-
-
Strata UI
Strata: Community Memory
One post. Four witnesses. None in the same thread.
Inspiration
In 2018, a cyclist was struck in a hit-and-run in Washington state. Police had one clue: a piece of black plastic from the vehicle. A trooper posted photos online. Someone cross-posted it to r/whatisthisthing. Within two hours, a state vehicle inspector identified the exact make and model from that fragment. Five days later, the driver was arrested.
In 2024, someone posted a photo of a suspicious electrical outlet to Reddit. Forty minutes later, a user identified the exact hidden camera model and linked the product page.
These aren't anomalies — they're proof of something Reddit does better than any other platform: distributed knowledge. Different people, each holding one piece — a fragment of a plate, a timestamp, a location — posted in threads that will never cross paths.
But here's what should bother every moderator: these cases succeeded by luck. Someone happened to cross-post. Someone happened to have the exact right expertise. Someone happened to be reading that thread at that moment.
For every case Reddit solves, there are hundreds where the evidence existed — scattered across threads, posted days apart, never connected. A scam victim posts a phone number; three others reported the same number in different threads last week. A coordinated group pushes a narrative across a case thread. A previously-removed pattern resurfaces from a new account.
The community already produced the evidence. The moderator just can't see it — because Reddit has no memory across threads.
Strata gives communities that memory. Not by luck. Systematically.
The Devvit platform fits this problem precisely. Reddit-native triggers provide real-time ingestion without polling. Redis serves as the persistence layer for embeddings and entity indices. Custom posts deliver the full dashboard inside Reddit — no external link, no separate login, no context switch. The challenge wasn't the model; it was the infrastructure: entity resolution at scale, hub suppression, cross-thread retrieval semantics, egress budgeting. We focused on the intelligence layer.
What it does
Strata is a real-time cross-thread intelligence engine for Reddit moderators. It ingests every post and comment, embeds them semantically, extracts linkable entities, and fuses both signals to surface connections that no human could find by reading threads — all inside a native Devvit custom post.
It operates in three modes:
Surface — buried connection discovery. When a new post arrives, Strata retrieves candidates via hybrid entity + cosine retrieval (Reciprocal Rank Fusion, cross-thread prioritized), classifies each relationship with an LLM, and delivers an alert linking the anchor to related posts scattered across the subreddit. Each connection carries a classification (CONFIRMS / UPDATES / TEMPORAL / CONTRADICTS), confidence tier, and one-line reasoning. Moderators see not just that items are connected, but why — with shared entities highlighted across panes.
Flag — proactive violation detection. Three parallel checks on every item:
- Rule enforcement: item embedding vs. configured rules → LLM recommendation → mod queue report with reason.
- Pattern matching: cosine similarity to previously-removed items → LLM confirms the pattern repeats → mod queue report with precedent IDs.
- Brigade detection: ≥3 distinct authors within a 4-hour window, semantic uniformity ≥0.45, density ≥0.5 → dashboard flag alert with participating accounts and the coordinated narrative identified.
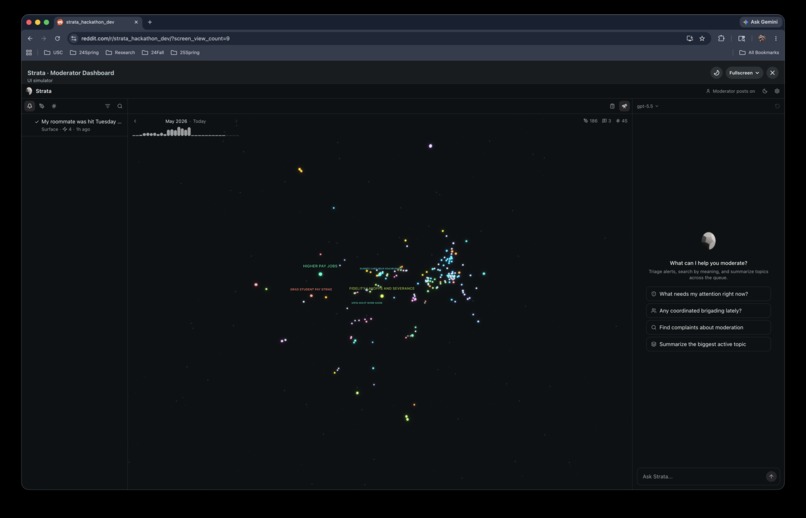
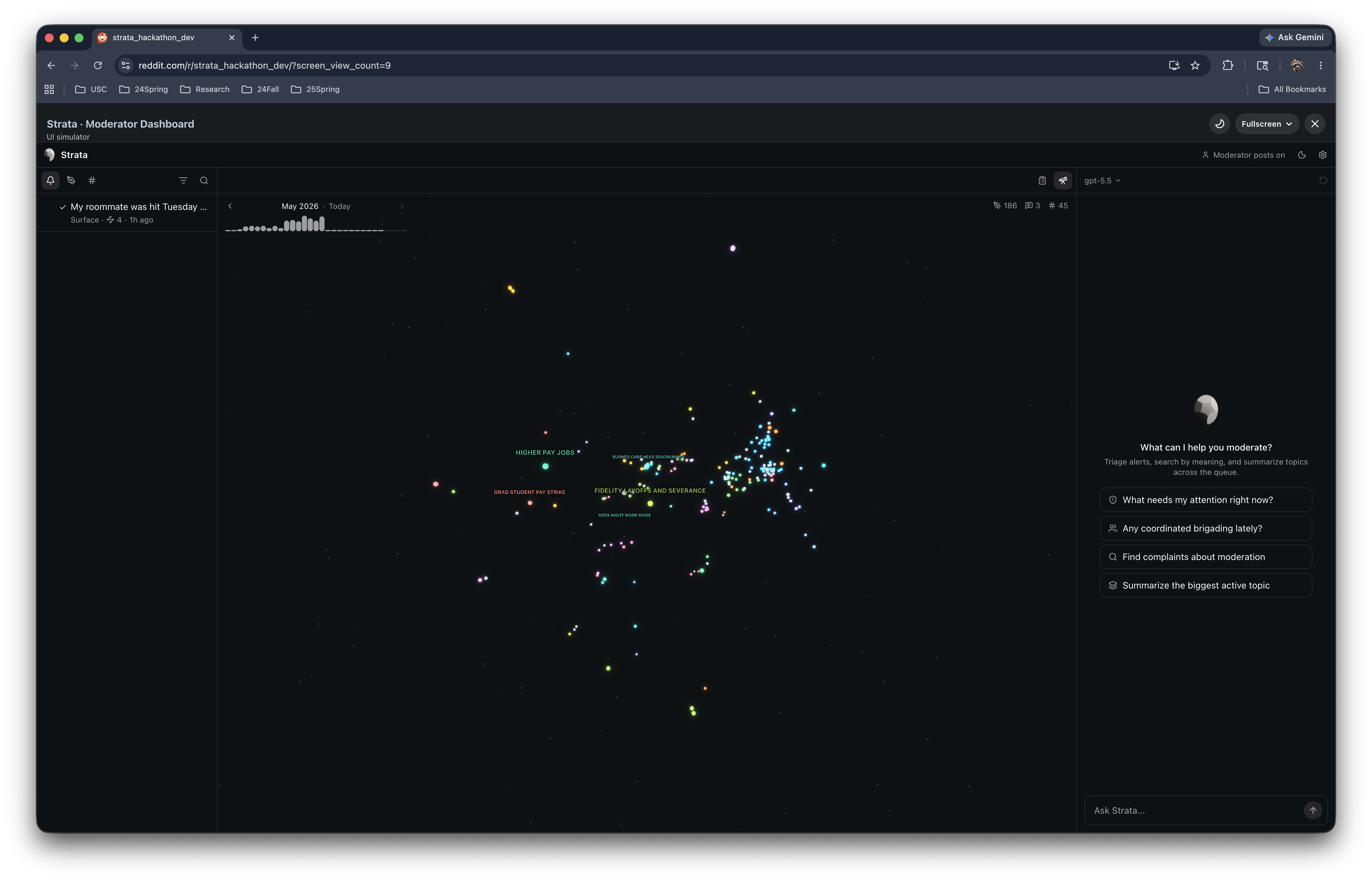
Explore — community topology. Louvain clustering over a KNN cosine graph, UMAP 3D projection, LLM-generated topic labels. Moderators see what the community is discussing, how topics evolve, and where activity concentrates — rendered as an interactive Three.js 3D graph inside the dashboard.
Supporting infrastructure:
- Batch backfill: ingest historical content via OpenAI Batch API (chunked, egress-aware, with automatic retry and backoff).
- Scan: post-backfill full-corpus cross-reference that builds entity-linked candidate pairs and classifies them in parallel — discovering connections in existing content, not just new posts.
- AI chat assistant: SSE-streamed tool-use agent (GPT-5.5) with access to alerts, items, topics, and threads. Moderators can ask natural-language questions about their community's content and get actionable answers with navigation side-effects.
- Compose & publish: mods can turn any surface alert into a community-facing story post summarizing the timeline — turning scattered evidence into community engagement, directly from the dashboard.
Why this matters: from gatekeeping to community leadership
The standard mod toolkit — AutoMod regex, keyword bots, manual queue review — operates one item at a time. It's reactive. It's invisible to the community. And it doesn't scale to cross-thread intelligence.
Community engagement through synthesis. When scattered reports converge on the same entity — a phone number, a vehicle description, a username — Strata doesn't just flag it for mods. It lets them inform the community by publishing a synthesized timeline as a story post. Moderators go from invisible gatekeepers to visible community leaders who connect the dots and keep people informed. This is the difference between "content moderation" and "community leadership."
Coordinated manipulation defense at the community level. Brigades, astroturf campaigns, and coordinated narrative pushes are invisible when viewed one comment at a time. Strata detects them structurally — semantic uniformity + temporal density — and surfaces the pattern so mods can act with evidence, not just suspicion.
Institutional memory that outlasts any individual. Moderation teams turn over. When a veteran mod leaves, their pattern recognition goes with them. Strata makes "we removed that kind of post before" into something that lives in the system. Every removal decision strengthens future pattern detection. The community's moderation intelligence becomes self-reinforcing.
Project Impact — target communities
r/Scams (~1.3M subscribers) — Scammers reuse infrastructure: the same phone numbers, crypto wallet addresses, and URLs appear across dozens of victim posts over weeks. Each victim posts in isolation. Strata links all mentions of a shared identifier, surfaces the cluster to mods, and flags new posts that reference any entity in an existing scam network. Scattered victim reports become a documented operation map that mods can pin as a community warning.
r/UnresolvedMysteries (~4.5M subscribers) — The core value of this community is cross-thread intelligence. A detail mentioned in one post (a vehicle description, a location, a partial identifier) might connect to another post that no one thought to link. Strata makes this systematic: entity matches surface across the full history, so connections that currently depend on one reader's memory appear automatically.
r/boston (~770K subscribers) — City subreddits face scattered community reports about the same local issue (a dangerous intersection, a problem landlord, a business violating codes) that never get connected, plus coordinated account activity during elections. Strata links geographic entities across threads and detects in-thread coordination, helping mods publish consolidated community intelligence posts.
How we built it
A seven-stage real-time pipeline plus three background jobs, entirely within the Devvit platform:
- Normalize — whitespace, unicode, smart quotes collapsed to a canonical form.
- Embed —
text-embedding-3-smallat 256 dimensions. Int8 scalar quantization for Redis storage (~3× compression, negligible quality loss at this dimensionality). - Extract —
gpt-5.4-ministructured output. Nine entity types: person, location, object, organization, phone, email, url, username, quantity. Atomized: each distinguishing feature is its own entity. Hub suppression filters entities that appear in >3% of items for their type. - Entity embed — embeddable types (object, person, location, organization) get their own 256d vectors for semantic entity matching. String-only types (quantity, url, username, phone, email) use Dice coefficient with identifier-aware normalization.
- Retrieve — hybrid: entity filter (IDF-weighted, type-aware) + cosine safety net (scaled to 2% of corpus, capped at 300). RRF merge. Cross-thread items surface first; in-thread items rank behind since they're already visible to the moderator.
- Classify —
gpt-5.5with low reasoning effort. Batch classification: one call classifies all candidates against the anchor. Strict JSON schema output with relationship type, confidence, and reasoning. - Alert — entity bridging identifies which named entities link anchor to each connection (token overlap + substring + embedding). Alert stored with per-connection entity annotations and cluster IDs for cross-pane highlighting.
Background jobs (Devvit scheduler):
ingest-batch: chunked batch/real-time backfill with egress backoff.scan: full-corpus entity-pair classification, 20 anchors per tick.recluster: Louvain + UMAP + LLM labeling, auto-triggered at 5% volume growth.
Storage is Redis-only: items hash, quantized embeddings hash, time-sorted index, entity indices per type, entity embeddings per type, alert sorted set, cluster metadata. No external database. Deploys as a single Devvit app install — one click from the App Directory.
Challenges
Validating a system where real signal is rare. Cross-thread connections surface once a week or month in a real community — you can't iterate by waiting. We built a 10,044-item benchmark from real r/boston content, planted 4 buried witnesses across unrelated threads, and added 4 adversarial decoys sharing surface attributes but not a real-world referent. Result: 3/4 witnesses surface in the top 15, zero decoys classified as related, consistent across 10 trials.
Separating referents from topics. Most entity matches are topical noise — hundreds of posts mention "Mass Ave" without describing the same incident. IDF-weighted scoring, hub suppression (>3% frequency → filtered), per-entity cluster caps, cross-thread-first ranking, and a final LLM classification gate work together to isolate genuine connections. Similarly, "Mass Ave & Prospect" vs "Mass Ave / Prospect light" requires layered matching: token overlap for descriptive entities, strict Dice coefficient for identifiers, embedding similarity as fallback. Different entity types need fundamentally different matching logic.
Brigade detection without false positives. Volume alone isn't a brigade — active threads have many authors. We require semantic uniformity (pairwise cosine ≥0.45) combined with temporal density (≥3 distinct authors, density ≥0.5) within a 4-hour window, plus per-thread lock to prevent duplicate alerts.
Platform constraints and scale. Devvit is pure JavaScript — no Python, no native extensions, no subprocess calls. Algorithms that are one pip install away (UMAP, Louvain, FAISS) had to be found as JS libraries or worked around entirely. Redis is capped at 500MB per installation with no external vector store available — we budget ~2.5KB per item, giving a hard ceiling of ~330K items. To handle this, Strata implements a sliding memory window: when storage reaches 90% capacity, the oldest 500 items are automatically evicted before new content is ingested — the community memory stays fresh without manual intervention. We chunk backfills at 500 items with exponential backoff, quantize embeddings to ~3× compression, and support both Batch API (cheap/slow) and real-time ingestion (fast/costly). The system works well at 10K items. At larger scale, brute-force cosine is O(N), the full embedding set must fit in memory, and each item costs API calls. A production deployment beyond Devvit's current limits would need ANN indexing and incremental scan — the honest engineering frontier.
Accomplishments
- Real-time pipeline: post submitted → alert delivered in under 10 seconds (single-item ingest + retrieve + classify).
- Three detection modes (surface, pattern, brigade) running in parallel on every item.
- Hybrid retrieval with entity-aware IDF scoring + cosine safety net + RRF fusion — outperforms pure semantic search for cross-thread connection finding.
- Full-corpus scan: 3,000+ items cross-referenced in minutes via scheduler-chunked classification.
- Benchmark: 10,044-item corpus with adversarial decoys — 3/4 buried witnesses retrieved in top 15 (consistent across 10/10 trials), zero false positives classified as related. The 4th (narrative-only, no shared entities) is the honest ceiling of entity-driven retrieval.
- Interactive 3D topic graph (Three.js + UMAP + Louvain) rendering thousands of nodes at 60fps inside a native Devvit custom post.
- Tool-use AI chat agent with dashboard navigation side-effects — mods can query the community memory conversationally.
- Compose & publish: turns scattered evidence into community-facing story posts — moderators become community leaders, not just gatekeepers.
- Fully platform-native: triggers, scheduler, Redis, custom posts. No external servers, no separate auth, no context switch. One-click install from the App Directory.
What we learned
- The hard problem is filtering, not retrieval. 95% of items that share an entity share a topic, not a specific referent. The distinction between "Mass Ave" as a common location and "Mass Ave" as the site of a specific incident is where the engineering lives. No keyword bot or embedding-only search can make this distinction — it requires structured entity extraction, hub suppression, and LLM-based classification working together. This is why pure semantic search doesn't solve the problem; it finds topically similar posts, not posts about the same specific thing.
- Brigade detection needs both semantic and structural signals. Volume or timing alone produces false positives on any active thread. Uniformity (are they saying the same thing?) combined with density (are they arriving together?) catches coordinated action while ignoring organic disagreement. This is something only AI can do at scale — no human moderator reads 50 comments and mentally computes pairwise semantic similarity.
- Entity extraction quality gates the entire pipeline. A missed entity means a missed connection. Atomization (each feature as a separate entity) and the "head noun required" constraint eliminated the ambiguous extractions that caused false matches early on. Getting this right mattered more than any architectural decision.
- Platform constraints produced a better system. Devvit's egress caps, scheduler-only async, and Redis-only storage forced design decisions that improved resilience: chunked processing survives interruptions, quantized embeddings fit Redis budget while preserving retrieval quality, and cache-on-write makes the hot path fast. We designed with the platform, not around it.
What we learned
- Retrieval is easy. Filtering is the whole problem. Semantic search finds topically similar posts. That's not useful — a mod doesn't need 50 posts about "bike safety." They need the 3 posts about this specific incident. The engineering is entirely in distinguishing referents from topics, and that requires entity extraction, statistical filtering, and LLM classification working together. No single technique solves it.
- The extraction prompt matters more than the architecture. One bad extraction rule (allowing bare adjectives as entities, or combining multiple features into one string) cascades into hundreds of false matches downstream. We rewrote the extraction prompt more times than any other component. Getting the input right mattered more than any retrieval optimization.
- Constraints sharpen design. Pure JS, 500MB Redis, egress caps, scheduler-only async — every limitation forced a decision that made the system more resilient. Chunked processing survives interruptions. Quantized embeddings fit budget. The sliding window keeps memory fresh. We'd make most of these same choices on an unconstrained platform.
- Cross-thread intelligence is a new primitive, not a feature. Once you have community memory, everything else follows: brigade detection, pattern enforcement, topic clustering, the chat assistant. They're all queries over the same indexed corpus. The hard part was building the corpus right; the applications were straightforward.
What's next
- ANN indexing and incremental scan: replace brute-force cosine with approximate nearest neighbors as corpus grows. Scan over deltas (new items since last run) instead of the full corpus — the main scaling bottleneck.
- Mod action feedback loop: approve/remove decisions feed back as training signal for pattern detection. The system gets more accurate the more a mod team uses it.
- Cross-subreddit federation: brigades often originate from outside the target community. Shared entity indices across opted-in subreddits could surface coordinated campaigns at the network level.
- Cost-aware scheduling: adaptive backfill pacing and scan frequency based on community size and budget — smaller subs shouldn't pay large-sub costs.
- Community health digest: weekly topic velocity, coordination index, and emerging patterns surfaced proactively — turning Strata from a reactive alert system into a community health monitor.
Built With
- devvit-redis
- gpt-5.4-mini
- gpt-5.5)
- graphology-(louvain)
- hono
- openai-api-(text-embedding-3-small
- react-19
- reddit-devvit-platform
- tailwind-css-4
- three.js
- typescript
- vite-7

Log in or sign up for Devpost to join the conversation.