-
-

Streamguard Title
-

Inspiration
What it does
About the Project - StreamGuard
The Inspiration: Curiosity About Multi-Agent Systems
This project started with a simple question: "What if AI agents could create infrastructure, not just detect patterns?"
I'd been following Google's Agent Development Kit (ADK) release and was fascinated by the concept of specialized agents working together rather than one monolithic LLM trying to do everything. Most fraud detection demos I'd seen were single-model approaches - feed transaction data in, get a risk score out.
I wanted to explore:
- Agent orchestration: Can Detective → Judge → Enforcer pipelines work better than single-step classification?
- Structured communication: Would Pydantic models eliminate the "LLM says random stuff" problem?
- Dynamic infrastructure: Could agents autonomously provision Kafka topics and Flink routes, not just flag alerts?
- Real-time streaming + AI: How do you marry Confluent's millisecond data pipelines with Vertex AI's LLM latency?
The fraud detection use case was perfect because it's multi-stage by nature (investigate → decide → enforce) and has a real $12.5B problem to tackle. Authorized Push Payment (APP) fraud affects primarily elderly victims with an 80% success rate when scammers use active voice calls - traditional systems fail because victims authorize transactions themselves.
So I built StreamGuard to test if multi-agent AI + real-time streaming could solve what rule-based systems can't.
What We Built: Three Agents, One Mission
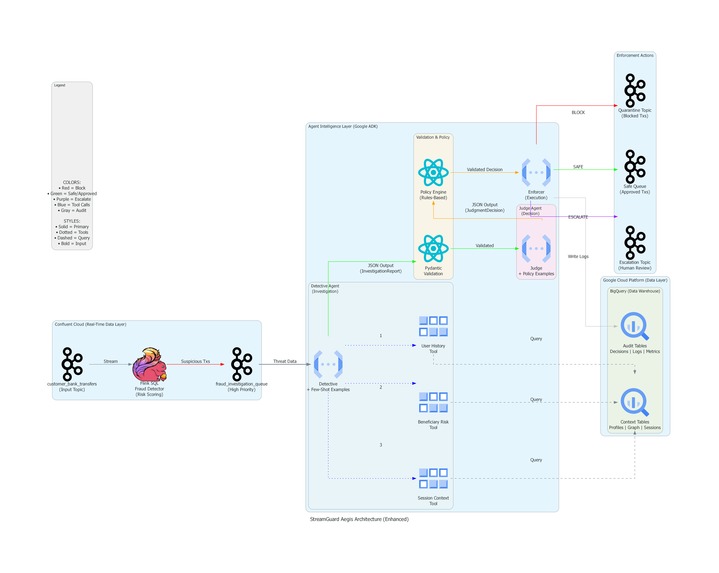
StreamGuard is a real-time fraud detection system that orchestrates three specialized AI agents in a sequential pipeline:
1. Detective Agent - The Investigator
The Detective doesn't just look at transaction data. It investigates the context:
- User History Tool: Queries BigQuery for account tenure, previous violations, behavioral segments
- Beneficiary Risk Tool: Analyzes destination account age, relationship graphs, risk scores
- Session Context Tool: Examines mobile app telemetry - typing cadence, active calls, device flags
These three tools run in parallel using Google ADK's multi-agent framework, gathering evidence in milliseconds.
2. Judge Agent - The Decision Maker
The Judge receives a structured InvestigationReport (Pydantic model) and applies a 6-tier policy engine:
POLICIES (apply the FIRST matching policy in this specific order):
1. CRITICAL FRAUD: If `security_flags.active_voice_call` is True OR risk_level is `CRITICAL`, you MUST BLOCK immediately. This rule has HIGHEST priority and OVERRIDES VIP protection.
2. REPEAT OFFENDERS: If the user has 1 or more previous violations, BLOCK.
3. FIRST-TIME CLEAN: If the user has 0 previous violations AND no other critical red flags (not new account, not VIP, no active call), you MUST use SAFE for this audit trail. Note: All transactions are already > $1000 (Flink pre-filters), so amount checks don't apply.
4. NEW ACCOUNT: If the beneficiary account is < 24 hours old, ESCALATE_TO_HUMAN.
5. VIP PROTECTION: For users with tenure > 5 years, ESCALATE_TO_HUMAN instead of blocking if no higher-priority fraud/repeat policy triggers.
6. LOW RISK: If none of the above apply and risk_level is LOW or MEDIUM, use SAFE to allow the transaction.
The Judge outputs a JudgmentDecision with explainable reasoning and confidence scores.
3. Enforcer Agent - The Autonomous Responder
Here's where it gets unique. The Enforcer doesn't just flag transactions - it creates real infrastructure:
# Enforcer autonomously provisions:
1. Kafka topic: fraud-quarantine-betty-senior
2. Flink SQL statement: Route all Betty's transactions to quarantine
3. BigQuery Sink connector: Auto-create audit table with schema evolution
The Architecture: Streaming + AI + Infrastructure as Code
Mobile Banking App
↓
Kafka Topics (Confluent Cloud)
↓
Flink SQL Filtering (amount > $1000)
↓
fraud_investigation_queue
↓
┌───────────────────────────────────────────┐
│ Agent Pipeline (Google ADK + Vertex AI) │
│ │
│ Detective → Judge → Enforcer │
│ (Gemini) (Gemini) (Gemini) │
│ │
│ Structured Communication via Pydantic │
└───────────────────────────────────────────┘
↓
Dynamic Infrastructure Creation
↓
BigQuery Audit Tables
Technology Stack:
- Google Cloud: Vertex AI (Gemini 2.0 Flash), BigQuery, Service Accounts
- Confluent Cloud: Kafka, Flink SQL, Schema Registry (11 Avro schemas), Managed Connectors
- Infrastructure: Terraform (reproducible deployments), Python 3.9+
- Framework: Google ADK for multi-agent orchestration
- Type Safety: Pydantic models for structured agent communication
Key Learnings: From Chaos to Clarity
1. Type Safety Saves Lives (and Sanity)
The Problem: Our first prototype had agents communicating via raw LLM text. Parsing failures hit 30%+.
# ❌ Before: Detective outputs free-form text
"User Betty Senior appears high risk due to active call..."
# Judge tries to parse this → 30% failure rate
The Solution: Structured Pydantic models reduced errors to <5%:
# ✅ After: Detective outputs typed JSON
class InvestigationReport(BaseModel):
transaction_id: str
risk_score: int = Field(ge=0, le=100)
risk_level: RiskLevel # Enum: LOW, MEDIUM, HIGH, CRITICAL
security_flags: Dict[str, bool]
# Judge receives validated data, no parsing ambiguity
Learning: For production AI systems, structured output is not optional - it's the difference between 70% reliability and 95%+ reliability.
2. LLMs Need Examples, Not Just Instructions
The Problem: Zero-shot agents skipped required tool calls 40% of the time.
# Detective was told: "You MUST call all three tools"
# But still skipped beneficiary_risk 40% of the time
The Solution: Few-shot examples with explicit tool sequences:
# Added 3 examples showing CORRECT tool usage:
Example 1: CRITICAL risk → all 3 tools called
Example 2: LOW risk → all 3 tools called
Example 3: HIGH risk → all 3 tools called
# After: Tool skip rate dropped to <5%
Learning: Show, don't tell. LLMs learn patterns from examples far better than from imperative instructions.
3. Distributed Systems Have Hidden Timings
The Problem: Enforcer created Kafka topics, but Flink couldn't see them for ~30 seconds.
[ERROR] Flink: Topic 'fraud-quarantine-betty' not found
# But topic EXISTS in Kafka! What?!
The Solution: Metadata propagation delay - Flink's catalog refresh cycle.
def create_topic_and_route(topic_name: str):
kafka_admin.create_topics([topic_name])
# Critical: Wait for Flink metadata propagation
time.sleep(30)
flink_client.execute_statement(f"""
INSERT INTO {topic_name}
SELECT * FROM fraud_queue WHERE user_id = 'betty_senior'
""")
Learning: Distributed systems are eventually consistent - plan for propagation delays and don't assume instant visibility.
4. Hybrid AI+Rules Beats Pure LLM
The Problem: Pure LLM decisions varied 15-20% across identical inputs.
# Same investigation data, different runs:
Run 1: Judge → BLOCK (confidence: 92%)
Run 2: Judge → ESCALATE_TO_HUMAN (confidence: 88%)
Run 3: Judge → BLOCK (confidence: 94%)
The Solution: Hybrid policy engine validates LLM decisions:
# Judge makes LLM decision
judgment = judge_agent.run(investigation)
# Policy engine compares against deterministic rules
expected = policy_engine.make_decision(investigation)
if judgment.decision != expected.decision:
log_warning(f"Policy mismatch: {judgment} vs {expected}")
Learning: For compliance-critical systems, combine LLM flexibility with rule-based auditability. Best of both worlds.
The Challenges I Faced
Challenge 1: Windows Development Environment
Problem: Terraform's JSON output caused PowerShell encoding errors:
> terraform output -json
Error: invalid character '\ufeff' looking for beginning of value
Root Cause: UTF-8 BOM (Byte Order Mark) that PowerShell adds.
Solution: Built custom JSON parser with BOM detection:
def parse_terraform_output(json_str: str) -> dict:
# Remove UTF-8 BOM if present
if json_str.startswith('\ufeff'):
json_str = json_str[1:]
return json.loads(json_str)
Challenge 2: Credential Management Sprawl
Problem: GCP credential setup duplicated across 4 files (~200+ lines total).
Solution: Centralized credential manager with auto-cleanup:
# config/gcp_credentials.py
import atexit
_temp_files = []
def setup_google_credentials() -> str:
"""Create temp service account file, register cleanup."""
temp_path = create_temp_key_file()
_temp_files.append(temp_path)
return temp_path
def _cleanup_temp_files():
"""Auto-delete credential files on exit."""
for path in _temp_files:
os.unlink(path)
atexit.register(_cleanup_temp_files)
Impact: Reduced code from 200+ lines to 50 lines, eliminated security vulnerability (temp files now always cleaned up).
What We're Proud Of
Production-Ready Architecture: Not a prototype - includes IaC, error handling, cleanup automation, comprehensive testing
Real-World Impact: Addresses a $12.5B problem affecting vulnerable populations
Novel Approach: First known implementation of multi-agent orchestration for fraud detection with autonomous infrastructure provisioning
Type Safety: Reduced LLM errors from 30% to <5% via Pydantic models
Testable Compliance: Policy engine with 15+ unit tests for regulatory auditability
Dual-Mode Demo: Tutorial (storytelling) + Playground (interactive testing) for judges to actually try the system
Future Vision
Phase 2: Multi-Model Consensus
- Detective uses Gemini 2.0 Flash (speed)
- Judge uses Gemini 2.0 Flash Thinking (reasoning)
- Cross-validate decisions for higher confidence
Phase 3: Federated Learning
- Edge device ML models pre-filter at source
- Only suspicious transactions reach cloud agents
- Privacy-preserving + reduced latency
Phase 4: Self-Healing Policies
- System learns from false positives/negatives
- Policy engine auto-updates based on new attack patterns
- Human-in-the-loop approval for policy changes
The Real Test: Does Multi-Agent Beat Single-Model?
In our "Classic Coaching Fraud" demo scenario, traditional systems would miss the fraud because all credentials are legitimate.
StreamGuard's multi-agent approach catches it in <7 seconds:
- Detective detected
is_call_active = truevia session telemetry - Judge applied Policy 1: CRITICAL FRAUD → BLOCK (no human override)
- Enforcer created real Kafka quarantine infrastructure
- System triggered "Friendly Hold" with SMS notification
The verdict: Multi-agent orchestration + real-time streaming + structured output = significantly better than single-model classification.
That's what makes this architecture worth exploring.

Log in or sign up for Devpost to join the conversation.