-

-

Case1
-

Case2
-

Case3

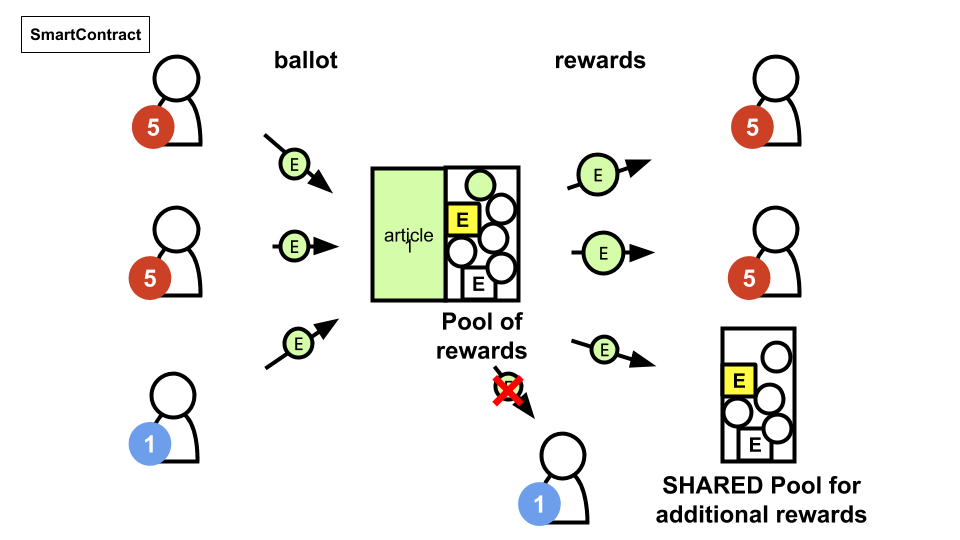


Description
Fact-check boards, curated and enforced through cryptoeconomics and open classification models.
Motivation
Content curation and classification today is obtuse and relies heavily on popularity indexes of posts in social-mediums where voting is trivial and the motivation of the curator is not known. The motivation for sharing content ranges from getting more likes/karma (dopamine fuel) to more sinister such as maniplating stock-markets, elections etc.
Popularity-indexes are broken-
because of manipulation and sensationalism sells. Popularity indexes are often the best metric for judging the accuracy of content.
Centralized tech censors content they don't agree with.-
Virtually all societies involve in censorship of contents and ideas which differs from their own. However big-tech is unparalleled in it's capability of censorship in that they can not only stop future discourse but also delete archives of the conversation ever having existed through a simple database delete.
The proposed solution-
At a high-level, content-curation is done through open-source models so that differing opinions can thrive but putting motivations in the open. Eceonomic incentives to create better accuracy indexes and stop spam and curation enforced through open classification models, so people can be more aware of the about the motivation behind the curated list.
Future work involves extending the system to allow virtually anyone to create their own content-curation boards by applying their own classification models.
Through this POC we have attempted to create a baseline to prove that such systems are indeed possible. We have created a simple curation-boards where every rating requires a collateral to be paid and every hour rewards are given to correct predictions.
High Level System structure--
The system consists of a data-aggregator backend. A classification-clustering pipeline to create Web Client UI to view ratings and provide ratings by participating in bounties.
Technical stack and APIs/Systems used--
The backend aggragtor searches queries for topics from a third-party newsapi service.
A production equivalent of this will aggragate data from a comprehensive list of sources maintained by open-source governance.
Sklearn/Spacy/Textacy based pipeline to extract key peieces of information from a news-stream which are subsequently put to vote.
Ethereum based smart-contracts for managing the collateral on rating and distributing rewards to entities which voted correctly.
Truffle/Ganache/Drizzle based development suite for developing the smart-contracts.
Amazon Web Services for computing.
ReactJS client.
NodeJS server middleware.
MongoDB based data storage.

Log in or sign up for Devpost to join the conversation.