-
-

Homescreen
-
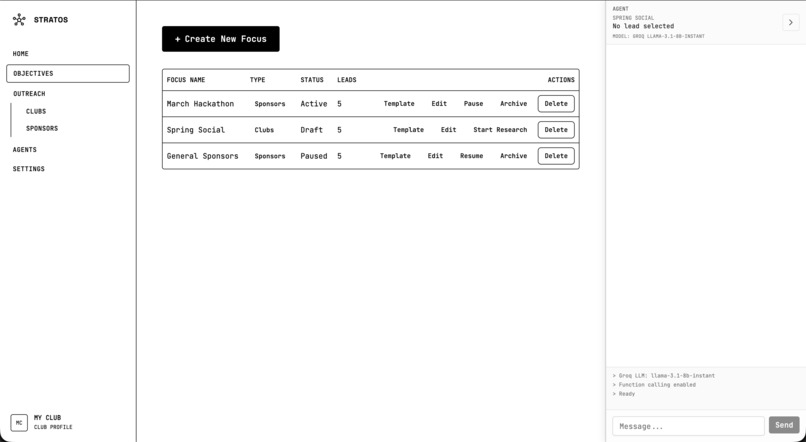
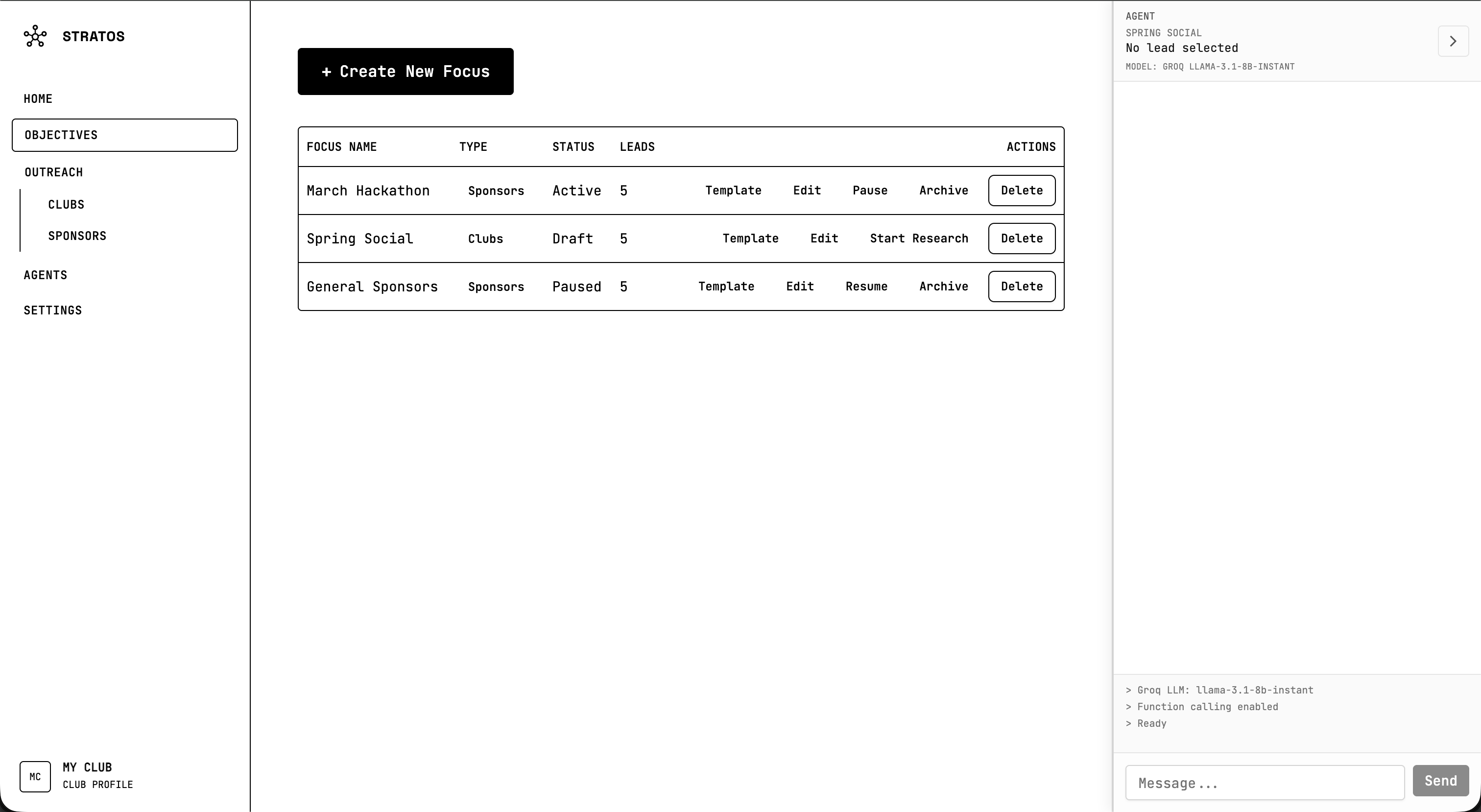
Objectives
-
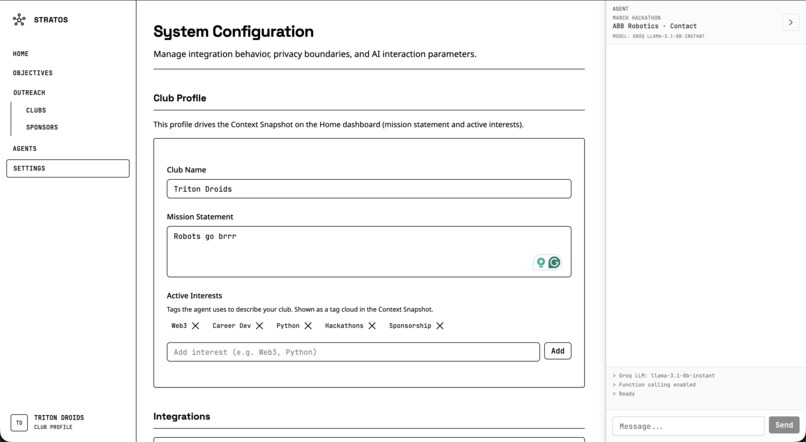
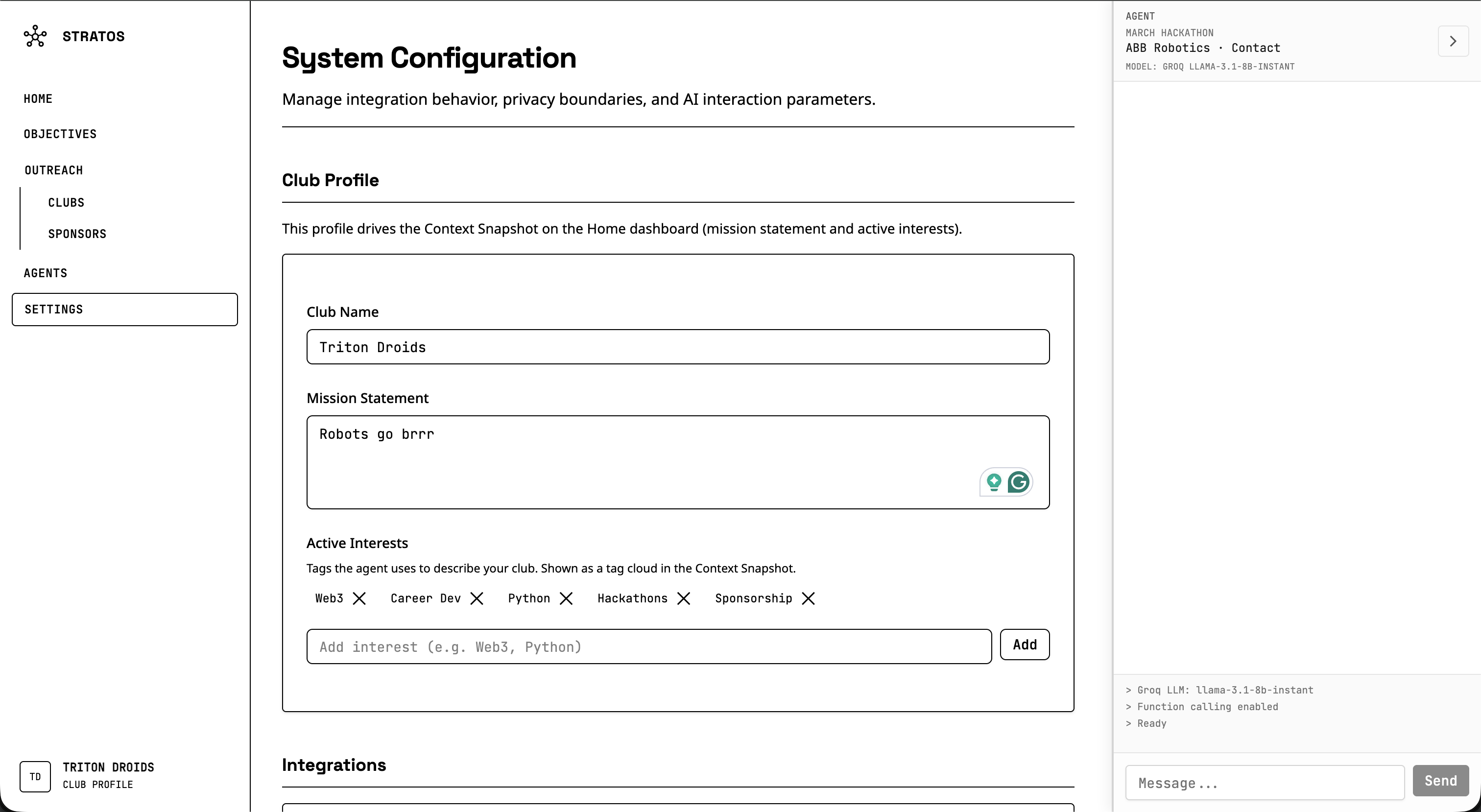
Settings
-
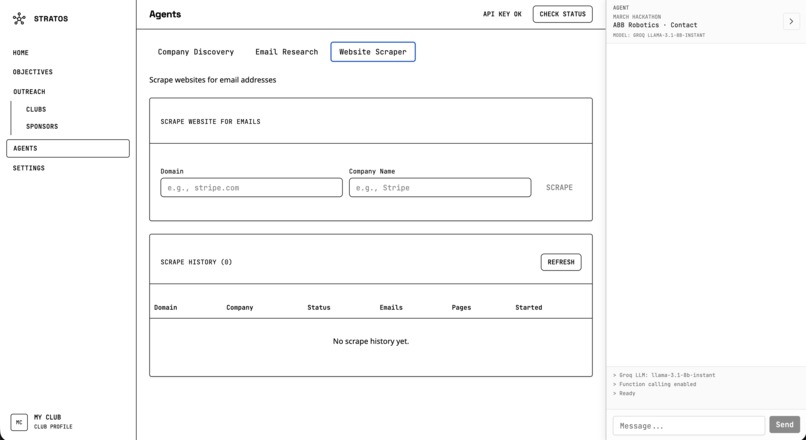
Specific website discovery
-
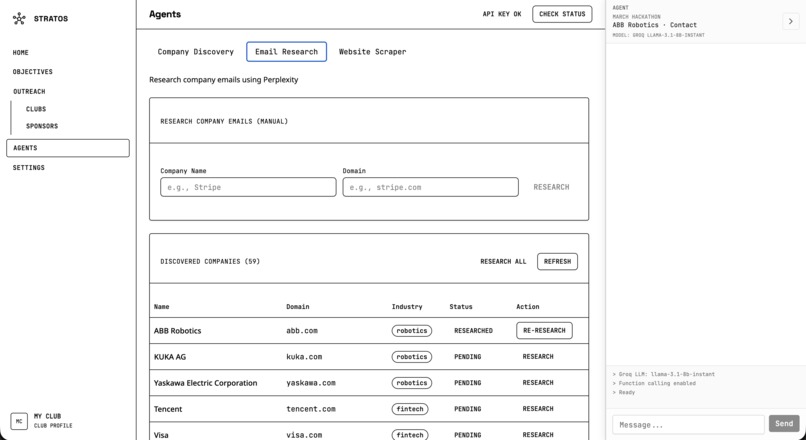
Emails and contact pages research
-
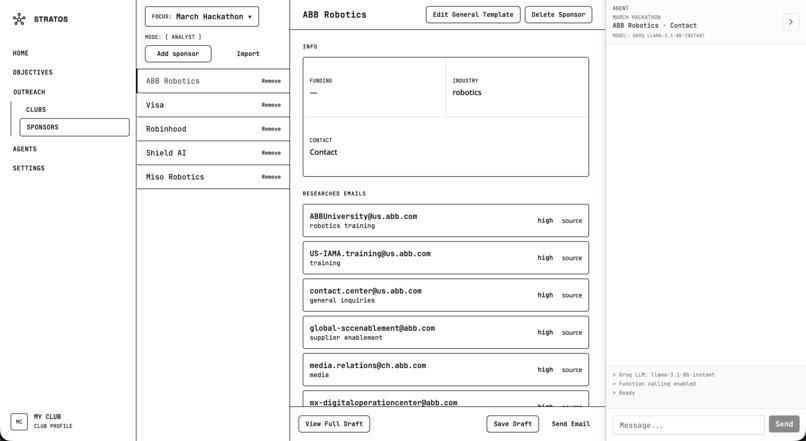
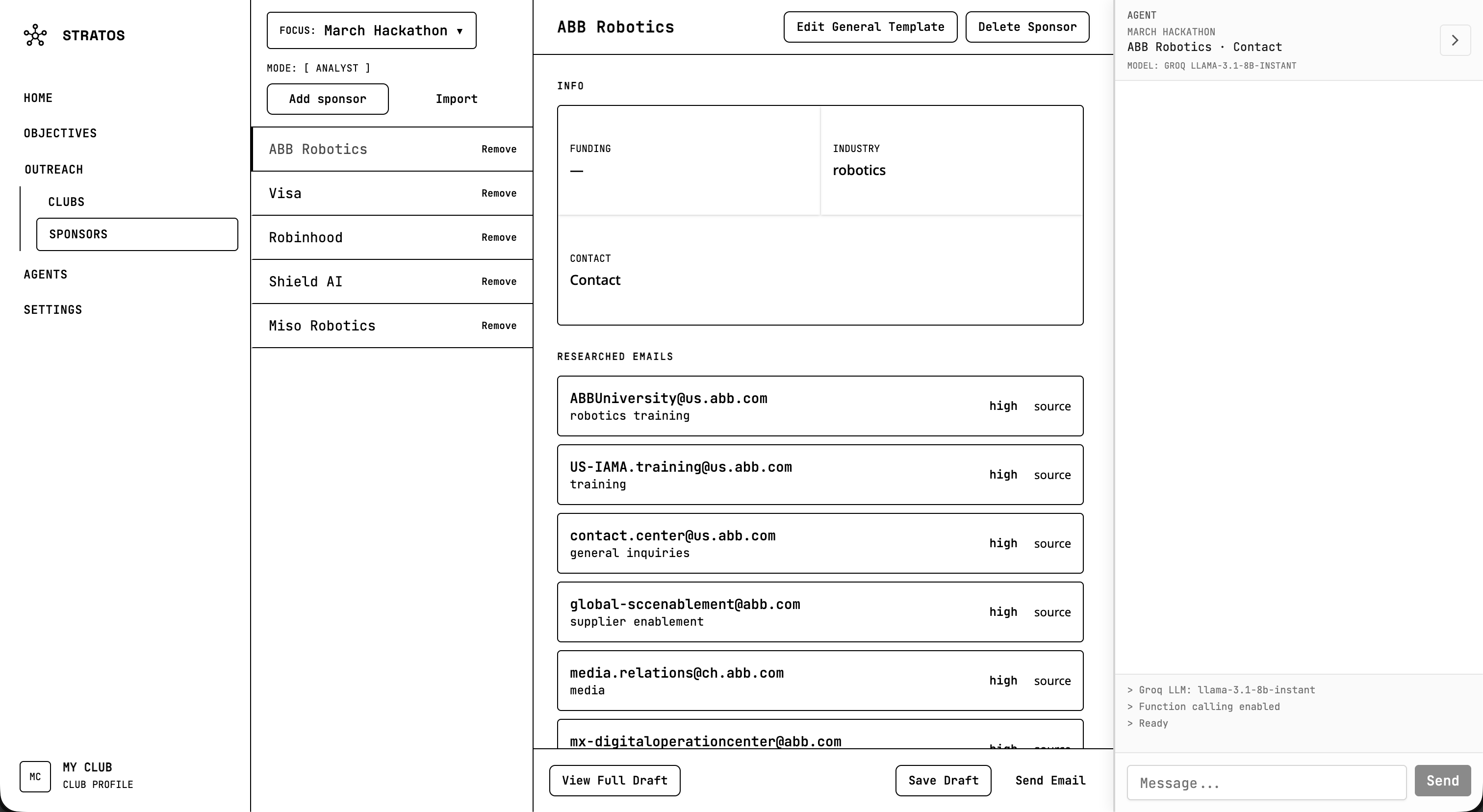
Sponsorships outreach
-
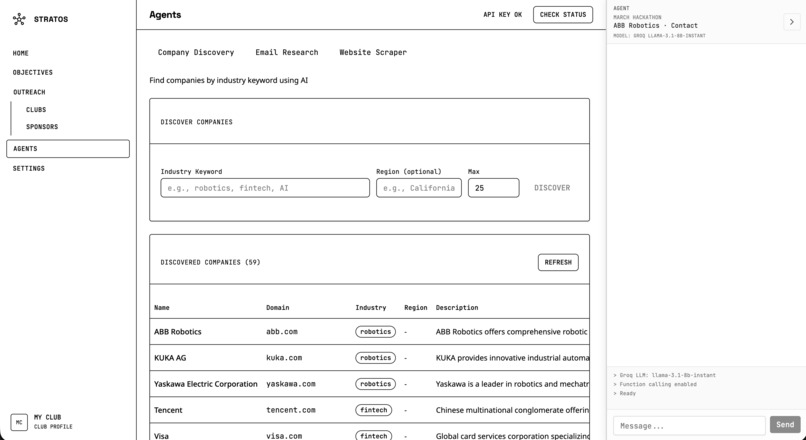
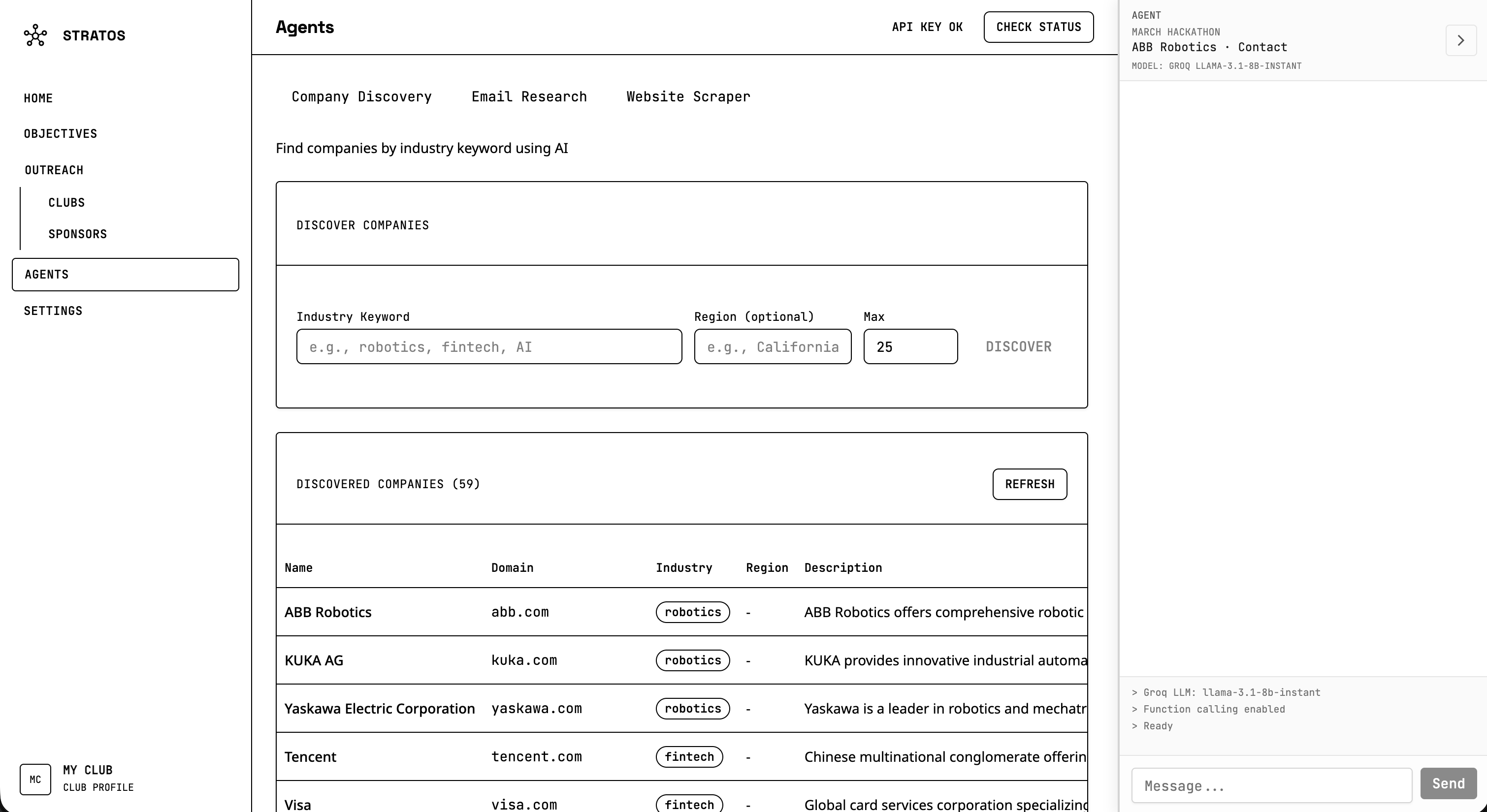
Company Discovery
-
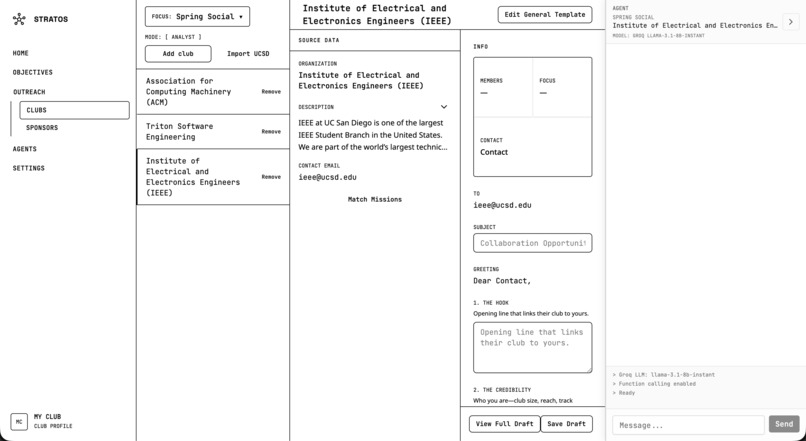
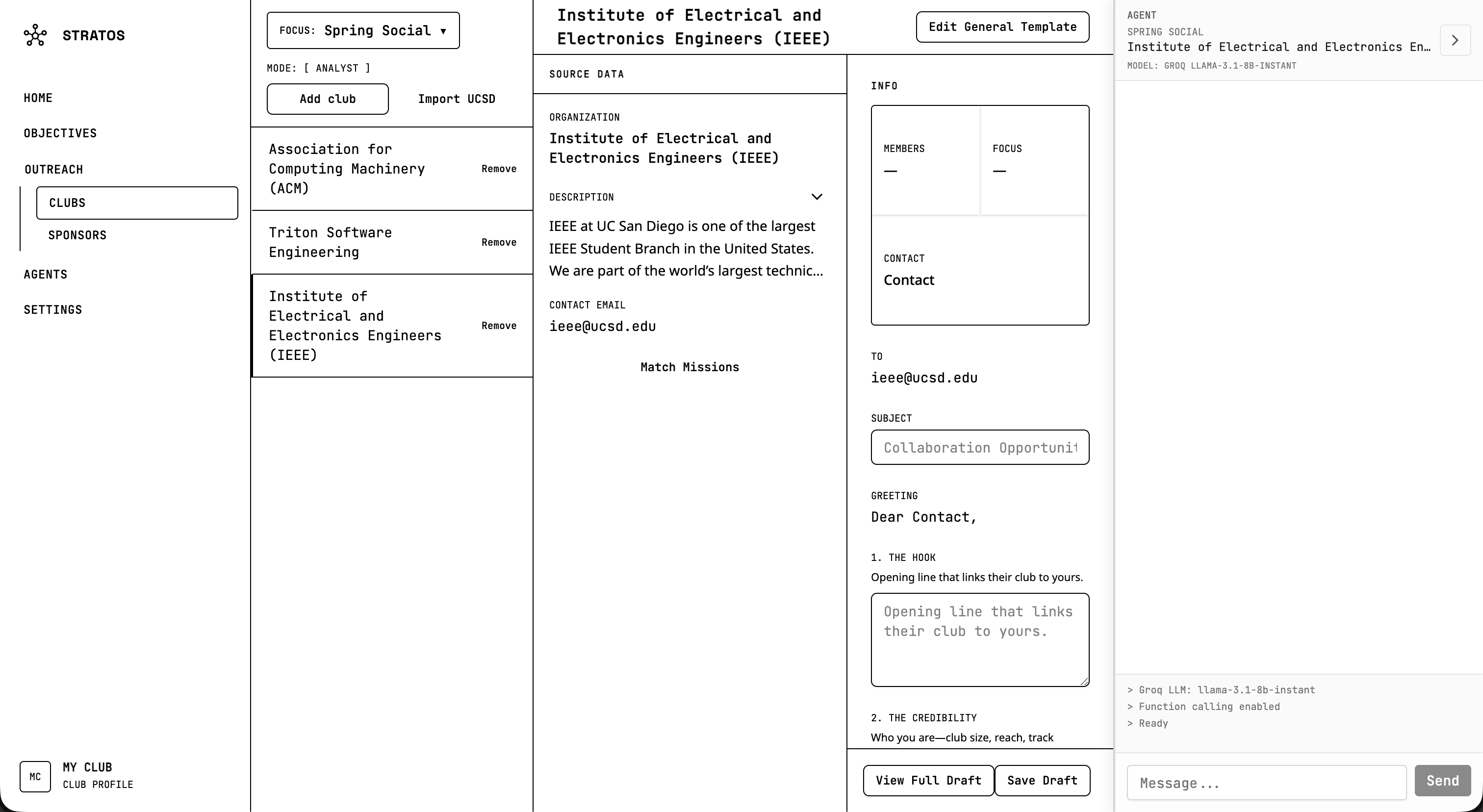
Clubs outreach

Inspiration
We're part of the Triton Droids club, and we kept running into the same problem: finding sponsors and partners takes a lot of time. Searching for companies, tracking down emails, and writing outreach drafts is slow, and our members are busy. We wanted to build an internal tool that makes this easier, so club members can do outreach without spending hours on manual work.
What it does
STRATOS is a Strategic Tailored Research and Agentic Team Outreach System. It’s a single app that lets you discover companies, research their contacts, and draft outreach.
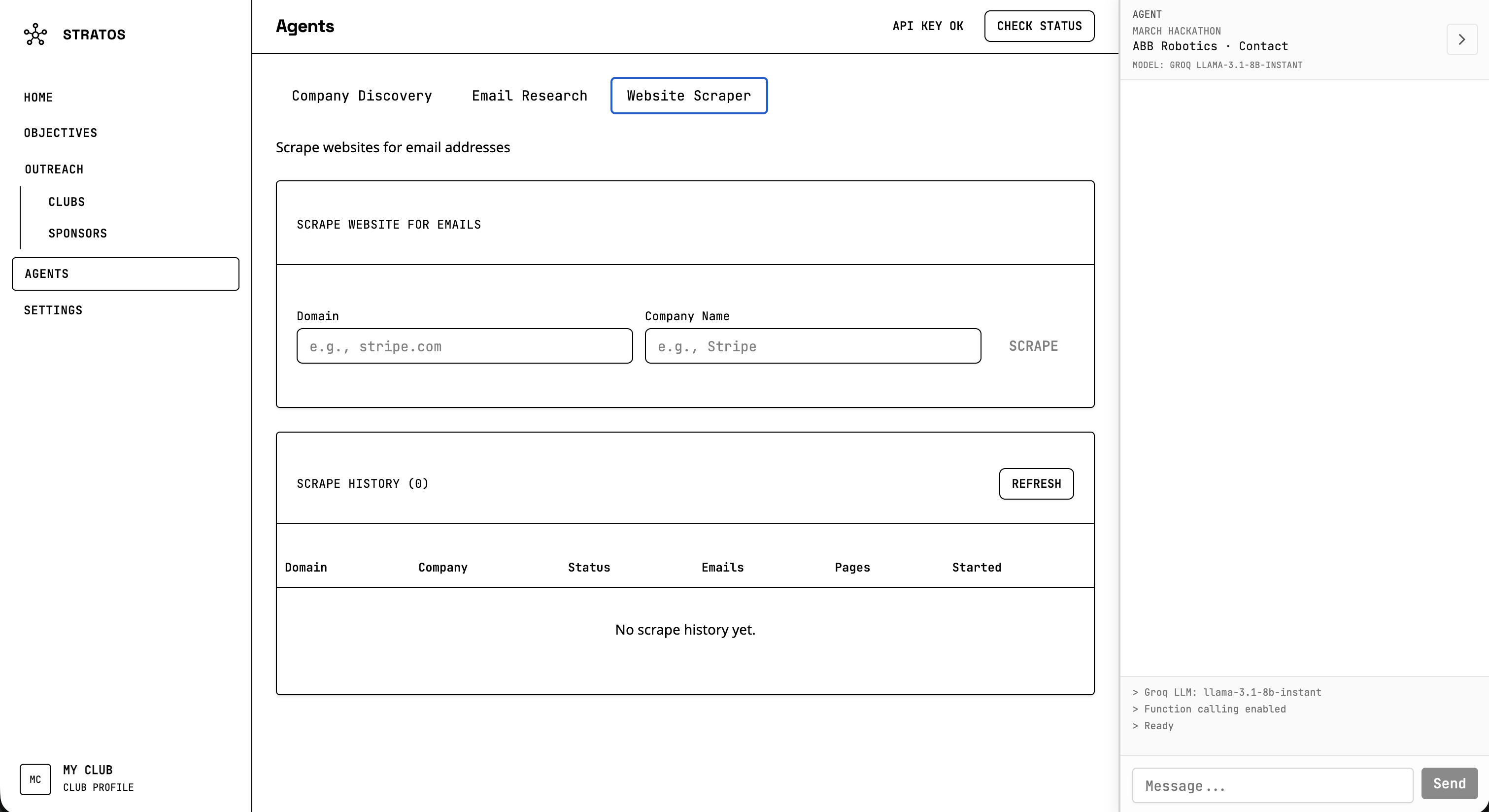
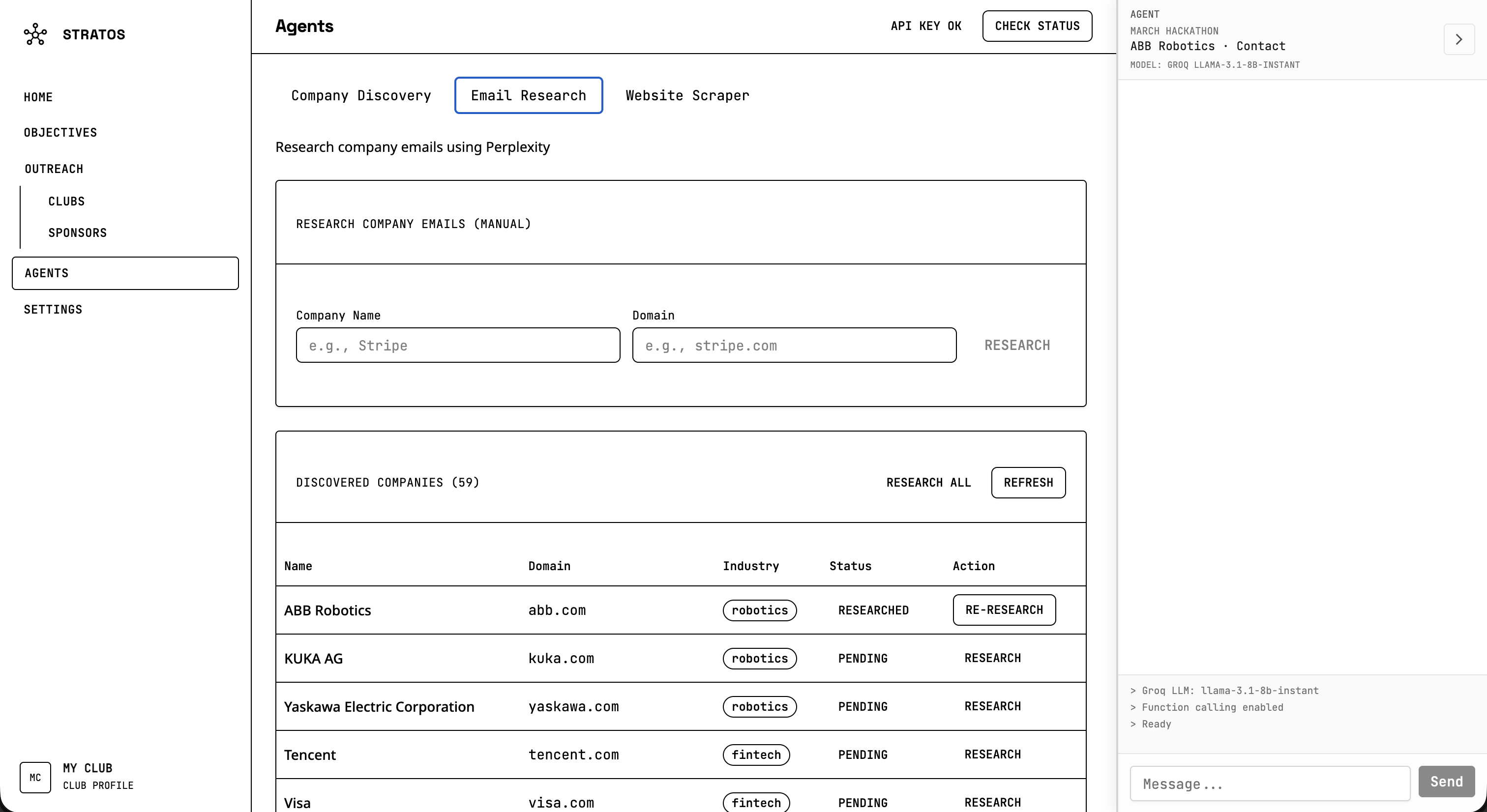
You talk to an AI agent in natural language. You can say things like “find robotics companies in California” or “research emails for Stripe,” and it will run the right tools. The agent can discover companies by industry and region using Perplexity, research contact emails from company sites, and scrape websites for emails. It can also add companies to a focus or objective, generate draft emails from your club’s templates, and navigate you to the right part of the app. You define the focus and objectives for each outreach campaign, track leads, and use template bricks to personalize drafts. A club profile gives the AI context so it can tailor suggestions and drafts to your club.
How we built it
We split the app into a frontend and a backend. The frontend is a React app built with Vite and TypeScript. We use the Groq API for the chat and LLM, with function calling so the agent can run multiple tools and chain them together. The backend is a Python FastAPI service that handles company discovery with Perplexity, email research, and web scraping with Selenium.
We use React Router for navigation, Tailwind CSS for styling, and shadcn/ui for components. The frontend calls the backend over HTTP, and we support both local development and production. The backend runs in Docker on Railway, with Chromium installed so Selenium can scrape websites. The frontend is deployed on Vercel, and we use env vars so it can talk to the deployed backend.
Challenges we ran into
We tried many ways to do company discovery and email research. Most commercial APIs were too expensive for us, and building our own web scrapers from scratch would have taken too long and been hard to keep running. We needed something cheaper and more maintainable. That pushed us to rethink the approach. We decided to use Perplexity as our research agent because it’s good at finding information and companies, and we combined it with Selenium for scraping when we needed to pull data directly from websites. That mix of AI research and targeted scraping ended up working well and kept our costs under control.
We ran into several deployment and integration issues. First, Railway returned 401 errors on some requests, which turned out to be deploy protection or auth settings we had to adjust. Then the frontend wasn’t hitting the backend correctly. Vite only reads environment variables at build time, so we had to add VITE_API_URL in Vercel and redeploy. Missing that meant the frontend was still calling localhost instead of the Railway backend.
We also had to accept that our SQLite database in the container is ephemeral. Data is lost when Railway redeploys, so we treat it as per-session storage. Supporting long-term persistence would require something like Railway Postgres or a volume.
Accomplishments that we're proud of
We're most proud of the agent system. The AI chat supports multiple tool calls in a single turn, and chains results back into the model so it can keep reasoning and acting. For example, you can say "find robotics companies in California and add the top two to my focus," and it will discover, run the tools, feed the results back, and decide what to do next. That loop runs up to five iterations, so it can handle multi-step workflows without stopping after one action.
We also built a fallback for when the LLM returns function calls in plain text instead of the structured format. We implemented balanced-brace JSON parsing to pull out function names and arguments from that text, so the agent still works even when the API format changes or misbehaves.
On the backend, we combined Perplexity for discovery and research with a Selenium scraper for direct site access. Discovery uses a structured prompt to get companies as JSON, and email research uses Perplexity to find contact emails with source URLs and evidence. The scraper then crawls sites in headless mode, extracts mailto links and emails with regex, discovers contact-related pages, and filters false positives. Getting Selenium and Chromium running inside our Docker image on Railway was one of the trickier parts.
We also implemented a modular template system with bricks for greeting, hook, credibility, meat, and CTA, plus variable substitution for things like lead names and company details. The agent can add companies to a focus and generate drafts from those templates, so the full flow from discovery to outreach is handled in one place.
We're also proud of shipping it end-to-end: frontend on Vercel, backend on Railway with Docker, and proper configuration so the deployed frontend talks to the deployed API in production.
What we learned
We learned that state flows through many context providers. Club profile, active focus, selected lead, agent bridge, and LLM config are all passed through React context, so the agent always has the right context when running tools like add_to_focus or apply_template. Getting that wiring right took some iteration.
We also learned how tool chaining works with the Groq API. The assistant message has a tool_calls array, and each tool result is returned as a separate tool message with a tool_call_id. The agent loop keeps sending those back until the model returns text only. We also built a fallback parser with balanced-brace JSON extraction for when the LLM returns function calls in plain text instead of structured tool calls. We learned that Vite environment variables are fixed at build time. The frontend reads VITE_API_URL during the build, so changing it in Vercel requires a redeploy. We had to figure that out when the frontend kept calling localhost in production.
On the backend, we learned how to run Selenium inside Docker. Chromium and chromedriver are installed in the image, and we use CHROME_BIN and CHROMEDRIVER_PATH so the scraper picks up the system browser in the container instead of relying on webdriver-manager at runtime. We also learned that the frontend uses localStorage for focus, club profile, and LLM config. There’s no backend for user data, so everything lives in the browser. The backend’s SQLite is ephemeral in the Railway container, so discovery and research data are lost on redeploy.
What's next for STRATOS
We want to add persistent storage. Right now, focus and leads are in localStorage, and discovery and research results live in ephemeral SQLite. We’d add a backend with something like Railway Postgres or Supabase, so campaigns and leads persist across sessions and redeploys.
We want to wire up the integrations that are stubbed. Objectives have pinned context sources for Google Drive, Calendar, and website, and Settings shows Google Drive and Calendar as “Not connected.” We’d implement OAuth and sync so the agent can use real context from those services.
We want to add AI hook generation. AIHookBlock has a “New Variation” button and a placeholder for “AI will generate the hook,” but it doesn’t call the LLM yet. We’d add a hook-generation tool that takes the selected lead and focus and returns personalized opening lines.
We want to improve email sending. Today, we open Gmail’s compose URL with pre-filled fields. We’d like to add send-from-app (e.g,. via Gmail API or Resend) and basic tracking of sent emails and replies. We’d expand the Clubs flow. It uses ucsd_organizations.json for club discovery. We’d make that data updatable, add club-specific research, and extend it beyond UCSD.
Finally, we’d add response and pipeline tracking. Focus has pipeline stages (researching, review, waiting, closed), but there’s no real link to sent outreach or replies. We’d track what was sent and when, and surface reply and bounce info in the pipeline.

Log in or sign up for Devpost to join the conversation.