-
-
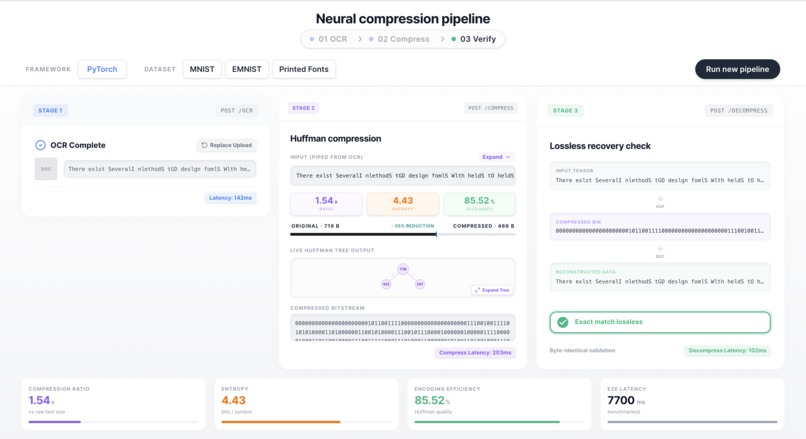
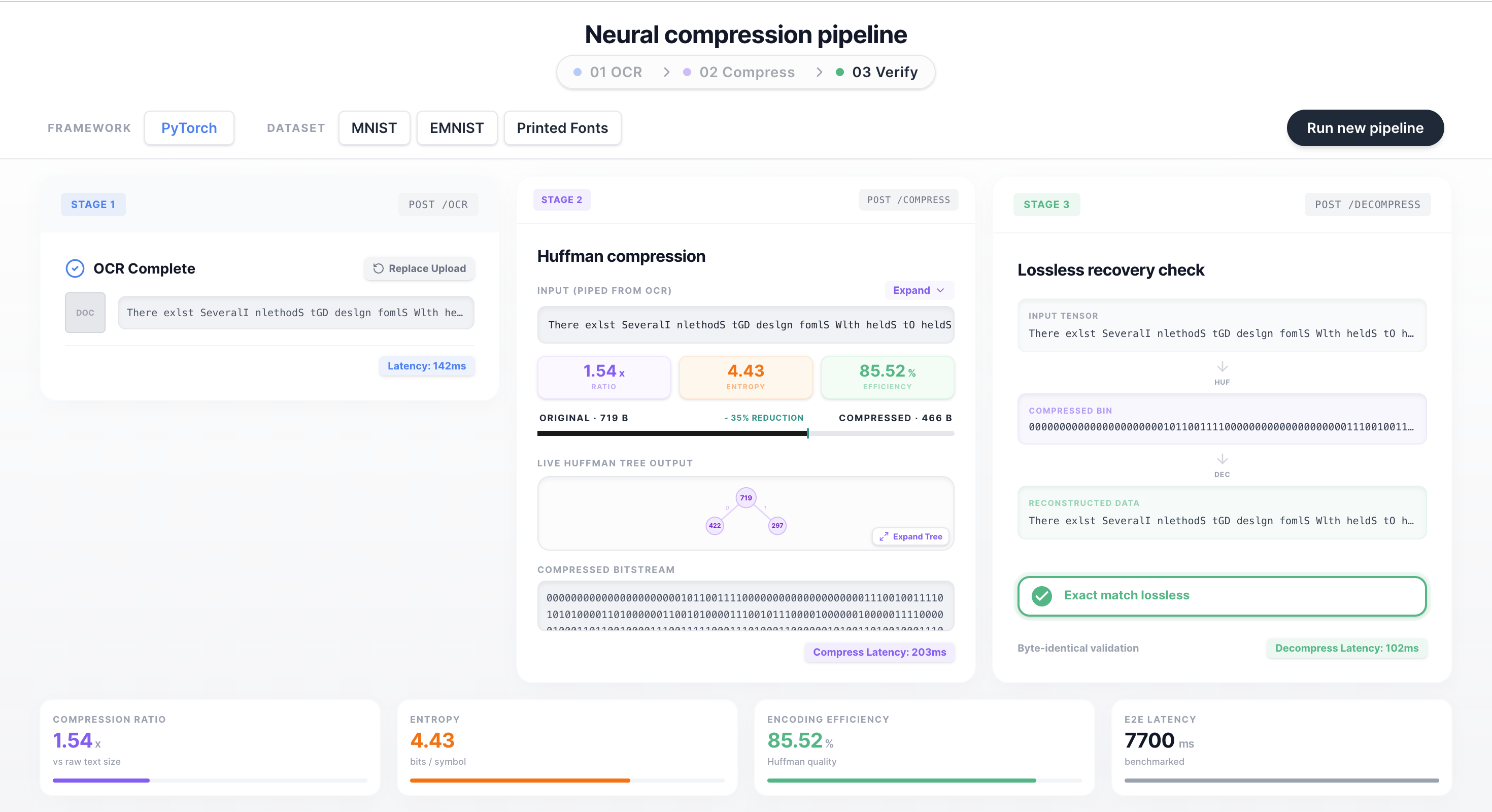
Pipeline Flow
-
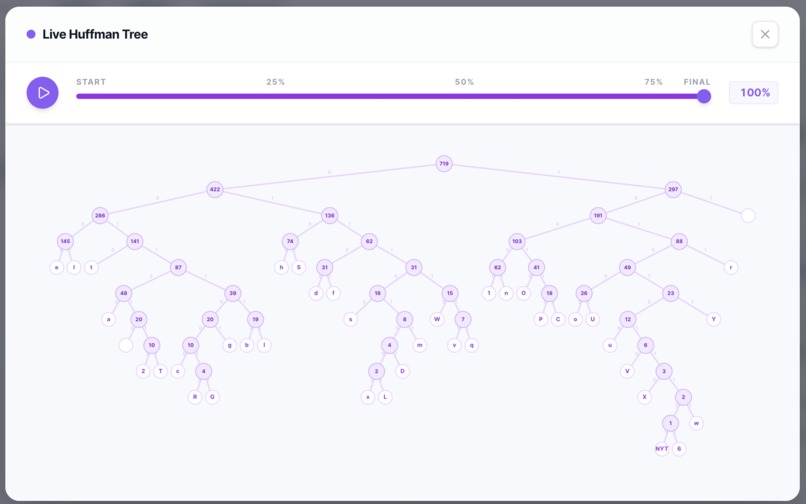
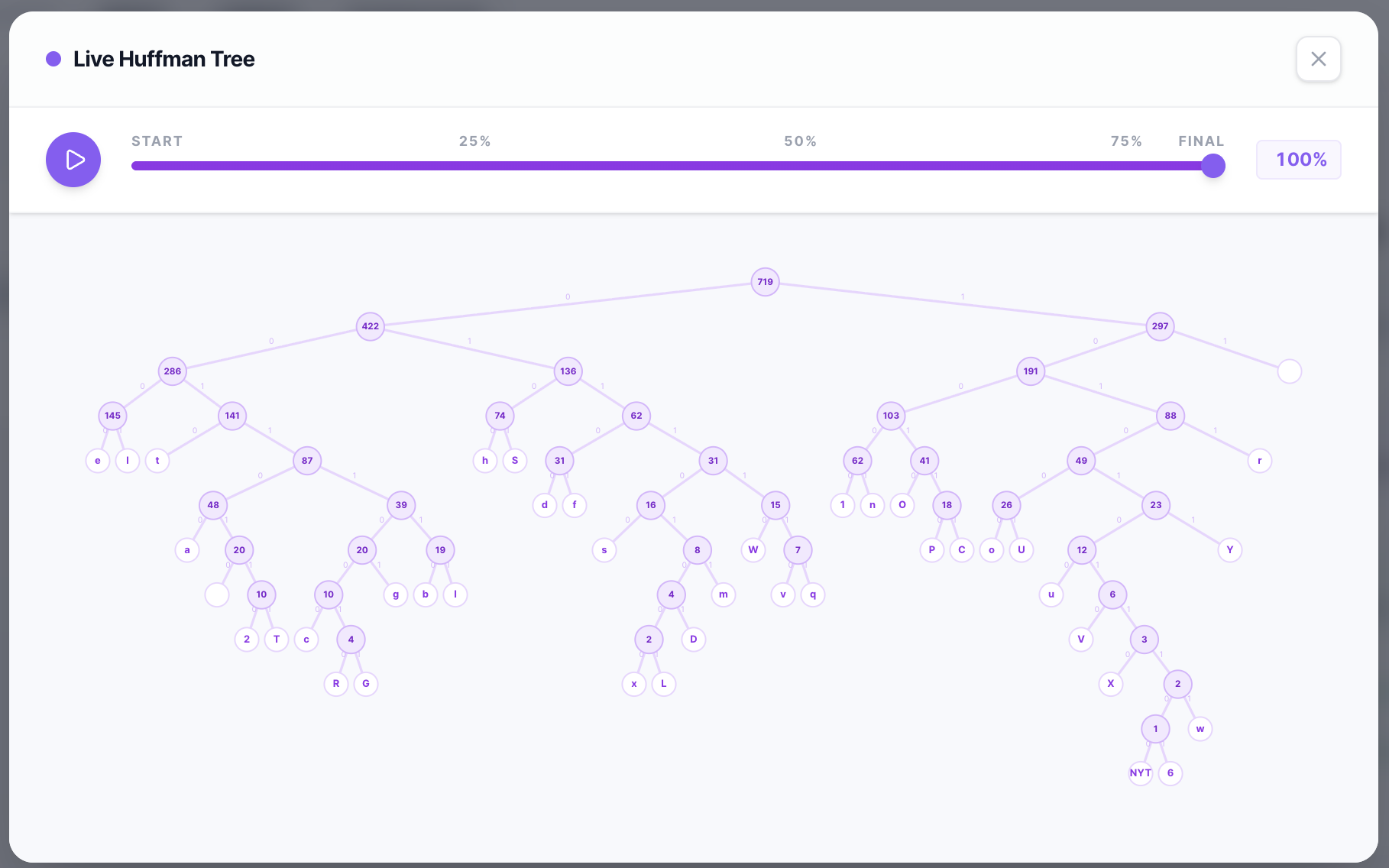
Live Huffman Tree
-
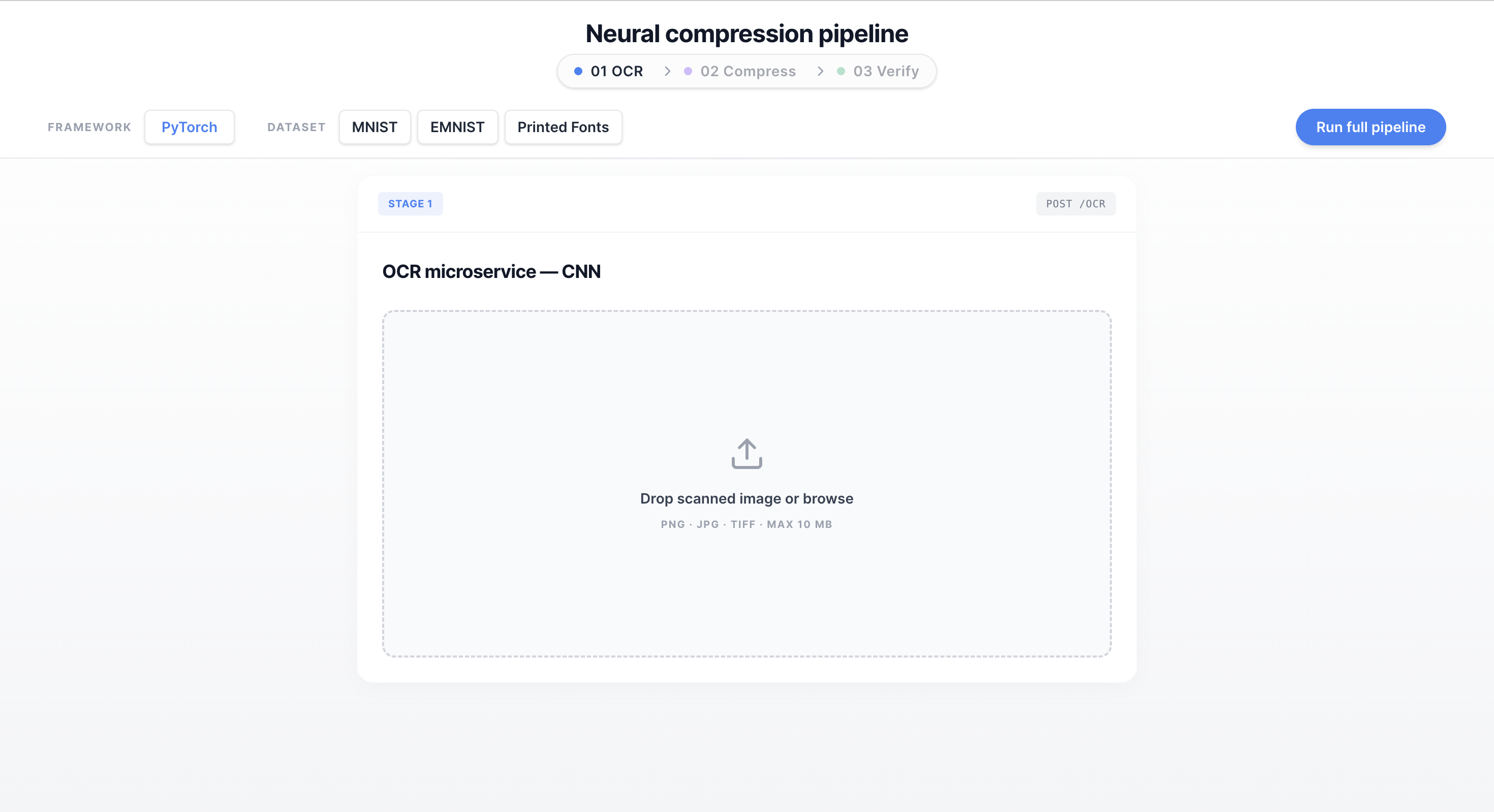
Upload Image
Inspiration
The inspiration came from how real compression pipelines actually work. Tools like modern document archiving systems don't just compress raw bytes — they extract structured content first, then apply entropy coding specifically tuned to that content. We wanted to recreate that design philosophy from scratch: a vision model that understands printed text, feeding directly into a lossless encoder that adapts to the specific frequency distribution of what was just read.
What pushed us further was the constraint itself. No compression libraries. No OCR shortcuts. Every layer of the system — from the adaptive Huffman tree's sibling property maintenance to the blob-splitting segmentation logic — had to be written by hand. That made us think deeply about why Huffman encoding works, and why segmentation quality matters more than model depth. We came out understanding both far better than a library call would have allowed.
What it does
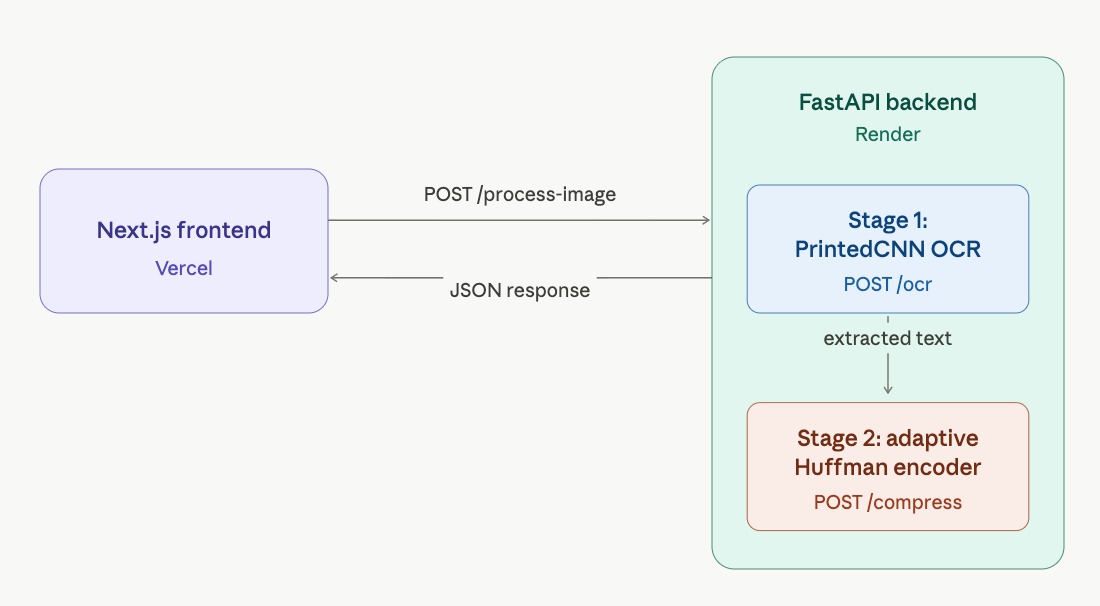
Strike3 is a full end-to-end, two-stage neural compression pipeline that takes a noisy scanned document image and processes it through two custom-built microservices, visualized in real time on an interactive dashboard.
Upload any scanned document and watch the pipeline:
- Extract text using a custom-trained CNN (PrintedCNN) that segments and classifies characters from a noisy image
- Compress the extracted text using a from-scratch Adaptive Huffman (FGK) encoder — zero compression libraries
- Decompress and verify byte-identical lossless recovery
- Display live metrics: compression ratio, Shannon entropy, encoding efficiency, and end-to-end latency
How we built it
Stage 1 — OCR Microservice (PrintedCNN)
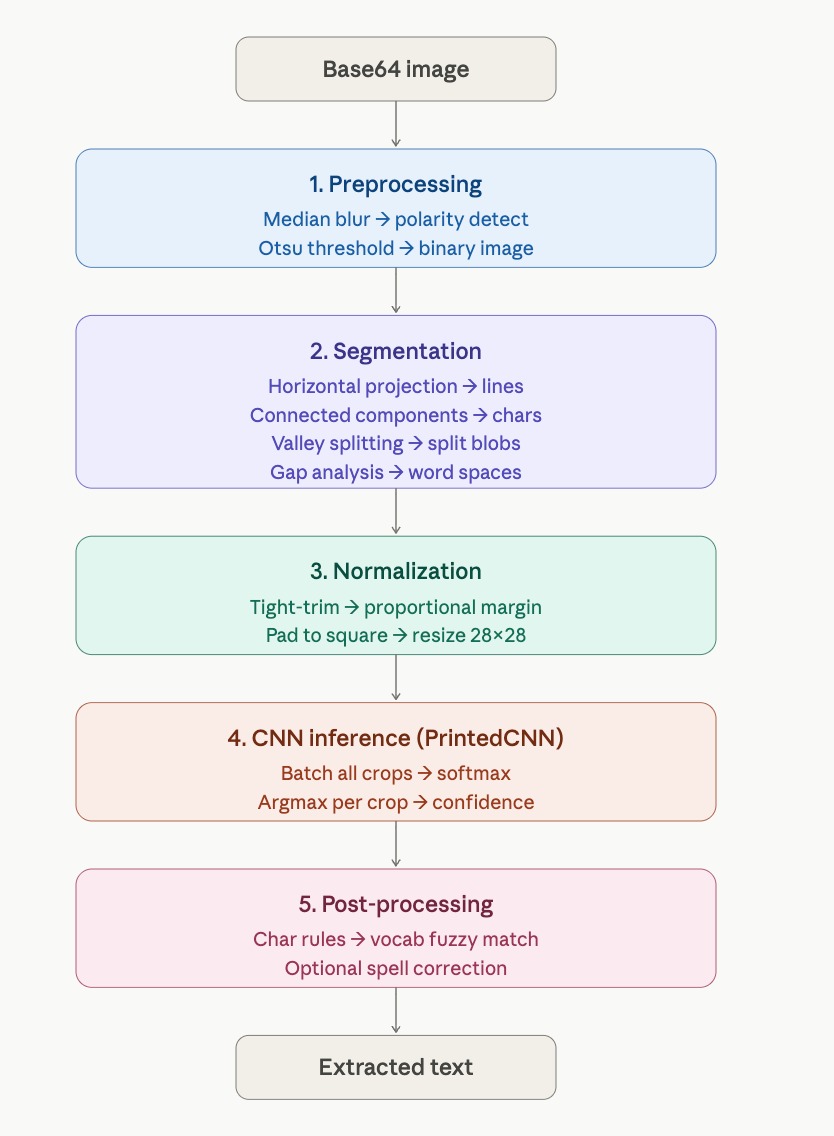
The OCR pipeline processes images through 5 steps:
- Automatic polarity detection + Otsu binarization
- Horizontal projection-based line segmentation
- Connected-component blob detection + vertical valley splitting for merged characters
- Normalize crops to 28×28 → batch classify with CNN
- Char-level rule post-processing + fuzzy vocabulary correction
Model — PrintedCNN (printed_cnn.pth), 47 classes:
| Layer Group | Detail |
|---|---|
| Conv blocks ×4 | BatchNorm + ReLU, MaxPool in first 3 blocks (28→14→7→3) |
| FC head | 256×3×3 → 512 → 47, dropout 0.2 |
| Output | Digits 0–9, A–Z, lowercase subset: a b d e f g h n q r t |
Why this architecture:
- 4 conv blocks capture stroke edges, loops, and printed character structure without being too heavy for CPU deployment
- 3×3 kernels preserve local spatial detail — critical for visually similar classes like
0/O,1/I,5/S - BatchNorm + ReLU stabilized training on mixed synthetic/noisy data
- Three max-pooling stages reduce the 28×28 crop to a compact 3×3 feature map, keeping the classifier lightweight
- 512-unit FC layer with dropout 0.2 balanced capacity and overfitting control for 47 output classes
- Fast inference on small normalized crops matters more here than depth — segmentation quality dominates end-to-end OCR accuracy
Training data:
| Dataset | Role |
|---|---|
| MNIST + EMNIST | Core character priors (handwritten) |
| Synthetic printed fonts | Document-style text generalization |
| Pipeline-aligned synthetic crops | Augmented through same preprocessing flow used at inference |
Noise augmentation: Gaussian and salt-and-pepper perturbations applied during training (30% Gaussian / 20% salt-and-pepper / 50% clean per sample).
Training details: Adam (lr=0.001), ReduceLROnPlateau (patience=3, factor=0.5), CrossEntropyLoss, 90/10 train/val split, batch size 128, up to 30 epochs, early stopping after 6 epochs without improvement.
Stage 2 — Compression Microservice (Adaptive Huffman)
Full FGK (Faller-Gallager-Knuth) Adaptive Huffman encoder/decoder built from scratch — no zlib, gzip, or any external compression library.
The encoder maintains a live Sibling Property tree. Per symbol:
- If new → emit NYT codeword + raw Unicode bits
- If known → emit current Huffman codeword
- Walk up the tree incrementing weights, swapping nodes to preserve Sibling Property
The decoder mirrors this process symbol-by-symbol — no codebook or tree needs to be transmitted.
Metrics reported:
| Metric | Formula |
|---|---|
| Compression ratio | original_bytes / compressed_bytes |
| Entropy | H = −Σ pᵢ log₂ pᵢ bits/symbol |
| Encoding efficiency | (entropy × original_bytes) / compressed_bits × 100% |
Backend & Frontend
Backend: Two FastAPI microservices (POST /ocr, POST /compress, POST /decompress, POST /verify) orchestrated by a single POST /process-image endpoint. The orchestration endpoint runs OCR, then pipes the extracted text into the Adaptive Huffman service in-process using structured CompressRequest / DecompressRequest / VerifyRequest payloads, and returns one combined JSON response. Deployed on Render.
Frontend: Next.js 16 + React 19 + Tailwind CSS, deployed on Vercel.
- OCR Stage: file upload dropzone, live extracted text display
- Compression Stage: animated live Huffman tree evolving step-by-step, expandable input view, progress bar with reduction %
- Verification Stage: Input → Compressed → Reconstructed vertical flow, lossless match badge
- Metric cards (six, all live from API): OCR Accuracy (Gaussian) · OCR Accuracy (Salt & Pepper) · Compression Ratio · Entropy · Encoding Efficiency · E2E Latency
Challenges we ran into
- Segmentation over architecture: getting reliable OCR on noisy printed documents meant segmentation quality mattered more than model depth; width-aware blob splitting for merged characters was the highest-leverage fix
- FGK correctness: the Sibling Property invariant must hold after every single symbol update; subtle off-by-one bugs in node swapping caused cascading decompression failures
- Deployment latency: local Apple MPS runs the full pipeline in < 400ms; Render CPU-only shared instances push this to 5–10s, requiring careful frontend state management to remain usable
- Live Huffman tree animation: rendering each encoding step as an animated SVG in the browser without blocking the UI required a custom step-driven simulation hook
Accomplishments that we're proud of
- A lightweight OCR model achieving 96.04% accuracy on Gaussian noise and 95.2% on salt-and-pepper noise — no heavy backbone required
- A fully from-scratch Adaptive Huffman implementation achieving ~78% encoding efficiency
- A live animated Huffman tree that renders each encoding step in real time in the browser
- A single
POST /process-imageorchestration endpoint that chains OCR → compress → decompress → verify, and returns all metrics in one JSON response
What we learned
- Preprocessing pipelines are often the highest-leverage component of a vision system; better segmentation beats deeper models
- Adaptive Huffman is deceptively subtle. The Sibling Property must be maintained after every node update, not just at sequence boundaries
- Chaining microservices through a single orchestration endpoint significantly simplifies frontend integration and reduces round-trips
- Keeping animation state decoupled from API response state was essential for a smooth UI, even on slow Render deployments
What's next for Strike3
- Extend OCR to full cursive handwriting with the CRNN (BiLSTM + CTC) variant already prototyped
- Add arithmetic coding as an alternative Stage 2 and benchmark against Adaptive Huffman
- Support multi-page PDF ingestion and batch compression reporting
- GPU inference on Render to bring deployed latency closer to local performance
Benchmarks
| Metric | Value |
|---|---|
| OCR accuracy (Gaussian noise) | 96.04% |
| OCR accuracy (Salt-and-pepper noise) | 95.2% |
| Typical compression ratio | 1.8 – 2.2× |
| Typical encoding efficiency | ~78% |
| E2E latency (local, Apple MPS) | < 400 ms |
| E2E latency (Render CPU) | 5 – 10 s |
Built With
- fastapi
- next.js
- node.js
- opencv
- pillow
- pydantic
- python
- pytorch
- render
- typescript
- vercel











Log in or sign up for Devpost to join the conversation.