-
-
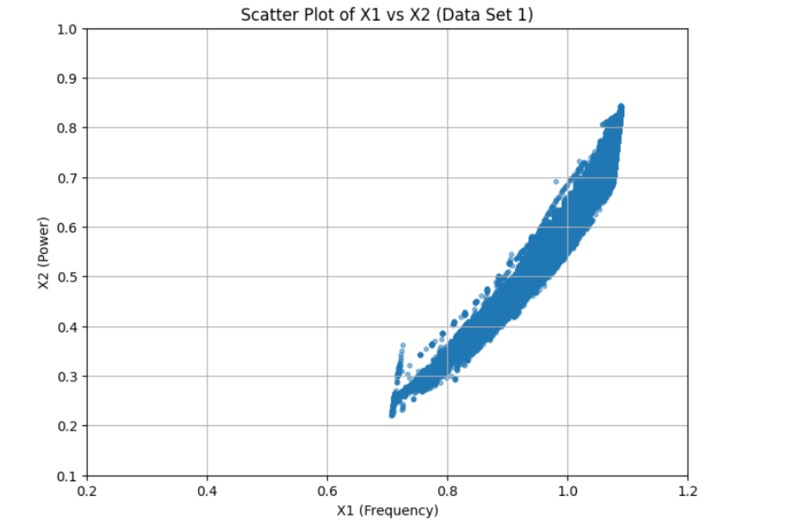
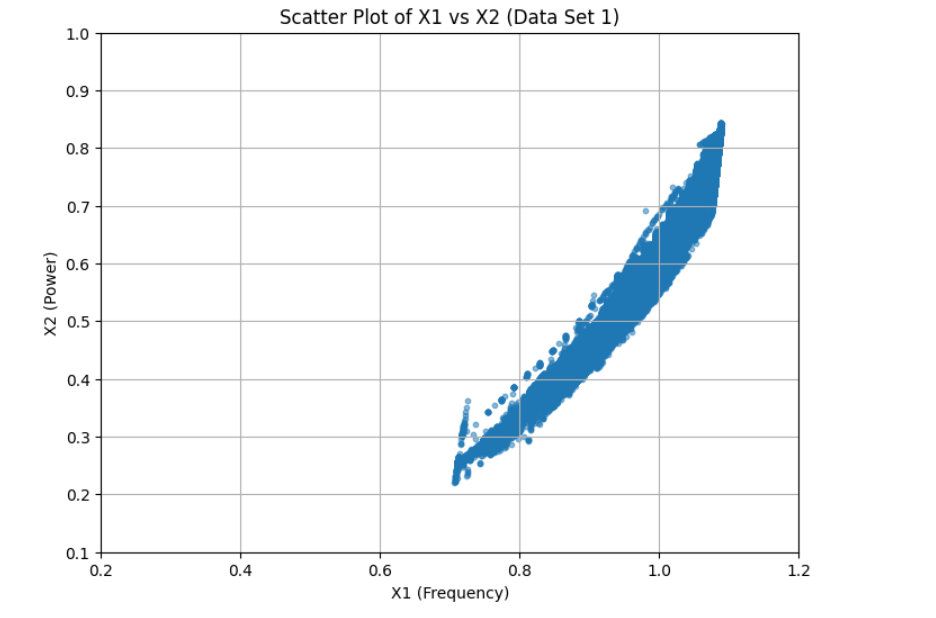
dataset_1
-
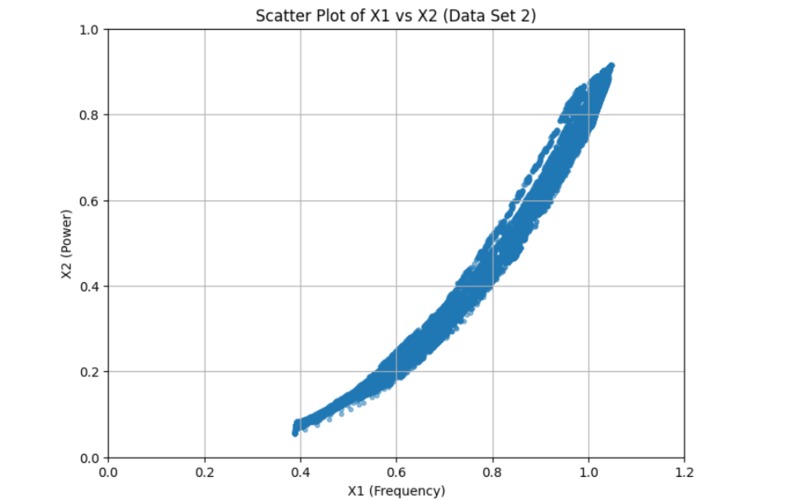
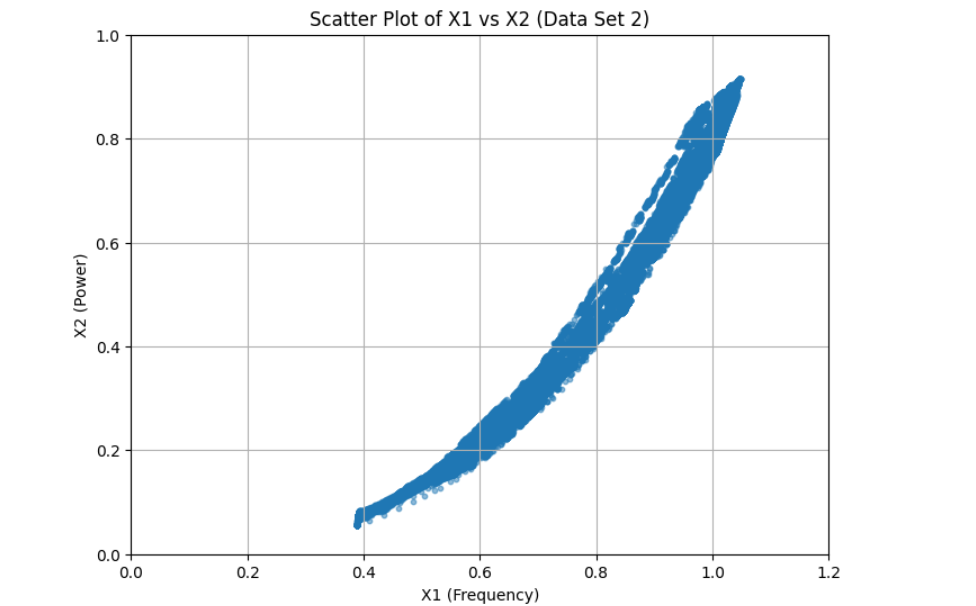
dataset_2
-
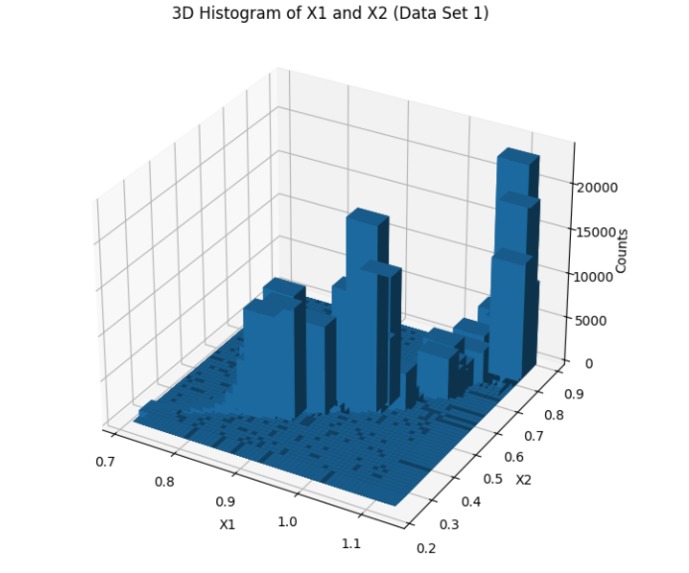
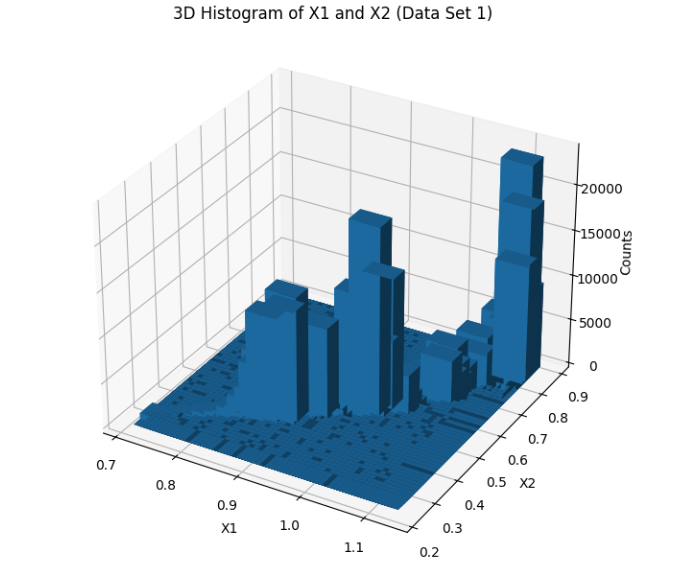
dataset_1_histogram
-
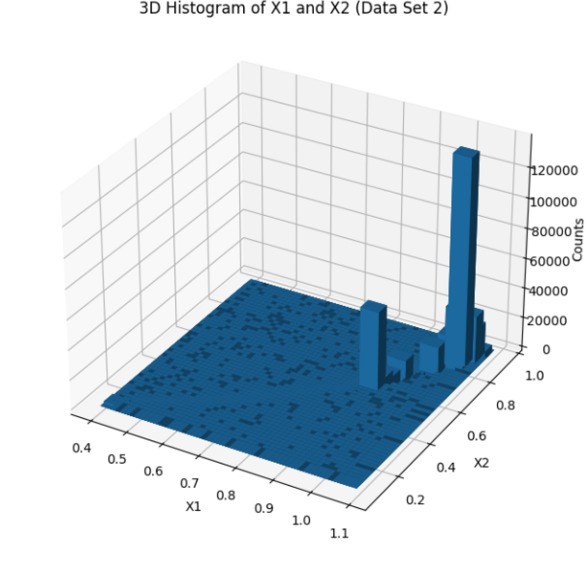
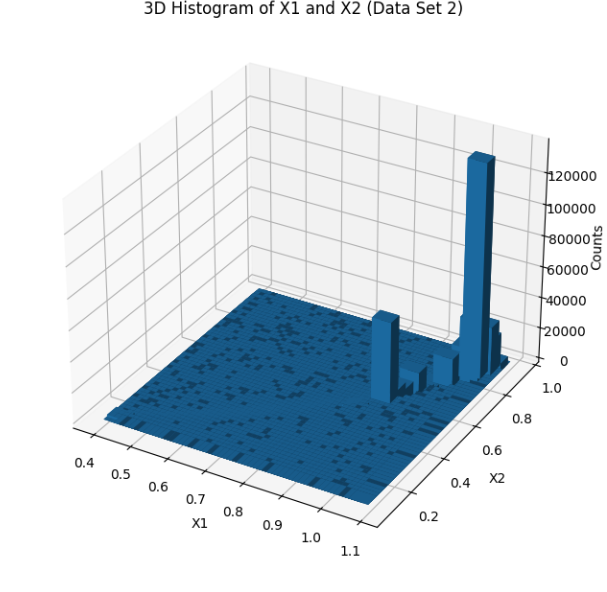
dataset_2_histogram
-
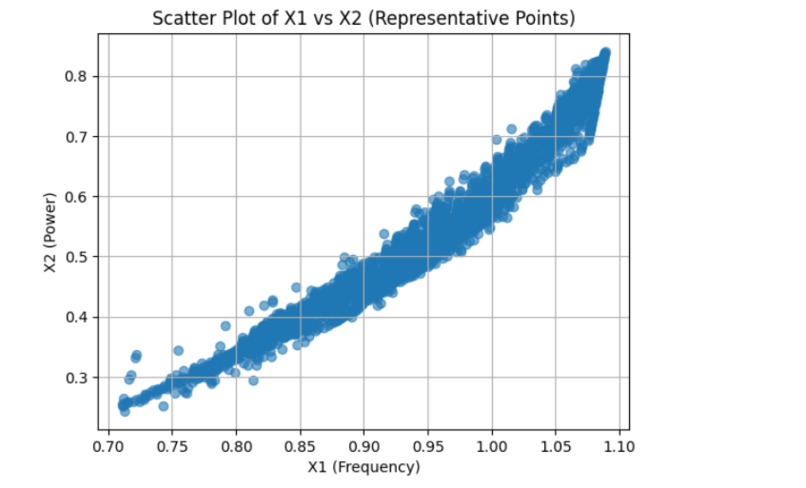
dataset_1_method1
-
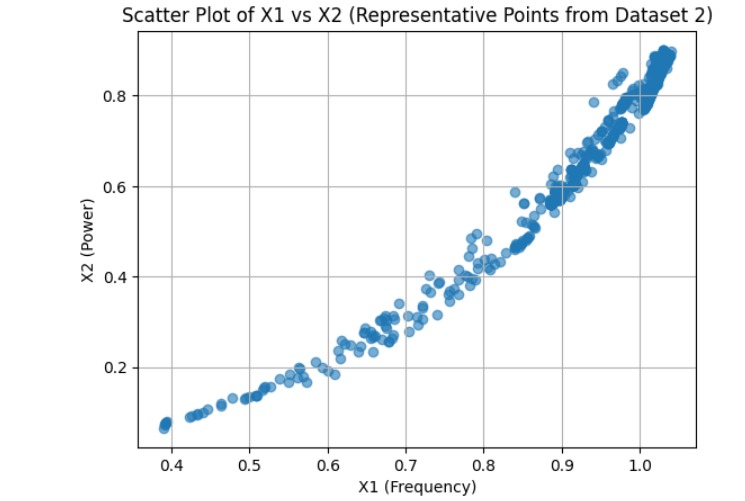
dataset_2_method1
-
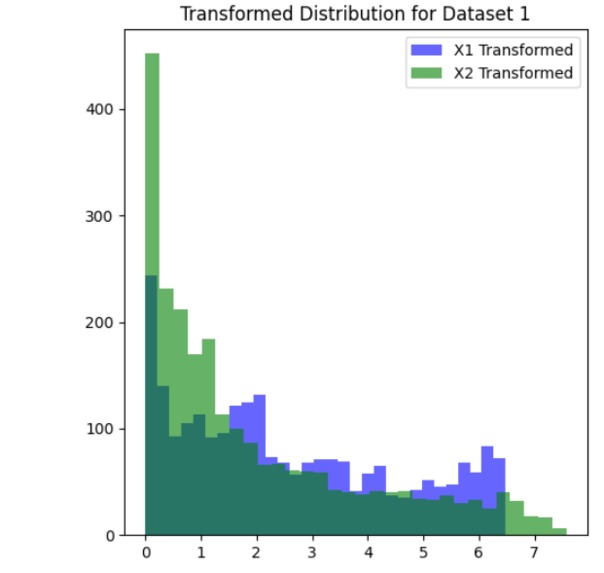
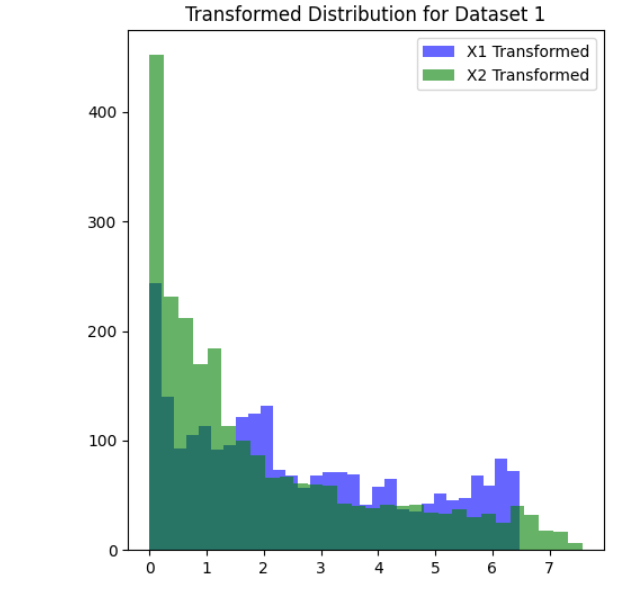
dataset_1_transformed_distribution
-
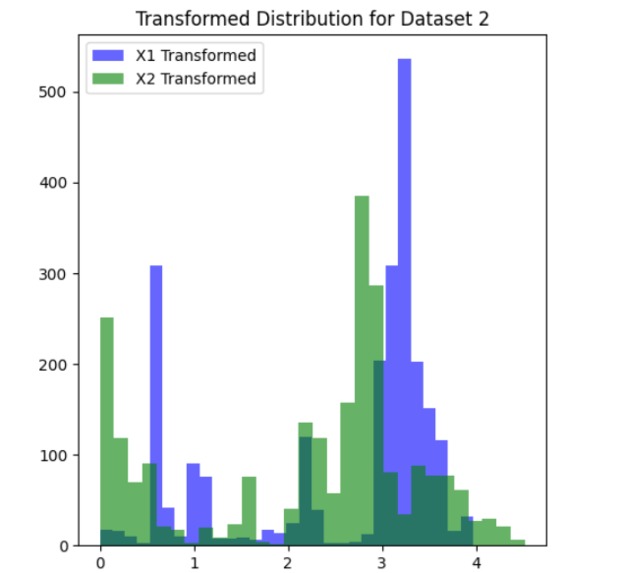
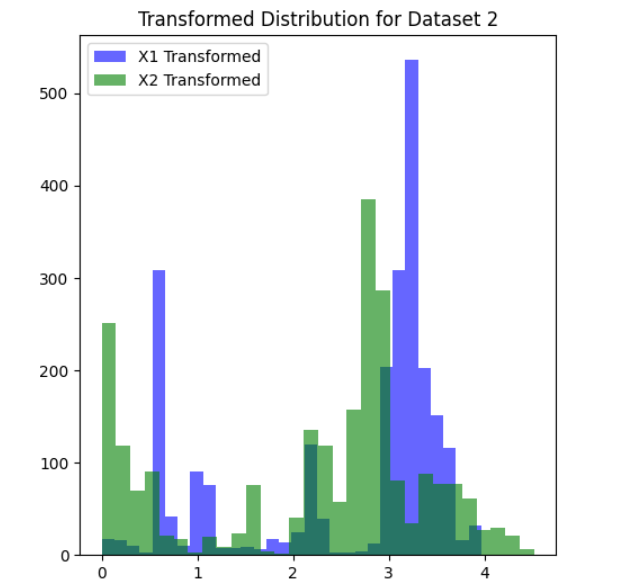
dataset_2_transformed_distribution
-
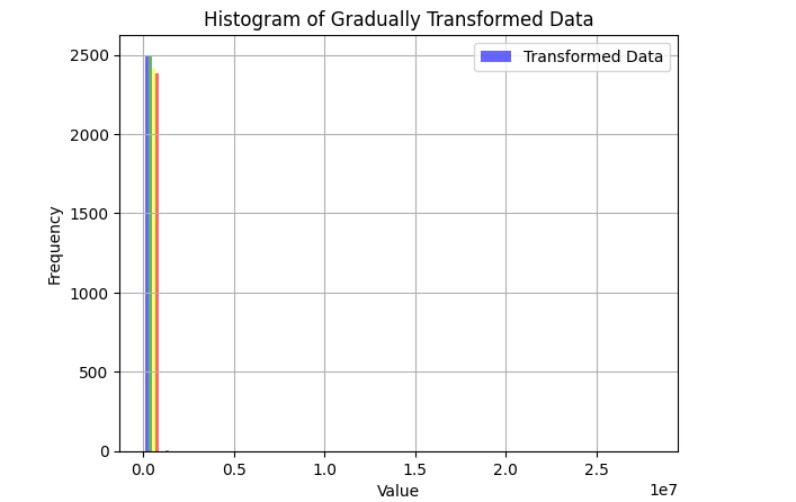
dataset_2_transformed_histogram
-
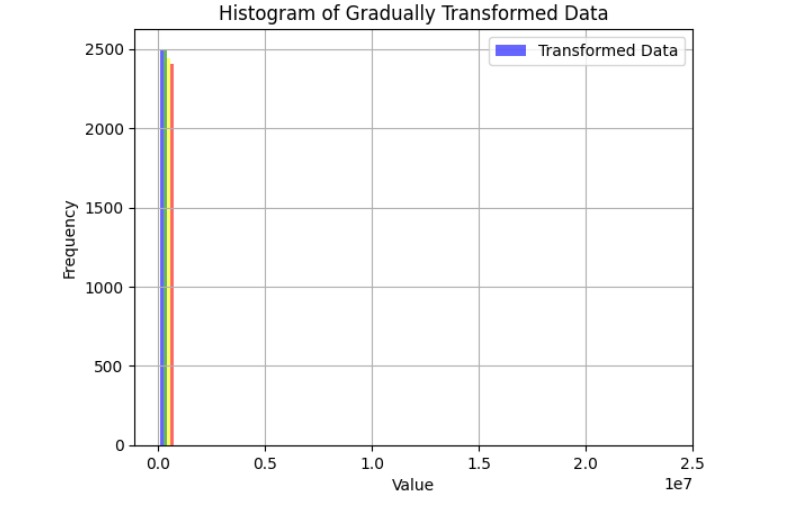
dataset_1_transformed_histogram


Inspiration
The inspiration for this project came from the growing need for effective, data-driven monitoring systems that can predict equipment health and prevent costly failures. Electric motors are critical components in many industrial applications, and their downtime can lead to significant operational losses. By developing a data-selection algorithm for motor health monitoring, we aimed to create a model that could accurately track motor performance, detect early signs of degradation, and ultimately increase reliability and safety. The challenge of working with large datasets and finding an efficient way to train a predictive model on a manageable subset was both inspiring and intellectually rewarding, pushing us to innovate our approach to data sampling and clustering.
What it does
This project focuses on creating a condition monitoring system for an electric motor. It collects real-time measurements of frequency (X1), power (X2), and vibration level (Y) to establish a baseline model of the motor's healthy operating state. The system then monitors these parameters over time, using a machine learning model to detect deviations from the baseline that may indicate potential health degradation. By selecting a representative subset of data from a large dataset, the project allows the model to efficiently track motor health without requiring an impractically large amount of training data.
How we built it
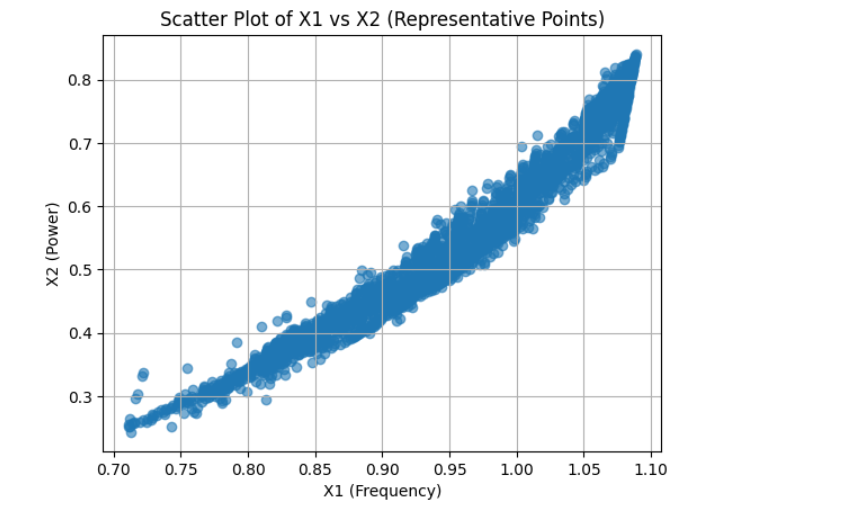
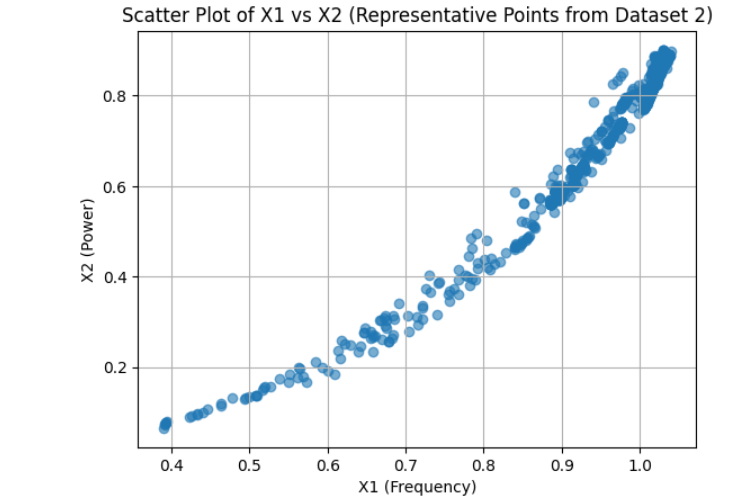
We started by loading and exploring the original dataset of 500,000 data points, which included measurements of frequency, power, and vibration. Visualizations in scatter plots and 3D histograms helped us understand the distribution of data points across different operating conditions. To make the data suitable for clustering, we normalized the values of frequency (X1) and power (X2). Given the large dataset, we then applied an initial sampling step, reducing the dataset to 50,000 points to make the clustering process computationally feasible. We used KMeans clustering with 2,500 clusters to group similar operating conditions together. For the final selection, we chose one representative point from each cluster, resulting in 2,500 data points that covered both frequent and less common operating conditions. We then validated the selected points through scatter plot visualization and further adjusted parameters to ensure flexibility in the model.
Challenges we ran into
One of the main challenges was managing the sheer volume of data. With 500,000 data points, it was computationally expensive to run clustering algorithms directly on the full dataset. This required us to experiment with different sampling and clustering methods until we found a balance that was both efficient and representative of the full operating range. Another challenge was ensuring that the selected 2,500 points provided comprehensive coverage across high-density and low-density regions. We needed to fine-tune the KMeans clustering parameters and adjust the data selection criteria to achieve this balance, which required significant experimentation and testing.
Accomplishments that we're proud of
We’re proud of designing an efficient data-selection algorithm that effectively captures the motor’s operational patterns with just 2,500 representative data points. This approach not only makes the model training process feasible but also ensures high accuracy in health monitoring. Additionally, by developing visualizations that confirmed our model’s coverage across operating conditions, we validated that our solution addressed the project’s objectives comprehensively. This project demonstrates how thoughtful data selection can lead to powerful, efficient models for predictive maintenance.
What we learned
Throughout this project, we learned the importance of data preparation and visualization in designing effective machine learning models. The exploration and normalization steps were critical to understanding our data, while clustering techniques taught us how to balance data efficiency with representativeness. We also gained insights into the trade-offs between computational resources and data coverage, learning that it’s possible to train reliable models with significantly reduced data, as long as the data is well-chosen. This experience has deepened our understanding of clustering algorithms, especially in the context of predictive maintenance applications.
What's next for Stratified Sampling & Clustering for Motor Health Monitoring
Moving forward, we’d like to integrate real-time data streaming into the model so it can continually update as new data comes in, making the health monitoring system even more responsive. We’re also considering exploring other clustering algorithms, like DBSCAN or hierarchical clustering, to see if they can provide even finer control over the selection of representative points. Additionally, we plan to test this approach on other types of equipment and expand its use to multi-variable systems where more than two features are monitored. This project has significant potential to evolve into a robust tool for predictive maintenance in various industrial applications.

Log in or sign up for Devpost to join the conversation.