-
-

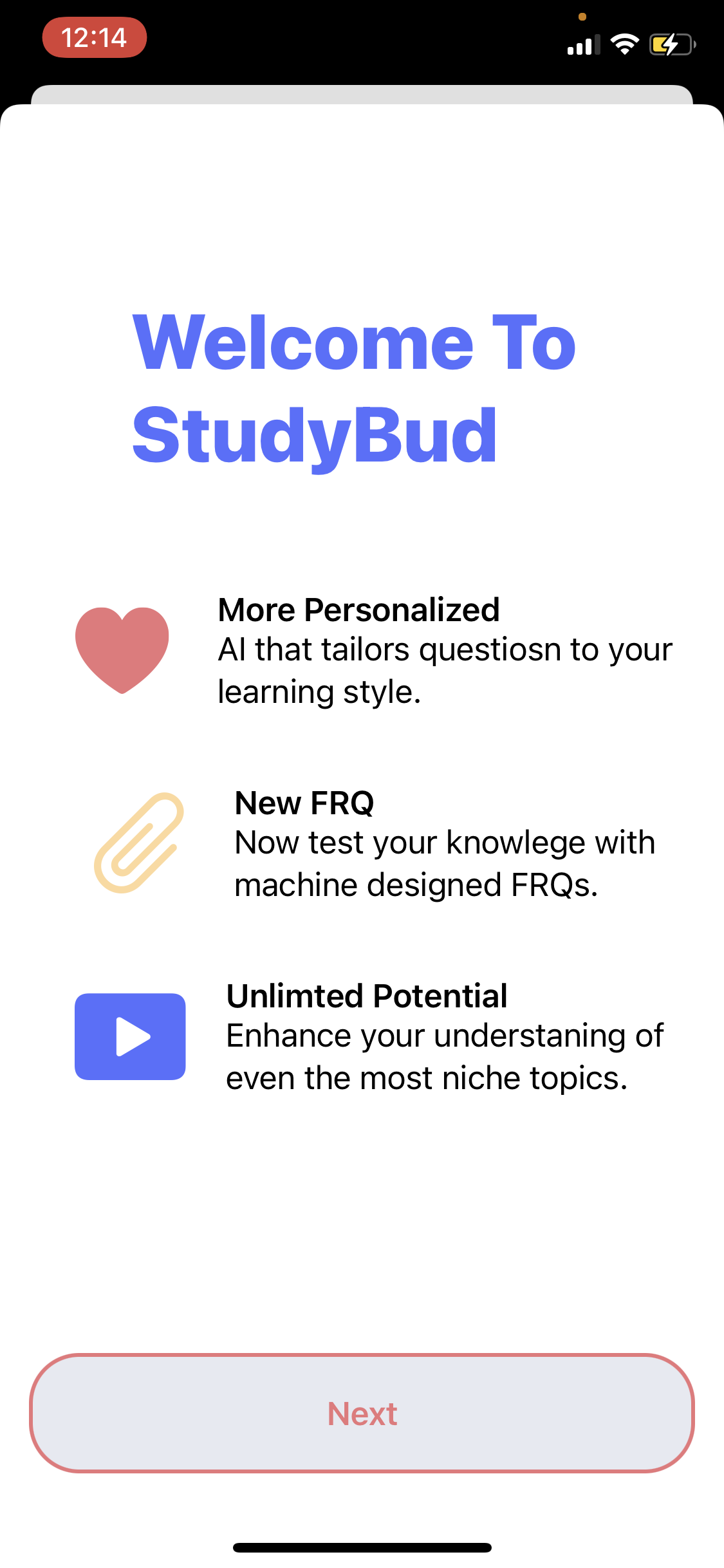
The onboarding screen for the app
-

A home page when a user uses the app for the first time
-
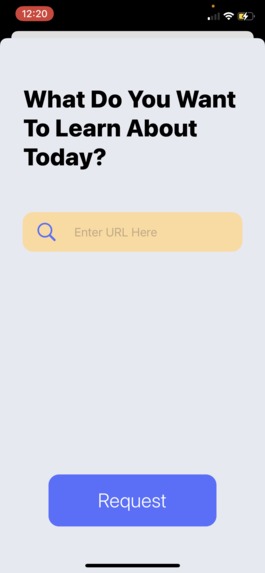
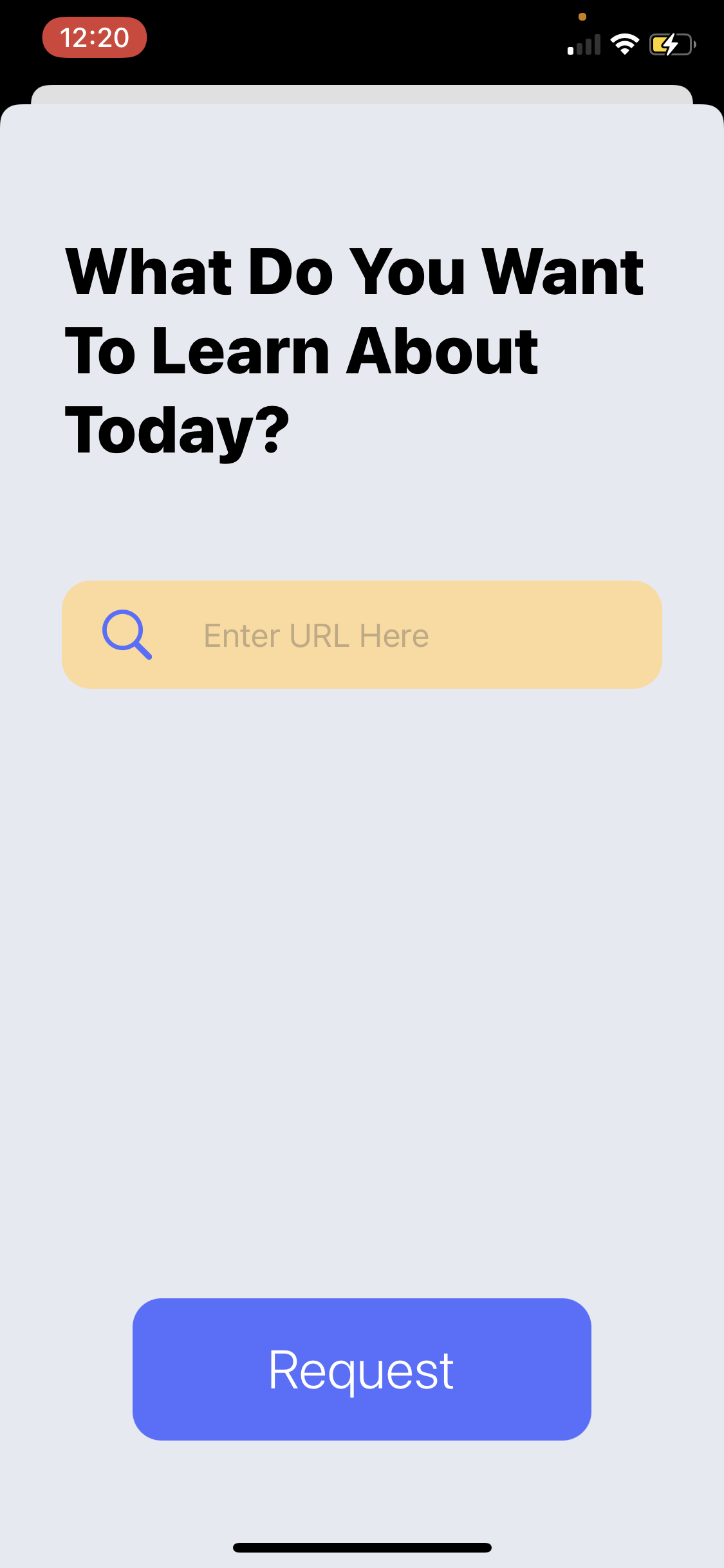
The sheet to add a new set from any website
-
The home page with one custom set added
-

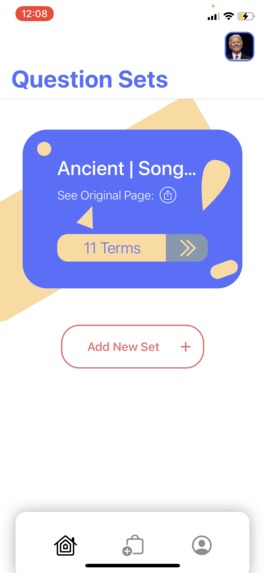
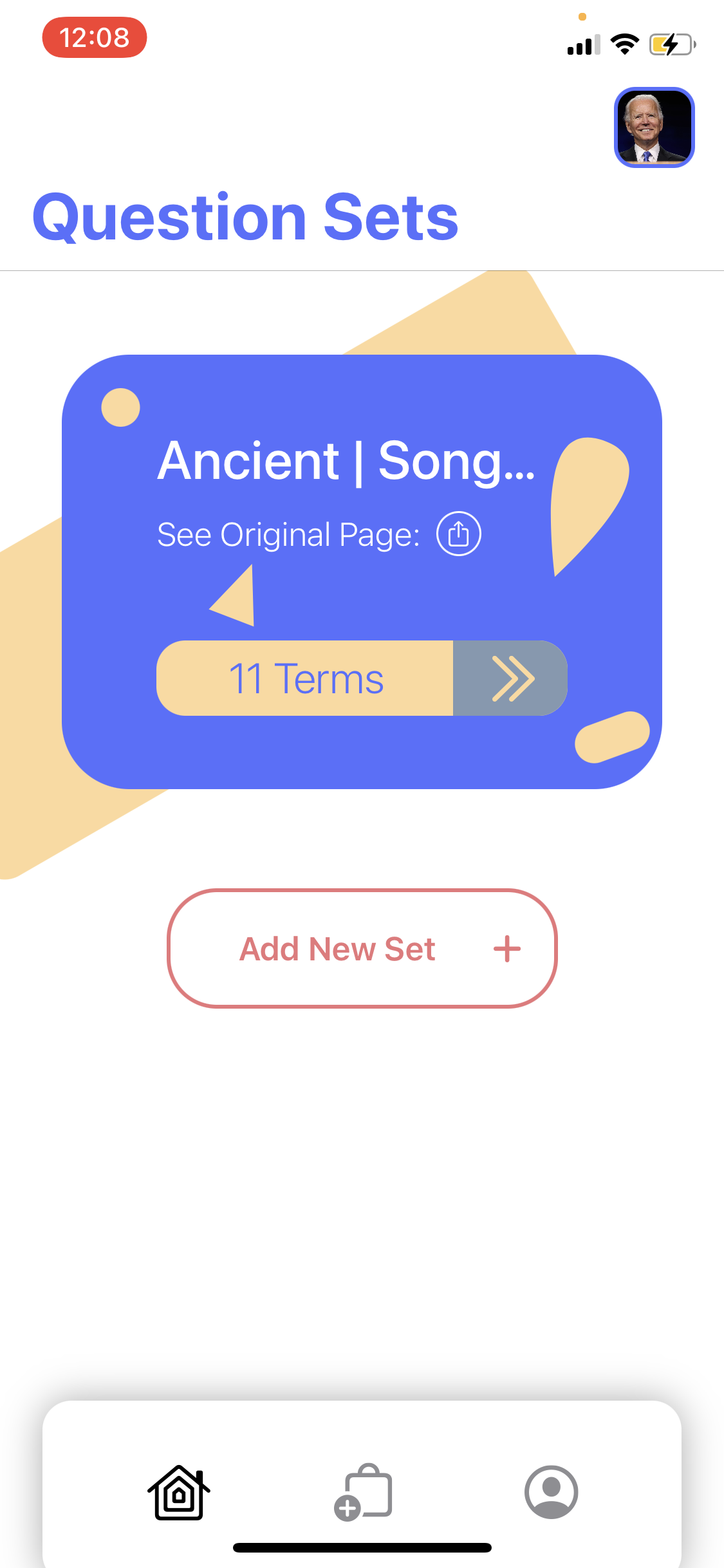
The set detail page showing more info about one set
-
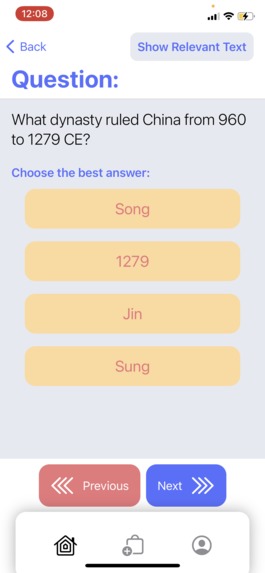
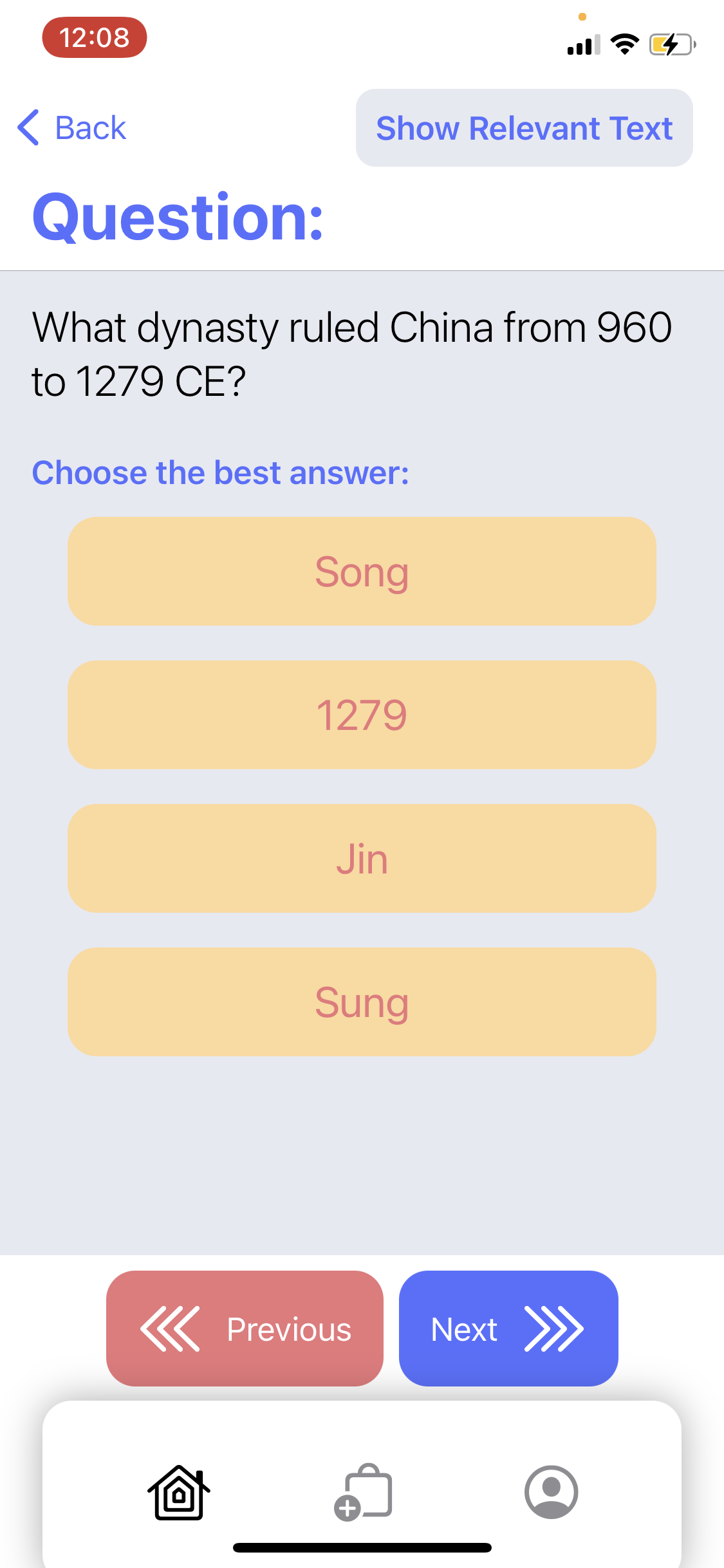
A multiple choice question in the quiz
-
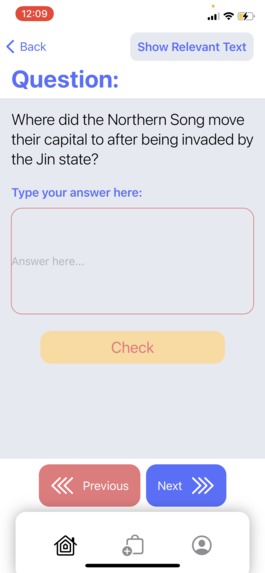
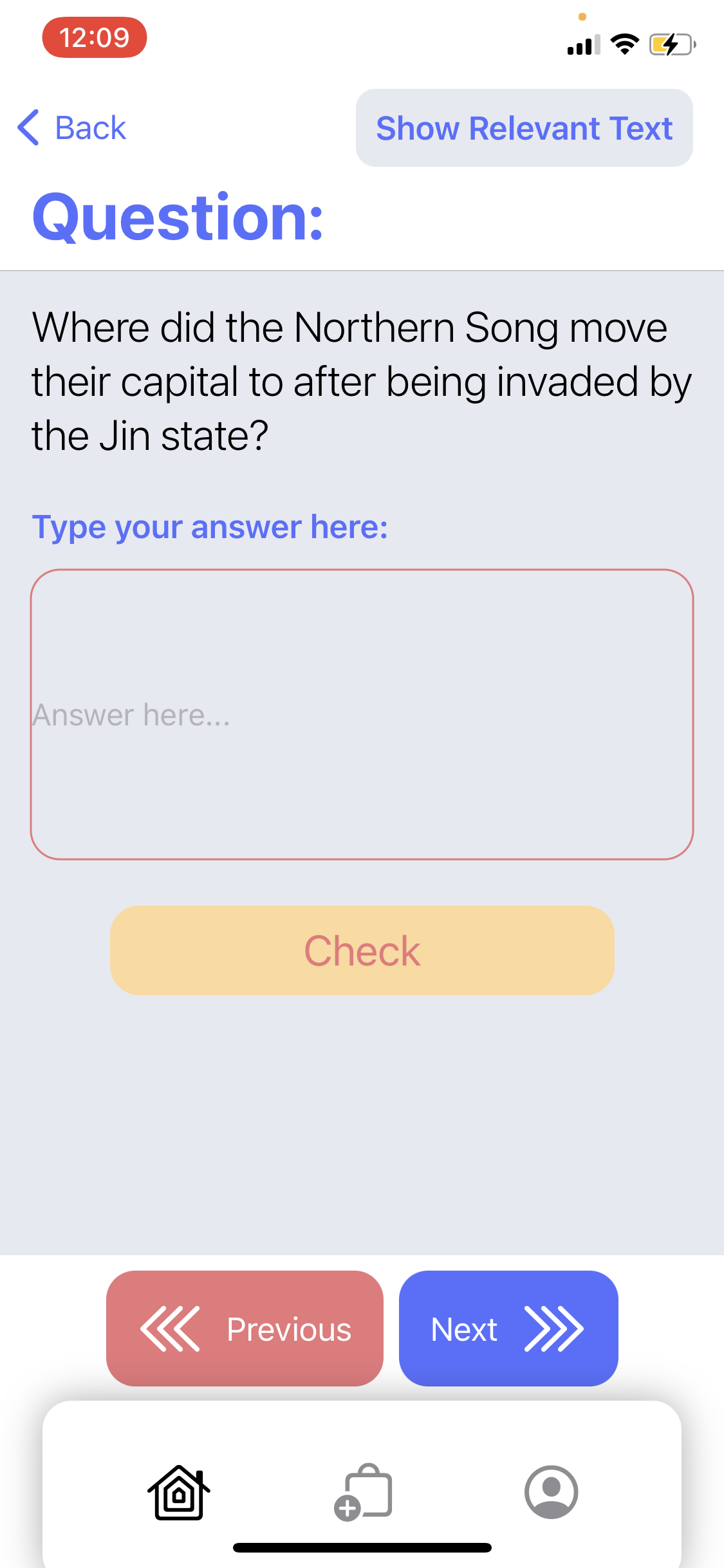
A free response question in the quiz
-

The summary page for the quiz
-
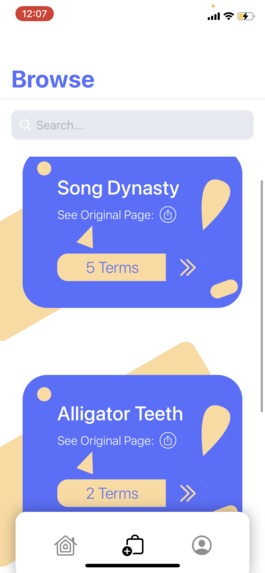
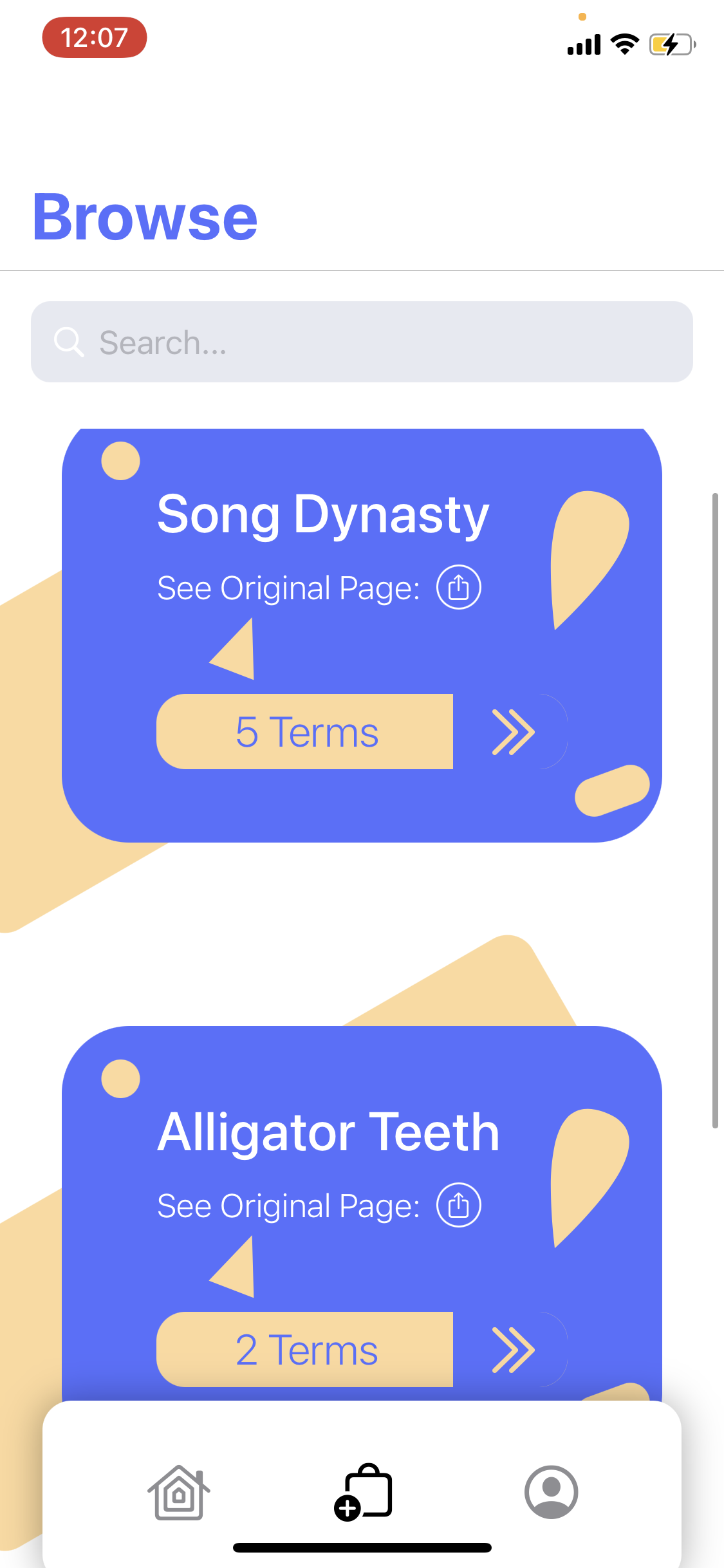
The browse page where the user can see sets from other users



Inspiration
Because of the pandemic, many people are either attending school from home or working from home. Through this, many people have a lot more time on their hands to spend on their passions. Self-learning is more popular than ever, and we designed this app to supplement it. It’s trivial to read stuff on the internet, but it’s well-known that quizzing yourself helps with comprehension.
What it does
Our app can receive a webpage link and use natural language models to automatically generate questions and answers for you, letting you seamlessly transition from reading content to testing your comprehension.
Accessibility
We designed our app with SwiftUI which is the latest Apple UI framework and fully integrates with iOS's accessibility features. For this reason, our app works flawlessly with VoiceOver, keyboard input and alternative device input. Visual cues are available if the user activates them in their iOS accessibility settings. Although not all our icons have text next to them, VoiceOver will read to the user what it is when they tap on it. Unfortunately, our coloring for when a user gets an answer correct or incorrect doesn't have a non-color option so for people who are colorblind in a particular way aren't properly supported. Font size changes and invert colors are also supported.
How we built it
We started off by designing what the UI should look like [1]. This helped us distribute the work evenly while not causing merge conflicts on our GitHub repo. After figuring out exactly how a user interacts with the app, we created our API specification [2], which detailed how the client app and server would communicate. That way, we could work on each portion separately without worrying about compatibility as long as everyone followed that “contract”. Both of these documents are linked at the bottom of this post, if you’d like to check them out!
Saaketh and Arpan wrote the frontend iOS app using Swift and SwiftUI (and a little UIKit for where SwiftUI wasn’t sufficient). The networking was done using Apple’s Combine framework to allow for REST API requests and WebSocket connections.
Vivek used Python for all of the backend code, Fast-API for the server endpoints, RabbitMQ for task queues, Celery to delegate tasks to workers, and PyTorch for the final language models. Vivek was also able to use latent semantic analysis using BERT to check FRQ answers for students by comparing the semantic meaning of the texts provided. This was Deepa's first hackathon, and she helped with getting the Redis database, RabbitMQ server and Celery up and running. She also helped in building the FastAPI endpoints.
When a request is sent to the server, the designated webpage is scraped and the text is extracted. The document is broken up into chunks, and questions are generated for each chunk of text. We utilize Huggingface Transformer models (trained on the SQuAD dataset) to both generate questions and sort the generated questions by the question-answer pair’s plausibility. Only the most relevant and plausible questions are returned to the user. To generate multiple-choice questions, additional steps are required. If the answer to the question is a proper noun or named entity, other named entities are extracted from the document and used to generate multiple-choice options. If the answer to the question is not a named entity, key sentences are extracted from around relevant answers and paraphrased until the answer choices are semantically similar, but not the same.
Challenges we ran into
We had challenges on the frontend and backend, but arguably the most influential one was that we couldn’t use a simple REST GET request to ask for questions on an article. This is because the time it takes to generate questions is too long and we didn’t want to have an HTTP request open for an extended period of time in case the client got disconnected. For this reason, we used WebSockets to request and receive completed jobs from the server.
None of us are UI designers so we had to spend a lot of time making the UI look bearable. Roughly half the time spent writing the iOS app was spent on making it look good. We never expected it to take this long, even from our prior experience.
Finding a decent language model is super difficult for question answering. In the end, after Vivek tested several models, he took a Frankenstein approach and combined Google’s state-of-the-art BERT model with Facebook’s question-answer model. He did this by substituting the “backbone” of Facebook’s model with Google’s more performant version.
After realizing how long it took to generate some questions Vivek decided to use RabbitMQ + Celery to create a scalable worker-based backend that allowed any language model worker to take jobs off the input queue and push them to the output queue when they were done. This would help prevent requests from piling up too quickly, allowing the server to handle more requests at once
Generating distractors for multiple-choice questions was extremely tricky. I ended up using named entity extraction to help generate relevant options, but there is still quite a lot of room for improvement.
Getting all the worker components to cooperate properly was a nightmare.
What we learned
Vivek - I learned a lot about language models, especially in the context of their semantic understanding of a piece of text. Despite a lot of code not making it into the final pipeline, the process of iterating and brainstorming was really helpful and enjoyable. I also learned about trying to build scalable computing systems while researching and building the distributed worker model.
Saaketh - I learned more about how swiftui structures its elements, enabling me to create a better UI. I also learned multiple new elements in SwiftUI, such as setting up a search system, TabViews, NavigationViews, and hashable objects.
Arpan - I learned how to create fault-tolerant WebSocket code so that in case of any intentional or accidental disconnect from the server, the client will reconnect when it can and reset the state so the server knows which client to send the completed questions to.
Deepa - I learned a lot about API design, and this was the first time I used many different technologies like Redis and RaabbitMQ (it took a surprising amount of time to make everything work together, and make it accessible from outside IP addresses). I had a great time :). My brother helped walk me through it.
What's next for StuddyBud
We hope to continue developing StuddyBud by increasing the accessibility of the browse feature by adding more divisions based on categories, popularity, etc. We also hope to develop a more effective and in-depth user system to hopefully allow us to port this app to more platforms like web and android.
References
[1] UI Plans - https://docs.google.com/presentation/d/1_tz3LzdJQEGUbMRIyzv6va2gdDCB13mKgp05X4gIliE/edit#slide=id.p
[2] API Specification - https://docs.google.com/document/d/13EkzglvLAaN3NsgXrnjzJ9rXtKbIYluvvR9Nyo-4cJ0/edit


Log in or sign up for Devpost to join the conversation.