-
-

Revision notes generator
-

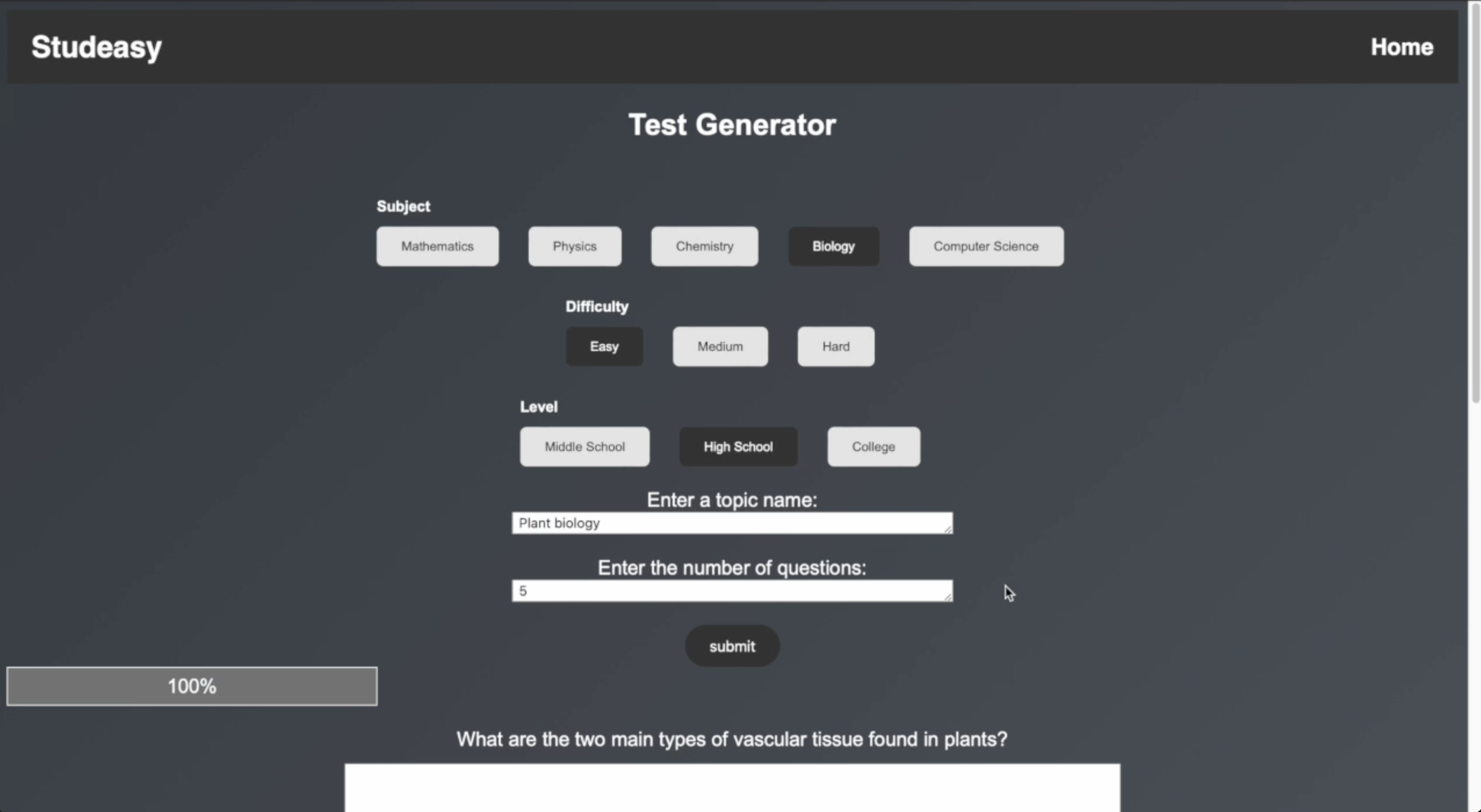
Test generator
-

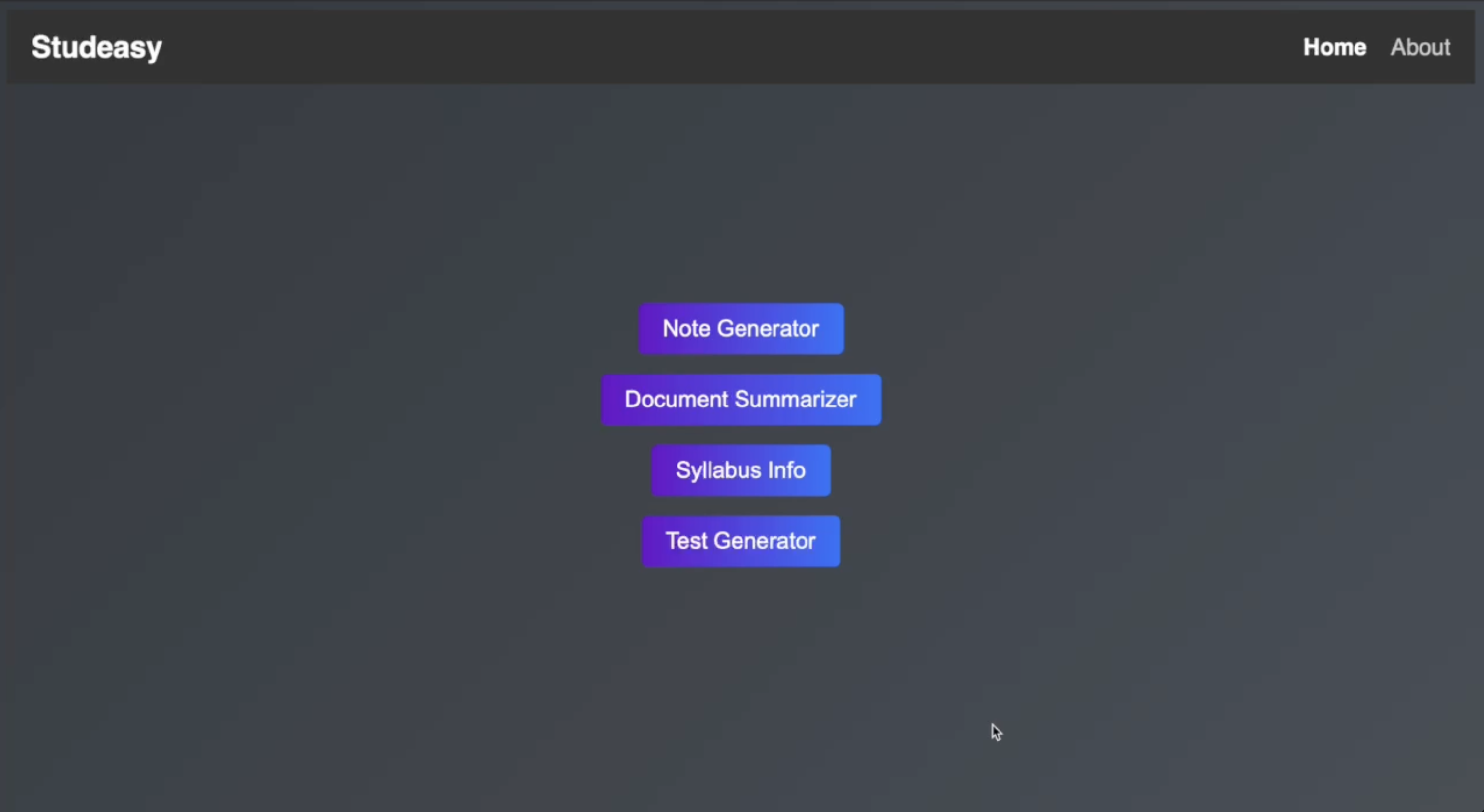
Home screen
-

Document summary generator and output
-

Syllabus information extractor and output
-

Test feedback
-

Revision notes generator output





Inspiration
Everyone knows students are lazy, but have we ever stopped to ask why? When analyzing our own study patterns, we realized that the biggest reason for our procrastination was not work, but the fact each task involved so much boilerplate work. Tasks as simple as looking for information in a textbook involved sorting through so much unnecessary text. Constructing three pages of revision notes for a test meant reading through 200 pages of a textbook. That is the problem we set out to solve. Removing the grunt work so that students can focus on what matter the most.
What it does
Our project provides a suite of functionality for students, allowing them to greatly increase the rate at which they absorb information by removing the repetitive tasks from their routine. Some of our functionalities include:
- A revision notes generator that can generate quick revision notes based on a given topic and level of comprehension.
- A test generator that generates questions based on subject, level of comprehension (high school, college, middle school), and difficulty. It then allows users to enter their own answers and grades their answers out of 100, also providing feedback.
- A document summarizer that can read entire documents like textbooks and research papers within seconds and output a summary of a desired section.
- A syllabus information extracter that extracts commonly required information such as assignment weightages, office hours, regrade and late submission policies, etc. ## How we built it A tool that has taken the world by storm is ChatGPT, but it's limitations include the fact that it does not have access to information past 2019, which does not make it very useful for analyzing newer pieces of data.
We used an API to the GPT 3.5 language model by OpenAI to complete the above tasks, engineering our input prompts so that the output is concise and accurate and matches the user's specifications. We also used clustering algorithms to identify where in the document desired keywords appear and identify the sections of relevant information.
Challenges we ran into
The biggest problem is that any language model has a limited number of parameters and therefore a limited memory, so it is not feasible to directly input a 300 page document into a language model. Moreover, the OpenAI API limits our inputs to be under approximately 3000 words, so we had to develop an algorithm that was able to identify and feed only the relevant text into the language model.
Accomplishments that we're proud of
- Creating a fully interactive website using Flask and Python
- Optimizing our inputs with the use of clustering
- Successfully engineering prompts to get acceptable outputs
- Creating a viable solution to a relatable, everyday problem
What we learned
- We learned that using CSS and HTML templates is a good way to save time when making a website for a hackathon.
- We learned that training our own models is infeasible and using APIs is the best option.
- We learned to come up with ideas a few days prior to the hackathon, which gives us time for planning before we actually begin writing code.
What's next for Studeasy
- Creating more features that would streamline the daily studying process for students.
- Optimising our methods to minimize API calls
- Adding user authentication and saving user data






Log in or sign up for Devpost to join the conversation.