-
-
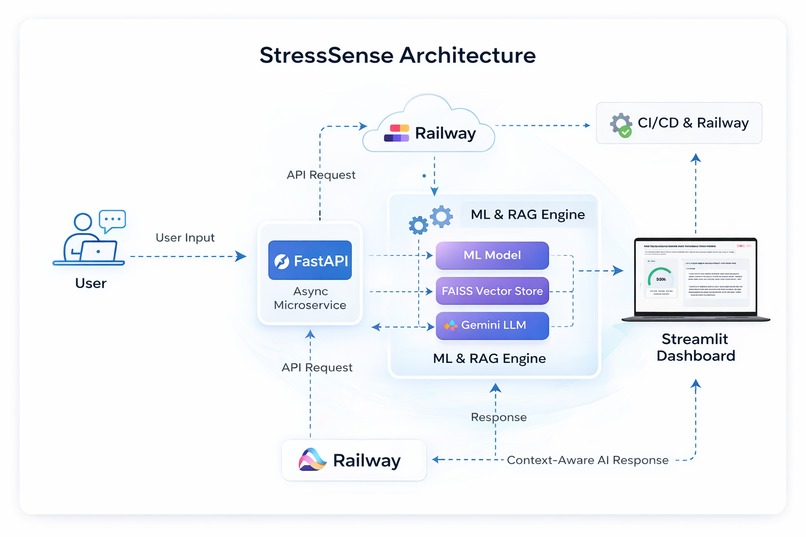
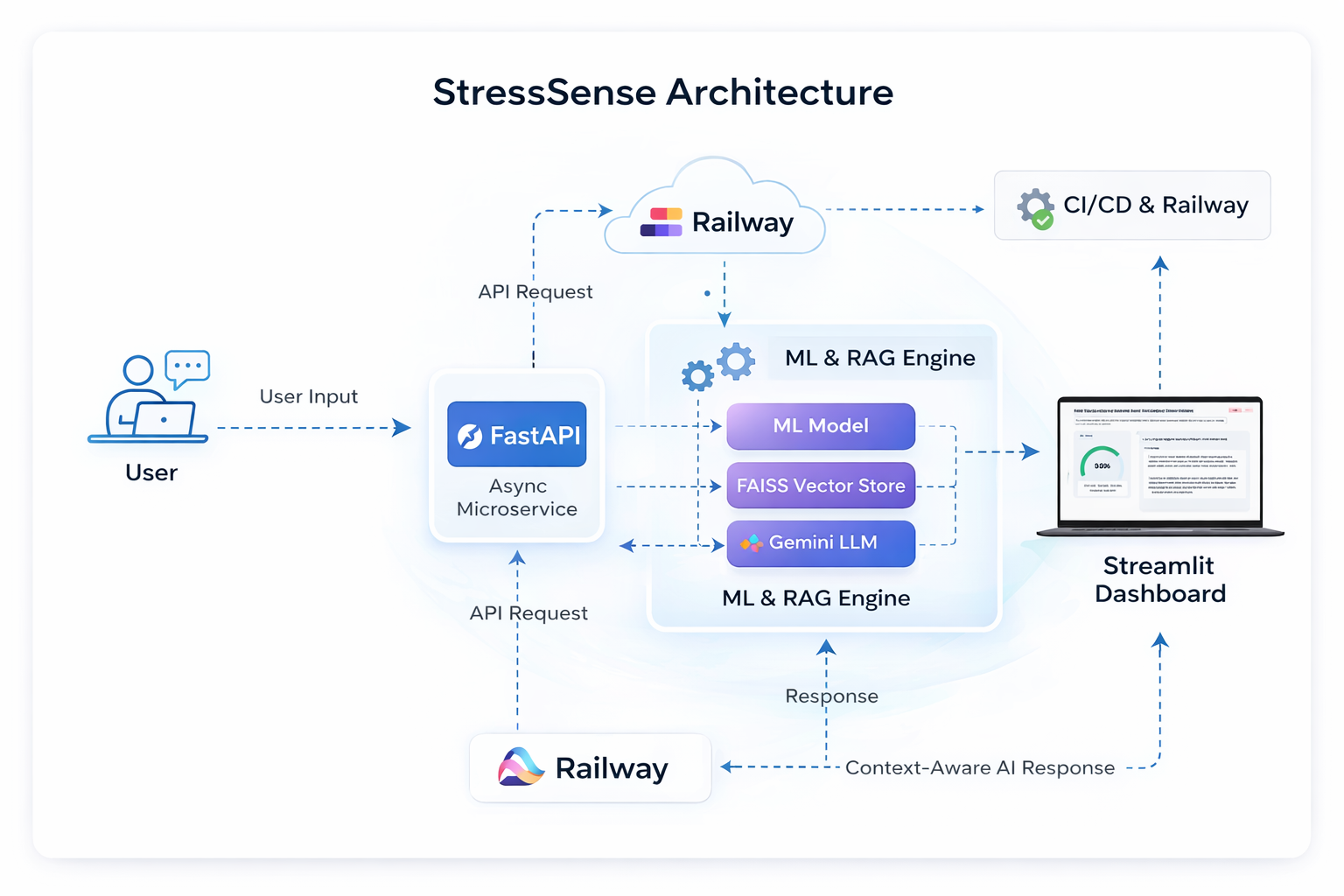
Architecture diagram
-
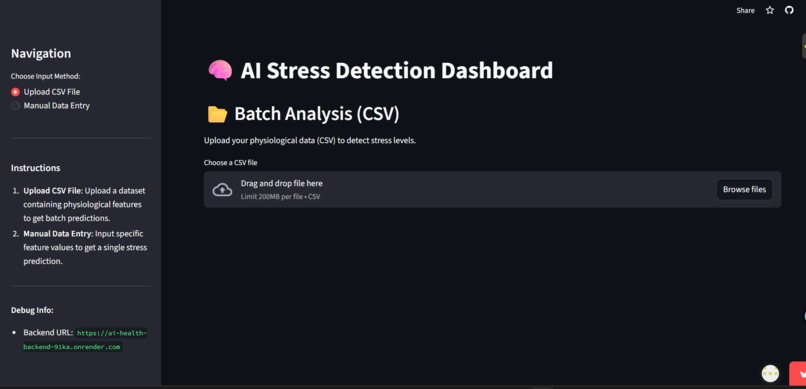
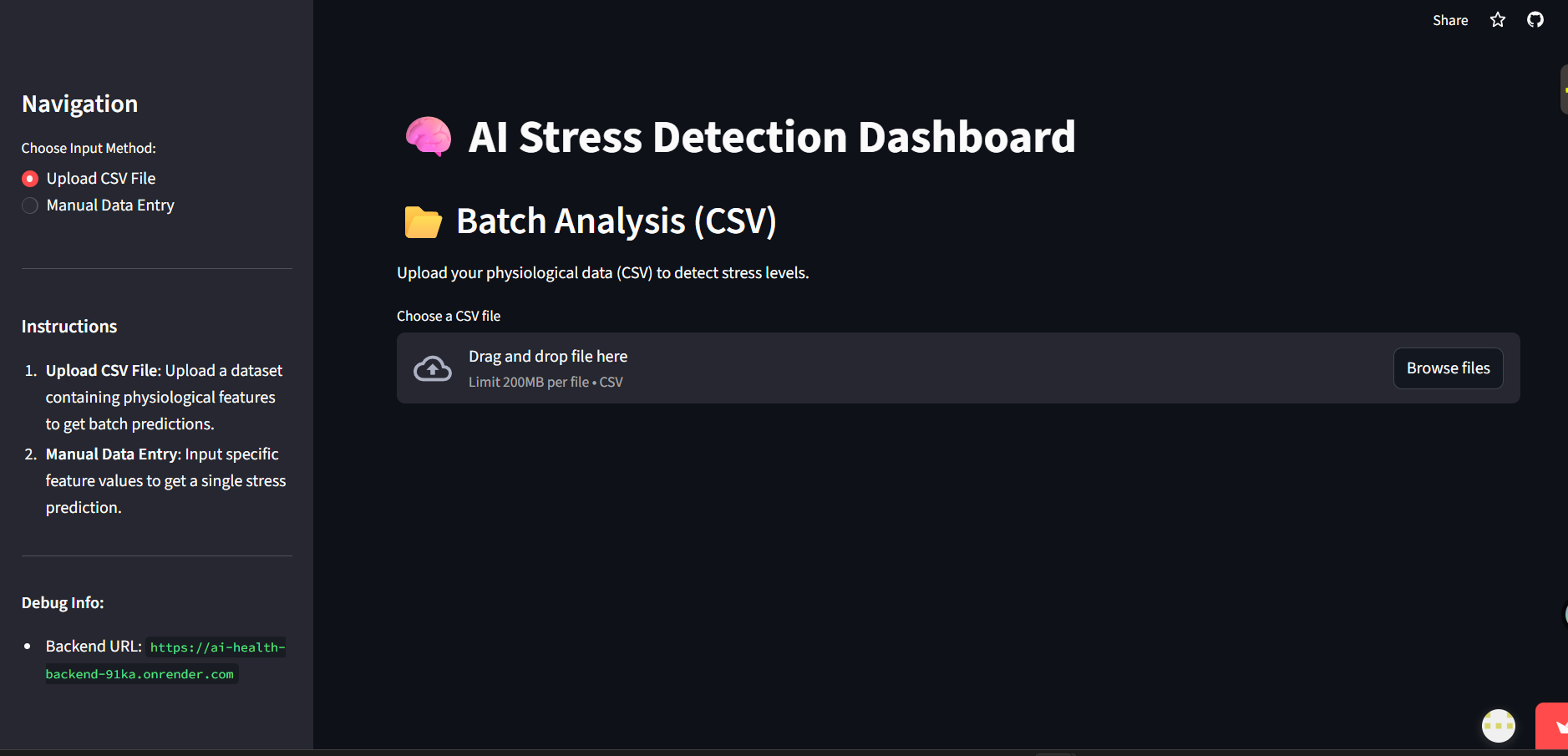
Dashboard
Inspiration
Mental health challenges, especially stress and burnout, are often overlooked until they become severe. While many tools provide generic advice, very few systems combine data-driven stress prediction with context-aware AI coaching.
We wanted to build a platform that doesn’t just classify stress levels — but understands context and responds intelligently.
StressSense was inspired by a simple question: Can we combine structured physiological data with generative AI to create a real-time, intelligent stress support system?
What it does
StressSense is a Multimodal AI-powered Stress Intelligence Platform that:
Predicts stress levels using machine learning models trained on 10,000+ records.
Processes structured health indicators and behavioral inputs.
Uses a Random Forest classifier to estimate stress probability:
𝑃 (Stress)=Number of Trees Predicting Stress Total Trees P(Stress)= Total Trees Number of Trees Predicting Stress
Integrates a Retrieval-Augmented Generation (RAG) pipeline using Gemini + FAISS to deliver context-aware, medically grounded coaching responses.
Provides real-time personalized feedback through a Streamlit interface.
Ensures inference latency below 200ms using asynchronous FastAPI microservices.
It acts as a real-time AI stress coach — not just a classifier.
How we built it
1️⃣ Data Processing & Model Training
Cleaned and preprocessed 10,000+ records using Pandas. Addressed class imbalance using SMOTE. Engineered features for improved model performance. Trained and evaluated a Random Forest model. Validated using cross-validation and performance metrics (Accuracy, F1-score).
2️⃣ RAG Architecture Embedded curated mental health knowledge sources. Stored vector embeddings using FAISS. Used Gemini LLM for response generation. Combined: Retrieved medical context User stress classification Personalized prompts Final response =LLM(User Context+Retrieved Knowledge)
3️⃣ Backend Architecture Built scalable microservices using FastAPI. Implemented asynchronous endpoints for low-latency inference. Containerized and deployed via Railway. Built Streamlit frontend for interactive visualization. Integrated CI/CD pipelines for automated deployment.
Challenges we ran into
Handling class imbalance in stress datasets. Reducing hallucinations in LLM-generated health advice. Maintaining inference latency under 200ms while integrating ML + RAG. Managing prompt engineering to balance empathy with medical safety. Ensuring cloud deployment stability and uptime.
Accomplishments that we're proud of
Successfully deployed an end-to-end ML + RAG production pipeline. Achieved sub-200ms inference latency. Designed a modular architecture supporting future multimodal expansion (voice, wearable inputs). Maintained 99.9% uptime with automated CI/CD. Built a system that merges predictive ML with generative AI responsibly.
What we learned
Production ML is very different from notebook experimentation. Latency optimization is as important as model accuracy. RAG significantly improves reliability in healthcare-oriented AI. Prompt engineering requires iterative testing and safety alignment. Scalable architecture design matters from Day 1.
What's next for StressSense
Integrating wearable device APIs (HRV, sleep tracking). Adding emotion detection via voice input. Fine-tuning a domain-specific stress LLM. Implementing user feedback loops for continual learning. Enhancing explainability using SHAP-based model interpretation.
Built With
- faiss
- fastapi
- googlegeminiapi
- pandas
- python
- scikit-learn


Log in or sign up for Devpost to join the conversation.