-
-
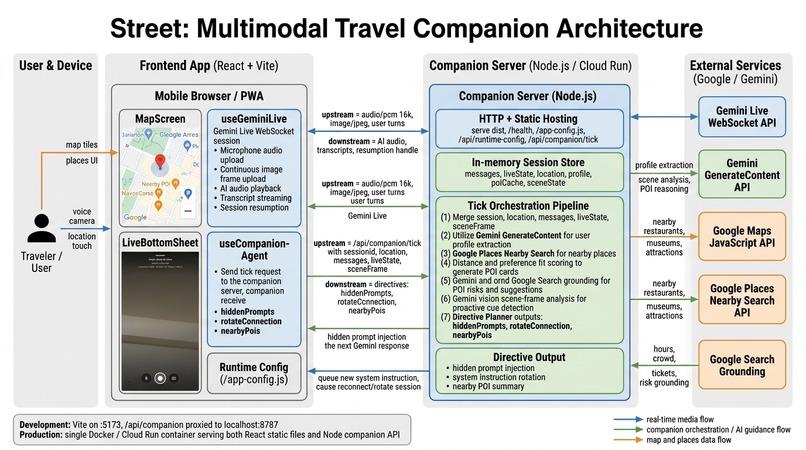
Project Architecture Diagram
Proof Video: Project Running on Google Cloud Run https://youtu.be/6h-LumT4UIA
Inspiration
Existing AI tour guides are highly inefficient. They are essentially just audio versions of Wikipedia pages: you have to stop walking, look down at your screen, input a command or press a "speak" button, and then wait for a lengthy monologue. This completely destroys the immersive experience of travel.
So, we set out to create an entirely new kind of AI companion—one capable of proactively speaking up to explain the world to you, based on what you see.
What it does
Street is a "Live Agent"—an initiative, multimodal, and interruptible real-time intelligent assistant designed specifically for mobile devices (PWA). It eschews the traditional chatbox interface, instead utilizing your device's camera feed as its core user interface.
- Gaze-Triggered & Proactive Intervention: Street observes the world around you through your camera lens. If you point your camera at a "Closed" sign hanging on a museum entrance, it will instantly recognize the content and proactively suggest an alternative route for you.
- Full-Duplex, Multilingual Agent (Interruptible): Exploring a foreign land is often full of uncertainties. Street acts as your real-time interpreter—for instance, enabling you to communicate directly with staff at a noisy fast-food counter. Powered by the Gemini Live API, users can even interrupt the AI mid-translation to modify their instructions; the AI will immediately halt its current translation and dynamically adjust its response based on the new input.
- "Memory": This project incorporates a memory module that continuously retains your preferences and other details as your conversation progresses. It dynamically adapts its interaction style over time, evolving from a lifeless "machine" into a close friend who truly understands your tastes.
Challenges we ran into
This marks my first time undertaking a complex AI architecture entirely as a solo developer. While tools like Codex significantly accelerated my initial prototyping, the actual implementation of the Gemini Live API presented severe architectural challenges that forced me to aggressively pivot my original scope.
Initially, my design intended for the Gemini Live API to directly invoke synchronous backend agents (Function Calling) to fetch local data. However, during testing, I discovered a critical technical trade-off: forcing the active Live WebSocket to wait for external API resolutions introduced unacceptable latency, completely destroying the "interruptible, real-time" illusion of the guide.
To solve this within the hackathon timeframe, I had to abandon the synchronous tool-calling approach. Instead, I architected the "Asynchronous Hot Injection" pattern—moving the heavy data-fetching logic to a separate Node.js service, which silently pushes system overrides to the frontend. This was a difficult but necessary engineering compromise to protect the millisecond-level audio response time.
Accomplishments that we're proud of
As an independent developer, building a fully functional, multimodal AI agent capable of real-time interaction—from scratch and within the limited timeframe of a hackathon—was undoubtedly an incredibly daunting engineering challenge. My proudest achievement lies in having shattered the conventions of traditional AI interaction by completely discarding the "text-to-text" and the "Push-to-Talk" paradigm. Street is capable of successfully detecting and responding to continuous visual cues—such as a user pausing to gaze at a specific street sign—thereby eliminating the need for the user to perform any explicit button presses.
What we learned
In this project, I initially attempted to embed a substantial amount of contextual data and tool-calling logic within the system instructions of the Gemini Live API. However, I soon discovered that in real-time streaming scenarios, overly verbose prompts severely dragged down the "Time to First Byte", thereby completely undermining the immersive sense of presence. Consequently, "separation of concerns"—specifically, keeping the Live Agent "dumb but fast" while allowing the Auxiliary Agent to be "smart but slow"—stands as the only viable architectural solution for current multimodal systems.
What's next for Street
While the prototype successfully proves the viability of a real-time, multimodal Dual-Agent architecture, there is significant room to scale this into a production-ready travel concierge:
- Advanced Contextual Localization: Currently, forcing the Live API to rapidly switch contexts via secondary agent injections can occasionally disrupt its language lock. A major next step is to refine the prompt engineering pipeline and utilize Gemini's structured output controls to enforce strict adherence to the user's native language during "Hot Injections."
- Refining Visual Intent Heuristics: To move closer to 100% accuracy in proactive conversations, we plan to upgrade the client-side trigger logic. We aim to implement lightweight, edge-based object tracking to better infer when a user is genuinely confused versus simply looking around.
Built With
- gemini-2.5-flash-native-audio-preview-12-2025
- gemini-3.1-flash-lite-preview
- gemini-live-api
- google-cloud
- google-cloud-run
- pwa
- react
- tailwindcss
- vite
- websocket

Log in or sign up for Devpost to join the conversation.