings.
We determined that this problem falls under the unsupervised learning category.
Related Work:
Public implementations
- https://www.tensorflow.org/tutorials/generative/style_transfer
- https://paperswithcode.com/task/style-transfer
- https://anderfernandez.com/en/blog/how-to-code-neural-style-transfer-in-python/
Related Article: https://medium.com/swlh/image-style-transfer-using-deep-neural-network-21f62f9066ac based on CNNs
In this blog, the authors briefly describe image style transfer. One must separate the content of an image with the style that it is painted in. With this preprocessed data, the author leverages convolutional neural networks to learn patterns within the style and apply them to the content of other images (i.e the cat in the oceanic style). Because our task is twofold, the article also urges having two loss metrics: one representing continent loss and one representing style loss.
Data
For image style transfer, only 2 images are needed at a time to train the model. For preprocessing, we would need to crop the images to be of around the same size with a max dimension length and normalize them in the same way as ImageNet.
Methodology
The paper uses a pre-trained CNN for feature extraction––particularly VGG-19. This generative network is a feed-forward neural network that takes as input an image and produces an output image that preserves the content of the input image while adopting the style of the style image. The network will be composed of several layers of convolutional, pooling, and upsampling layers, with activation functions.
The architecture may look as below:
Input layer: takes in either the content image or the style image
4-5 convolutional layers: These layers are used to extract features from the input image. In the paper, the VGG-19 network is used as the feature extraction network, but we may adjust how many conv layers utilize the VGG-19 network
ReLU activation layers
Pooling layers in between conv layers
Output layer: outputs the stylized version of the content image
If you are implementing an existing paper, detail what you think will be the hardest part about implementing the model here. I think the hardest part will be figuring out how the feature extraction will look––how many conv layers with VGG-19 will be sufficient? How can we tailor it to animation-like images from Ghibli?
Metrics
Success will be determined by the model’s ability to produce visually desirable outcomes that match the criteria for resembling Studio Ghibli animations. To measure this, we intend to train on images from various Ghibli scenes and see what hyperparameters work best for our purposes.
Because we are using unsupervised learning, it is a bit difficult to compute accuracy in the same manner that we have been doing in class. Instead, we plan to leverage clustering concepts and dimensionality reduction to computer similarity from both a content and style perspective.
In the paper, the authors compiled a Loss metric in which they used “ element-wise mean squared difference between” a representation of style and the representation of style when white noise is applied to the image (a parallel process occurs for image content as well). With this loss metric, the author was able to contextualize their results. We would ideally replicate a similar process for our model as well.
Our Goals
- Stretch : our network applies to novel images with high accuracy
- Target : our network is able to learn on basic data (i.e landscape)
- Base : we are able to learn content and style as distinct entities (with different representations)
Ethics
Why is Deep Learning a good approach to this problem?
Deep learning is a good approach to this problem because it allows us to extract high-level image features. Deep learning algorithms can also be leveraged to recognize image contents and style which can be useful for transferring one image’s style to another.
Measure of error/success
Success will be determined by the model’s ability to produce visually desirable outcomes that match the criteria for resembling Studio Ghibli animations.
We hope to conduct subjective evaluations where human evaluators rate the generated images based on their visual similarities to Studio Ghibli animations. This will provide us with qualitative feedback and insights into how well the model is able to achieve the desired artistic style.
The implications of the chosen quantification approach have ethical considerations. The artistic style is subjective and can vary depending on individual preferences and cultural context. The chosen criteria for success may not be universally applicable or representative of all perspectives. We will consider a diverse range of evaluators and their feedback to avoid bias and ensure a more comprehensive assessment of the model’s success.
Division of labor
Ariana Codjoe - Preprocessing, Evaluation Lynda Winnie Umuhoza - Preprocessing, Evaluation Haruka Masamura - Architecture, Training Alexandra Floru - Architecture, Training


{kind=link}
Log in or sign up for Devpost to join the conversation.