-
-
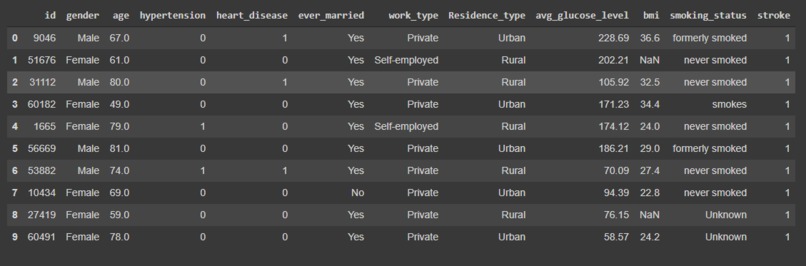
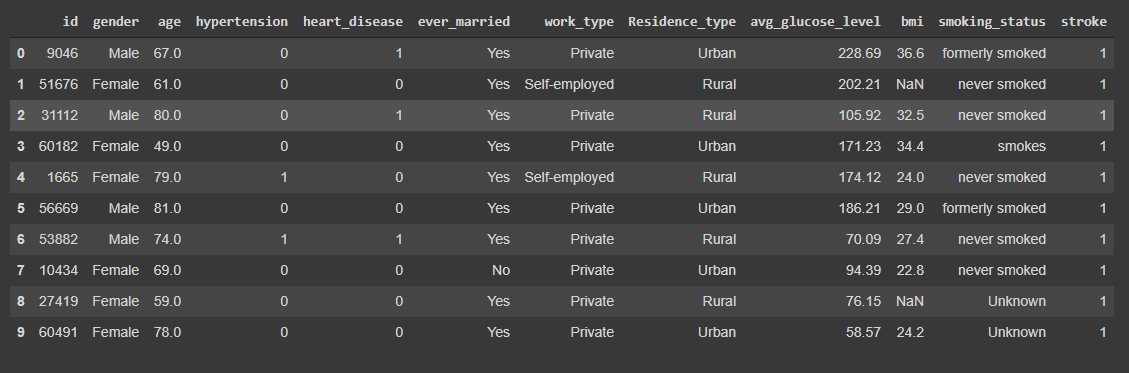
machine learning data
-
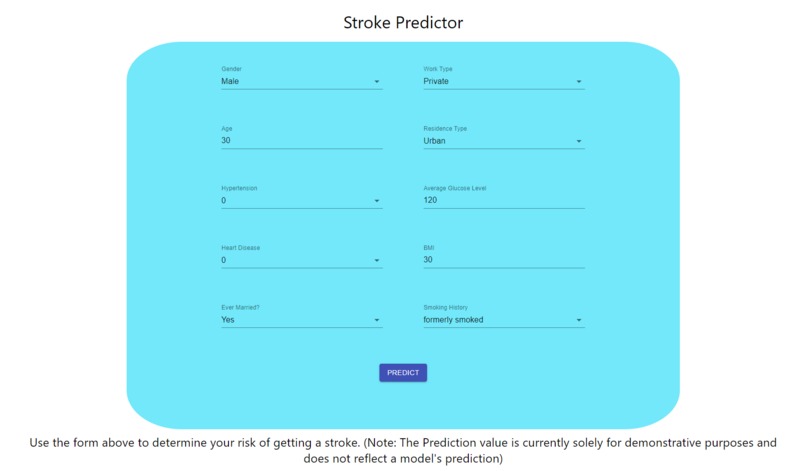
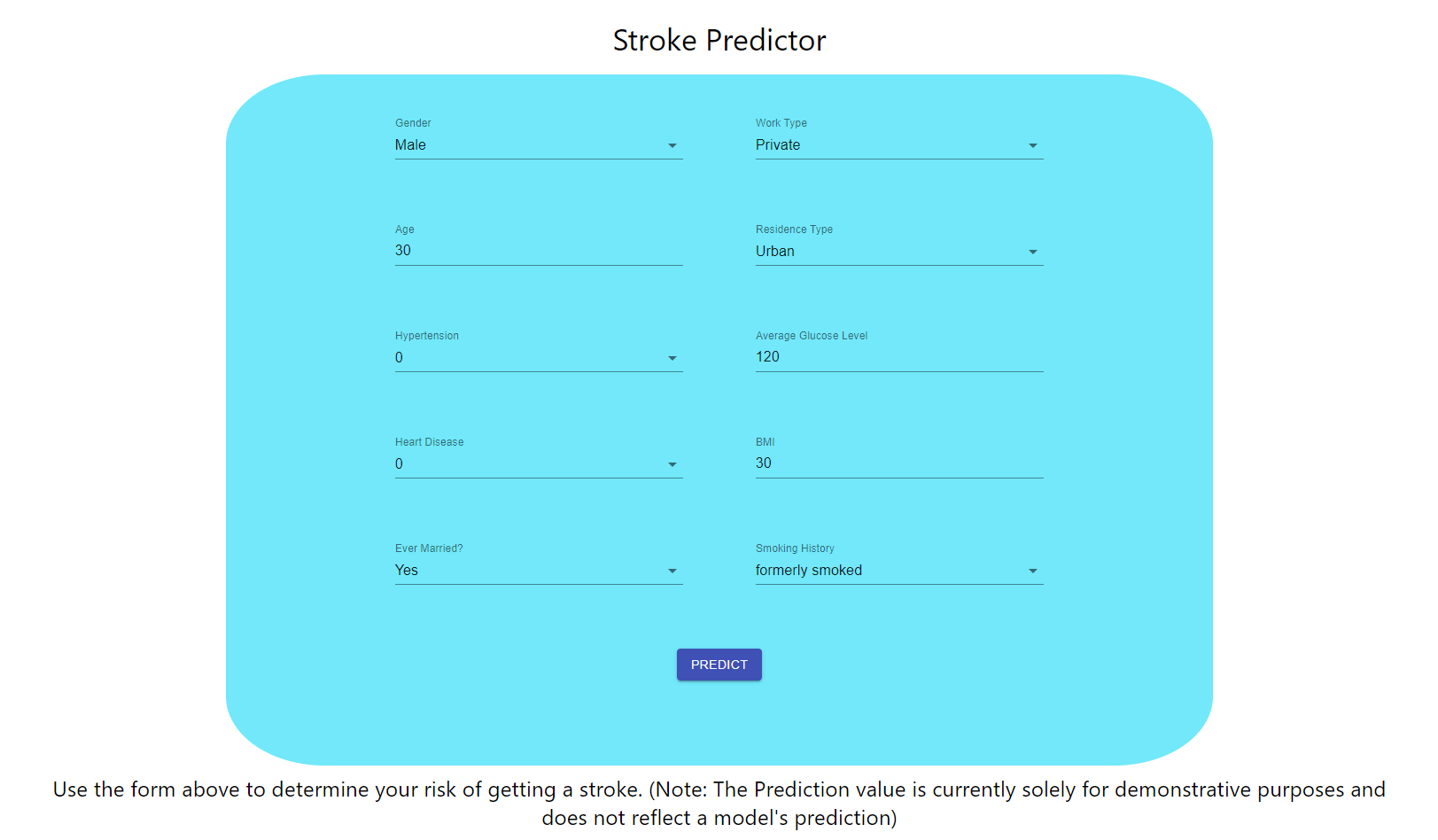
react web app interface
Inspiration
Strokes remain one of the leading causes of death worldwide. According to the CDC, every 40 seconds, someone in the United States suffers from a stroke. If individuals were able to easily predict their risk of having a stroke, they would be more inclined to seek help and adopt healthy lifestyle changes that can help reduce their risk and, potentially, extend their lives. Thus, this project attempts to provide a convenient means of estimating one's current risk of having a stroke.
What it does
This project contains both a machine learning component (in the form of a Google Colab notebook that uses the scikit-learn library) and a web app (made with React). The machine learning component uses a recently-published dataset (https://www.kaggle.com/fedesoriano/stroke-prediction-dataset) to train and evaluate numerous classification models, which are tasked with predicting whether an individual, encoded by a set of features (including smoking history, bmi, and blood glucose levels), is likely to suffer from a stroke. These models also provide probabilities with their predictions (e.g. 30% certain that a given individual will experience a stroke). The web app component provides an easy-to-use interface for entering relevant data and receiving a model's predictions about one's likelihood of having a stroke. This web app can be found at https://stroke-prediction-309002.web.app/.
How we built it
The machine learning component was built by completing the following actions (in order); 1) find and load data 2) explore the data and discover correlations 3) preprocess the data 4) train classification various models from the scikit-learn library (including a logistic regression classifier, a support vector machine classifier, a random forest classifier, and a gradient boosting classifier) 5) fine tune hyperparameters in several models 6) evaluate against a previously-reserved test set (using metrics such as recall, precision, and F1 score)
Afterwards, the web app component was built by (in order): 1) designing the user interface 2) creating custom React components for dropdown input and number input (using Material UI) 3) creating the form (with the relevant options for the different features) 4) creating the predict button and text 5) adding a title and description 6) deploying with Firebase (and registering the strokepredictor.tech domain using Domain.com)
Challenges we ran into
Unfortunately, due to time constraints and technical issues, the model was not successfully uploaded to Google Cloud Platform's AI Platform. Initially, the goal was the deploy the final model from the machine learning component of this project to GCP AI Platform, which would allow the web app to access the deployed model via a REST API. However, issues arose revolving around the use of ColumnTransformer in the final transformation pipeline. Although a solution involving custom pipeline code (https://cloud.google.com/ai-platform/prediction/docs/exporting-for-prediction#custom-pipeline-code) was attempted, I was not able to finish debugging in time. Thus, the web app component serves as an interface that could, in the future, be connected to the models developed in the machine learning component.
Accomplishments that we're proud of
Training and comparing the various classification models was a fun and rewarding experience, and combining both machine learning and web app technologies in a single hackathon was an enjoyable challenge to tackle.
What we learned
From the machine learning component, I learned that fine-tuning hyperparameters can lead to a significantly more generalizable model, that unexpectedly-high recall/precision rates can be a sign of overfitting (especially in the case of the random forest regressor), that a gradient booster classifier is one of the most powerful classification algorithms, that excessive parameter options can cause fine-tuning to take an excessively long time to complete, and that not all features are equally important to consider when developing a classification model (in this case, age and heart disease were the two factors that were the most closely correlated with the risk of having a stroke). From my attempts at deploying the model to GCP's AI Platform, I learned that deploying a pipeline that includes a custom transformer requires exporting that transformer as an individual module.
What's next for Stroke Prediction
One way this project can be improved is by successfully deploying a classifier to GCP's AI Platform or developing a Flask app that provides a REST API for accessing such a classifier. Furthermore, removing more irrelevant features from data before training, finding more data, trying out more classification models, and tuning hyperparameters can all help improve the final classifier's recall score (i.e., how well it catches true positives; in this case, false positives are preferred to false negatives, since predicting that a user will have a stroke and being wrong is less dangerous than not predicting that a user will have a stroke and being wrong). In addition, making the site mobile friendly and improving UI design can make it more attractive and thus increase the number of people it reaches and helps.
Built With
- firebase
- google-cloud
- google-colab
- machine-learning
- material-ui
- react
- scikit-learn

Log in or sign up for Devpost to join the conversation.