-
-
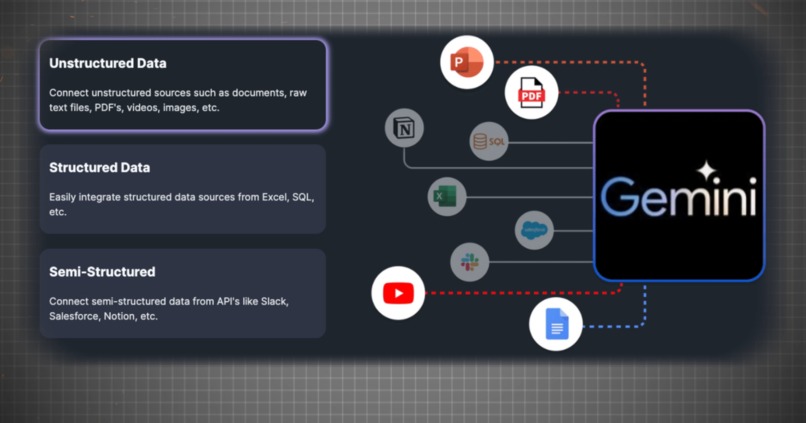
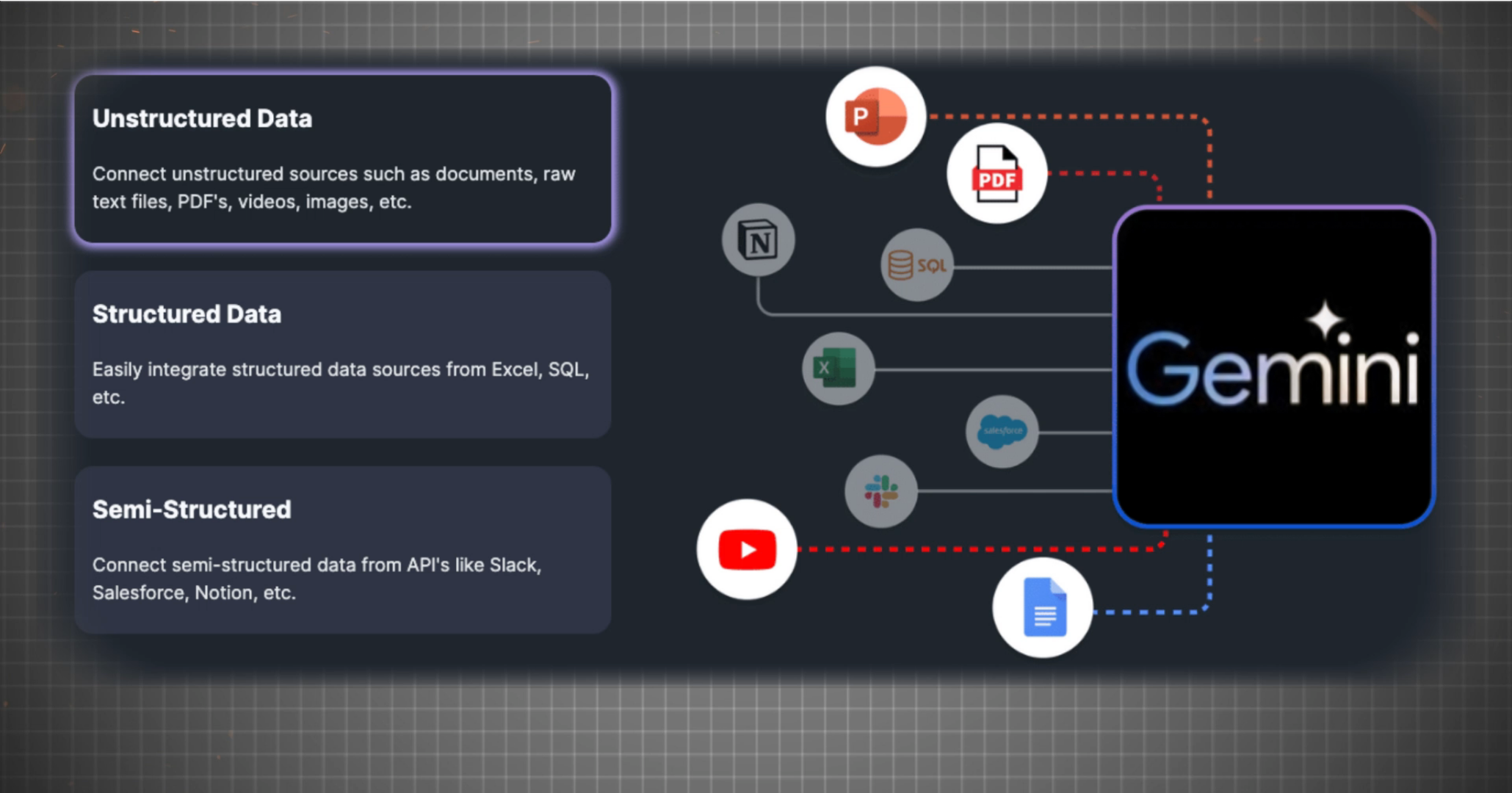
-
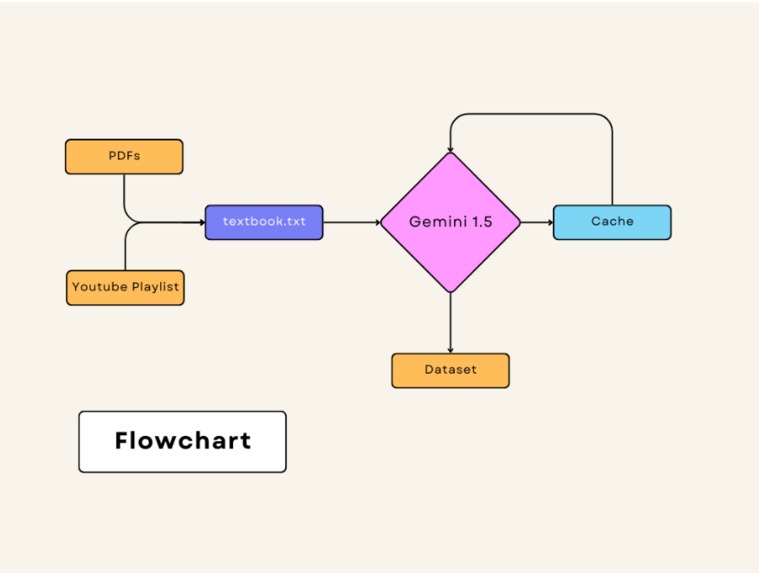
Flowchart
-
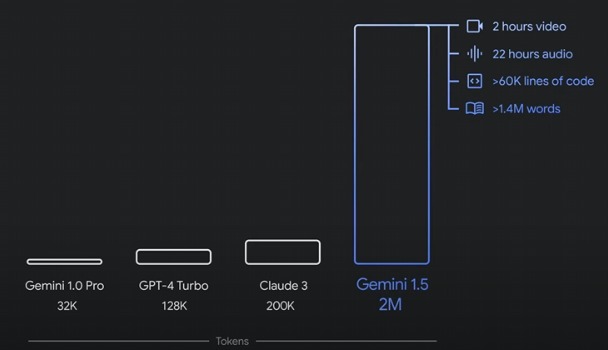
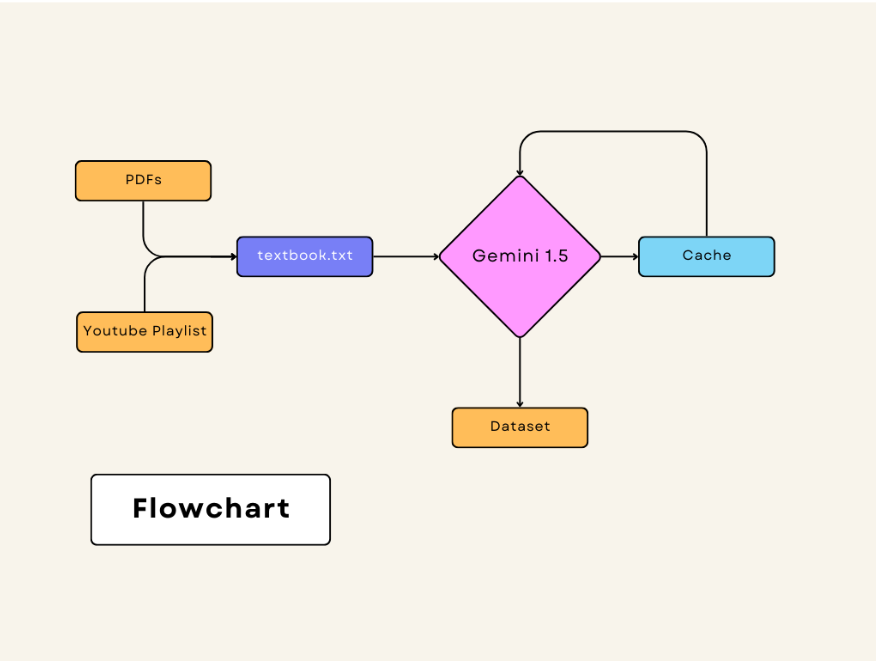

Structured Data Generator Using Gemini
1. Inspiration
Many datasets—especially in enterprise and scientific contexts—are unstructured or poorly formatted, making them hard to use for analytics or ML. Traditional data transformation pipelines are time-consuming and brittle. Generative models like Gemini open a path to automatically turn messy or complex data into structured outputs with just prompt engineering, accelerating data workflows.
2. What It Does
This project allows you to:
- Feed large prompts or raw text (up to millions of tokens) into Gemini.
- Generate structured outputs, such as JSON or tables, ready for ingestion into systems.
- Leverage LLM capabilities for dataset creation, annotation generation, or transformation tasks.
Think of it as a tool that converts any complex narrative or loosely structured content into well-formed, machine-ready structure—instantly.
3. How We Built It
- - Model: Gemini (e.g., Gemini-1.5 long-context model)
Workflow:
- Construct a detailed prompt describing your desired output format (e.g., JSON schema).
- Include your raw data or example text inline.
- Run
generate_content()(or equivalent) to get the structured output from Gemini.
Output: Cleanly formatted output that reflects the schema you specified.
Tip: Incorporate prompt templates or few-shot examples to guide structure generation more reliably.
4. Challenges We Ran Into
- Token Limits & Prompt Size: Gemini’s long-context is powerful, but very large inputs can still hit limits.
- Prompt Sensitivity: Deviations from expected format in prompts can yield inconsistent outputs.
- Lack of Ground Truth: Without automated validation, structured output may reflect formatting issues or hallucinations.
5. Accomplishments
- Demonstrated a working pipeline that transforms raw input into structured data using LLM prompting.
- Showcased millions-of-token capacity handling.
- Created a flexible tool adaptable for data annotation, generating synthetic datasets, or cleaning messy inputs.
6. What We Learned
- Gemini’s long-context strength is a game-changer for handling heavy or complex data inputs.
- Prompt design matters—clarity, schema guidance, and few-shot examples can enhance output quality.
- Even without specialized code (like parsers), generative modeling can streamline structured data creation.
7. What’s Next
- Prompt Refinement: Deploy few-shot prompting or templated examples to improve reliability.
- Validation Layer: Build post-processing checks to catch anomalies or format mismatches.
- Broader Use Cases: Apply this to invoices, logs, scraped text, or multimodal inputs.
- Automation: Combine with RAG or databases to create a data ingestion pipeline.
- Community Sharing: Offer templates for common schemas, letting others fork for their needs.


Log in or sign up for Devpost to join the conversation.