-
-
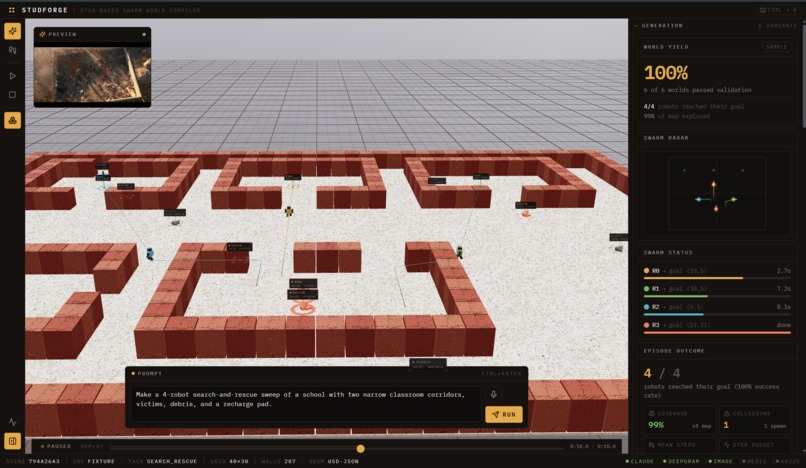
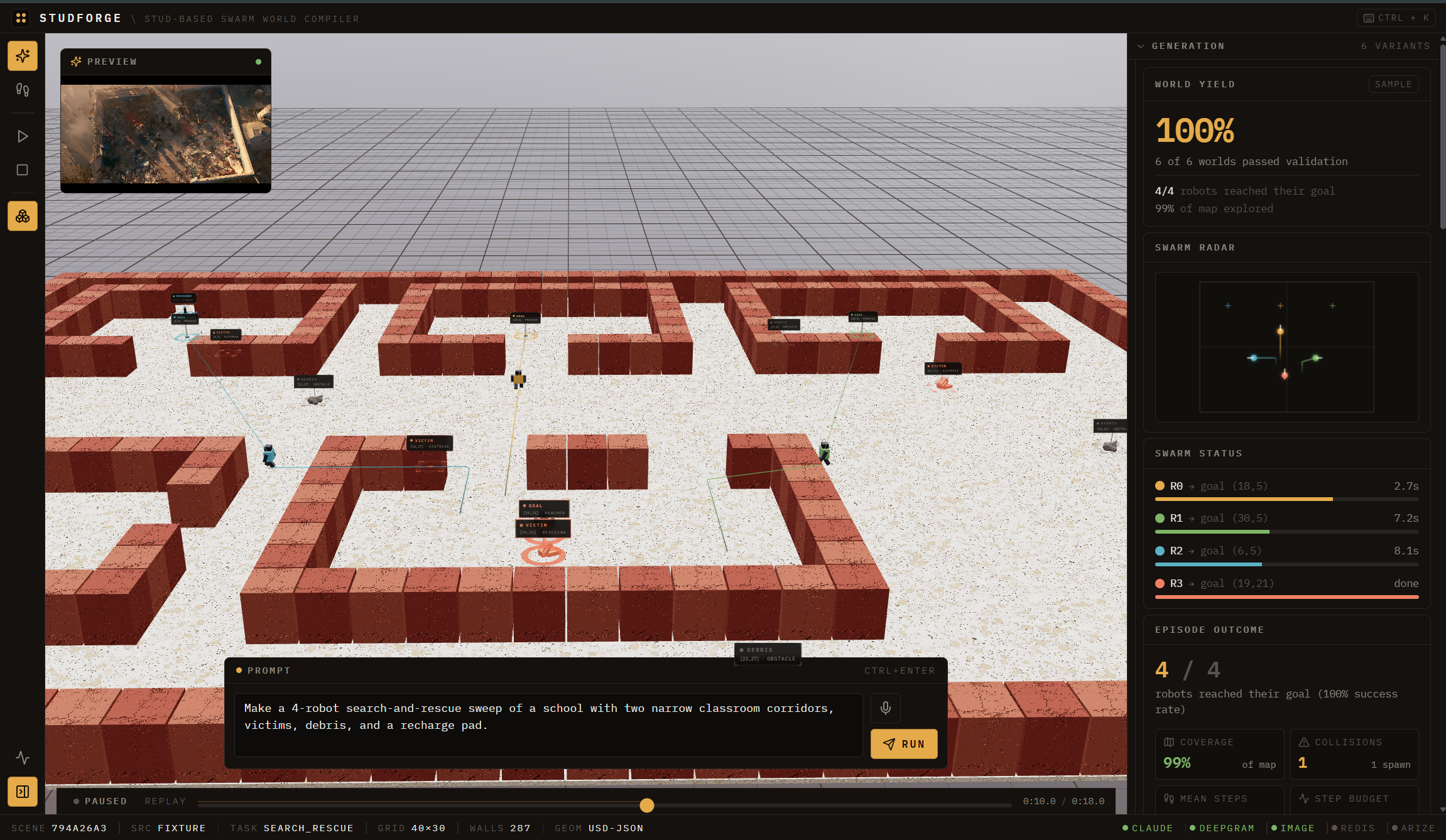
Generated Environment
-
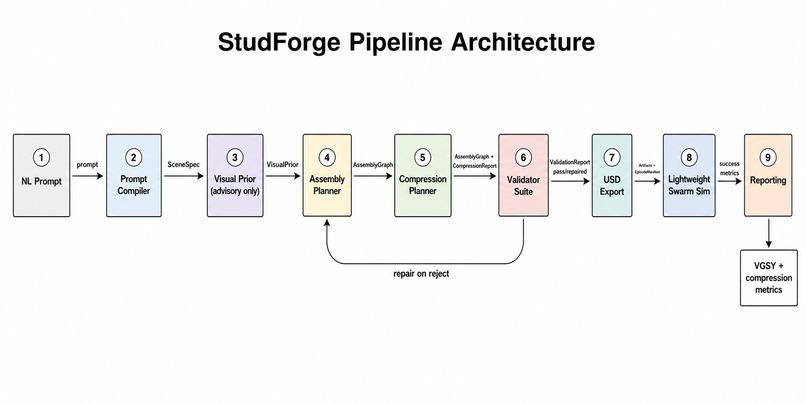
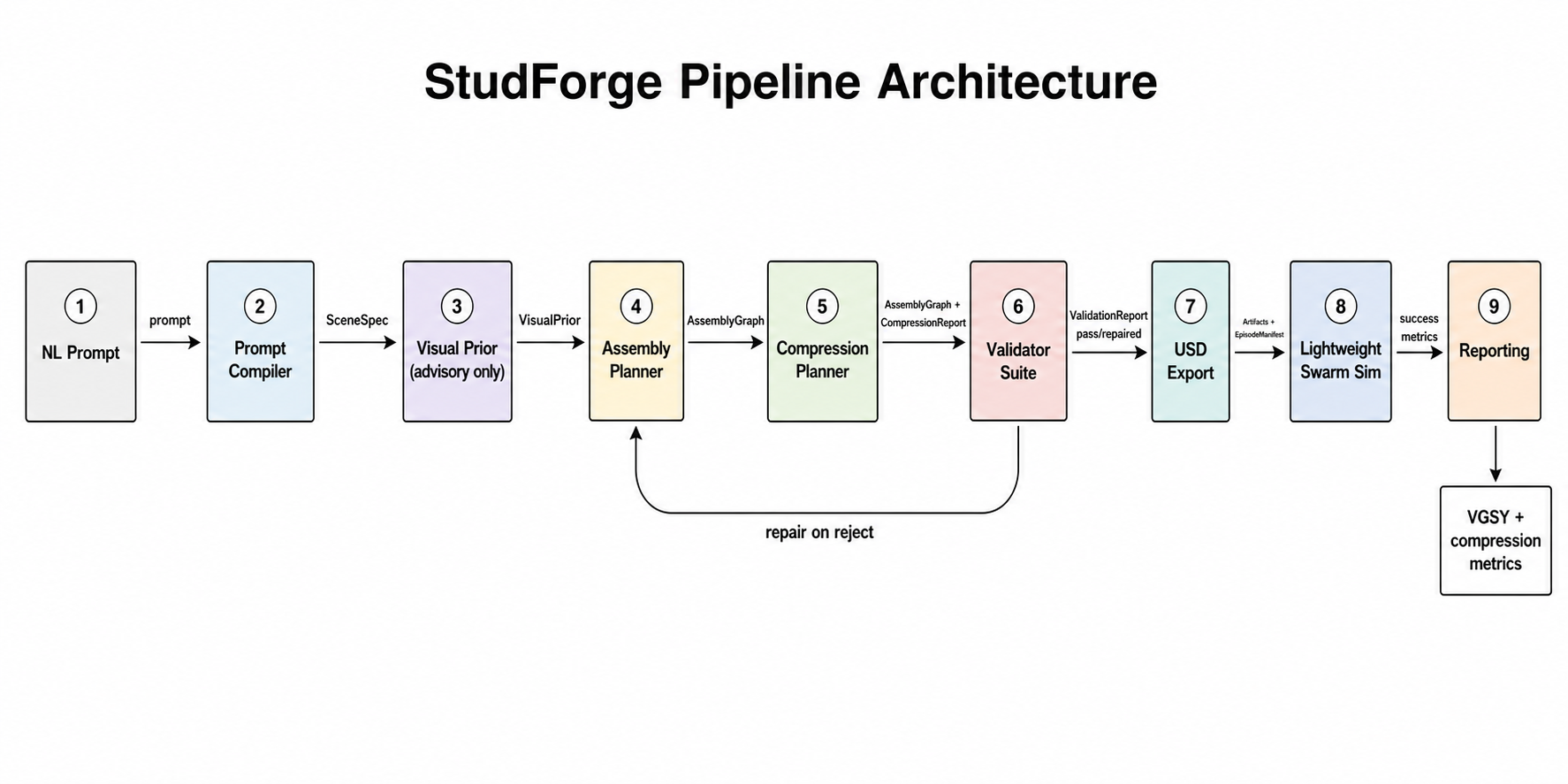
Pipeline architecture
Inspiration
Three of us grew up building with LEGO before we ever wrote a line of code, and it turns out stud-based bricks are a surprisingly good metaphor for how robotics simulation should work: small, validated, snap-together units that compose into something physically real. The problem is that building a multi-robot sim scene today (a warehouse, a search-and-rescue maze, a swarm-coordination test) usually means hand-placing geometry or trusting a generative model to hallucinate a "plausible" environment — with no guarantee the result is collision-free, connected, or even physically assemblable.
What it does
StudForge turns a plain-English prompt (both voice and text) — "a 4-robot search-and-rescue maze with two narrow corridors, victims, debris, and a recharge pad" — into a fully validated, exportable multi-robot training environment, end to end.
The system compiles a user prompt into a typed SceneSpec using Claude with schema-constrained generation, optionally accepting voice prompts through Deepgram’s nova-3 live transcription. It renders an advisory visual prior with Midjourney via its MCP server so designers can preview the scene before committing geometry, but the image only softly nudges wall placement and can never bypass validation. From there, the platform assembles and compresses the scene into stud-based brick geometry using deterministic and learned compression planners, including a Qwen model path, while gating every proposal through the same validator suite as the deterministic baseline. It validates connectivity, collision-freedom, and coverage, repairing and rechecking until the scene is sound rather than merely plausible. The system then exports a canonical USD representation, with SDF, URDF, and MJCF as downstream exports, and runs a lightweight swarm simulation with a real multi-robot team plan. During each episode, three observer agents for coverage, coordination, and collision write findings to a Redis-backed agent-memory service, then recall only bounded, validator-gated bias into the next generation, letting the system improve its training environments over time without allowing memory agents to write geometry directly. Finally, it reports the full lineage of every decision, including compiler output, compression report, validation report, and swarm metrics, as both JSON and an HTML report.
How we built it
The core is a Python backend built around Pydantic v2 contracts that define the exact I/O of every pipeline stage.
For the agent layer, we used Claude to generate per-robot configs and a runnable scripted policy from the compiled EpisodeManifest, with a learned-policy slot wired in. The three observer agents persist their findings through a shared memory store with strict Redis Cloud selection.
For compression, we trained and benchmarked deterministic strategies (unit, strips, greedy, exact) as a validator-gated floor, and wired a learned/hybrid path that runs inference against a Qwen 2.5 model.
Challenges we ran into
- Letting Claude/Midjourney/Deepgram advise without letting them author. The hardest design constraint was making three different generative integrations strictly advisory. We initially hoped to create scene reconstructions out of Midjourney generations but quickly realized the model was too probabilistic to paint reliably consistent scene graphs. It would have been much faster to let the visual prior or the compiler "just place the bricks," but that breaks the validation guarantee the whole project is built on — we spent real time engineering the boundary so creativity stays upstream of correctness.
- Voice latency vs. correctness. Wiring the Deepgram WebSocket relay so transcripts land cleanly in the same compiler path as typed prompts — including recording input modality and STT model in provenance — took more debugging than expected, especially keeping the typed-text fallback fully intact when no API key is set.
- Trainium Pivot Our original idea used a fine-tuned compression model to convert high-fidelity USD assets into more functional blocks, yet around 9pm the trainium instance we had been working with shut down, forcing us to completely restart and train a Qwen2.5-1.5B model on a smaller EC2 instance with LoRA.
Accomplishments that we're proud of
We're proud that the entire pipeline runs cleanly and produces a schema-valid scene, a zero-coverage-error compression report, a connected single-component layout, and a full observer report from all three agents. Layered on top of that honest baseline, we got Claude-driven compilation, Midjourney visual priors, Deepgram live voice input, and Redis-backed agent memory all genuinely wired into the same validated path. Getting four sponsor integrations to coexist behind one settings module, with health reporting on all nine, is the part we're most proud of engineering-wise.
What we learned
We learned that validation is gold in compiler structure. Every time we added a new model in the loop — Claude, Midjourney, Deepgram, the Qwen-based compression path — the temptation was to let it shortcut the validator. Building the advisory boundary first, and writing tests that assert validators run regardless of which backend produced the input, is what let us add four different model integrations without the system's core guarantee ever weakening. We also learned that strict failure modes (Redis, in particular) are a feature for systems that claim to demonstrate agent memory, not a bug to be smoothed over.
What's next for StudForge
- Finish the scene playback endpoint so the frontend can animate generated robot trajectories live instead of falling back to a static view.
- Train the learned robot-agent policy now that the compressed scene landscape gives us a real distribution to train against. We can now scale beyond search-and-rescue, exploring warehouse workers, assembly lines, and more.
- Move from JSON USD stand-ins to real OpenUSD export, and connect the swarm sim to higher-fidelity backends (Isaac, MuJoCo, BenchMARL) for sim-to-real staging.



Log in or sign up for Devpost to join the conversation.