-
-
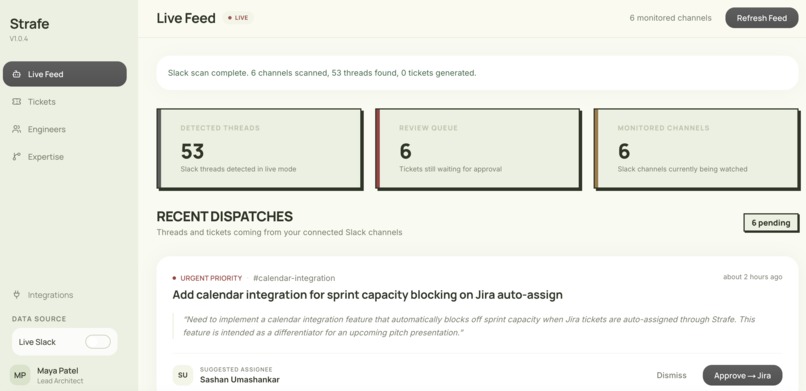
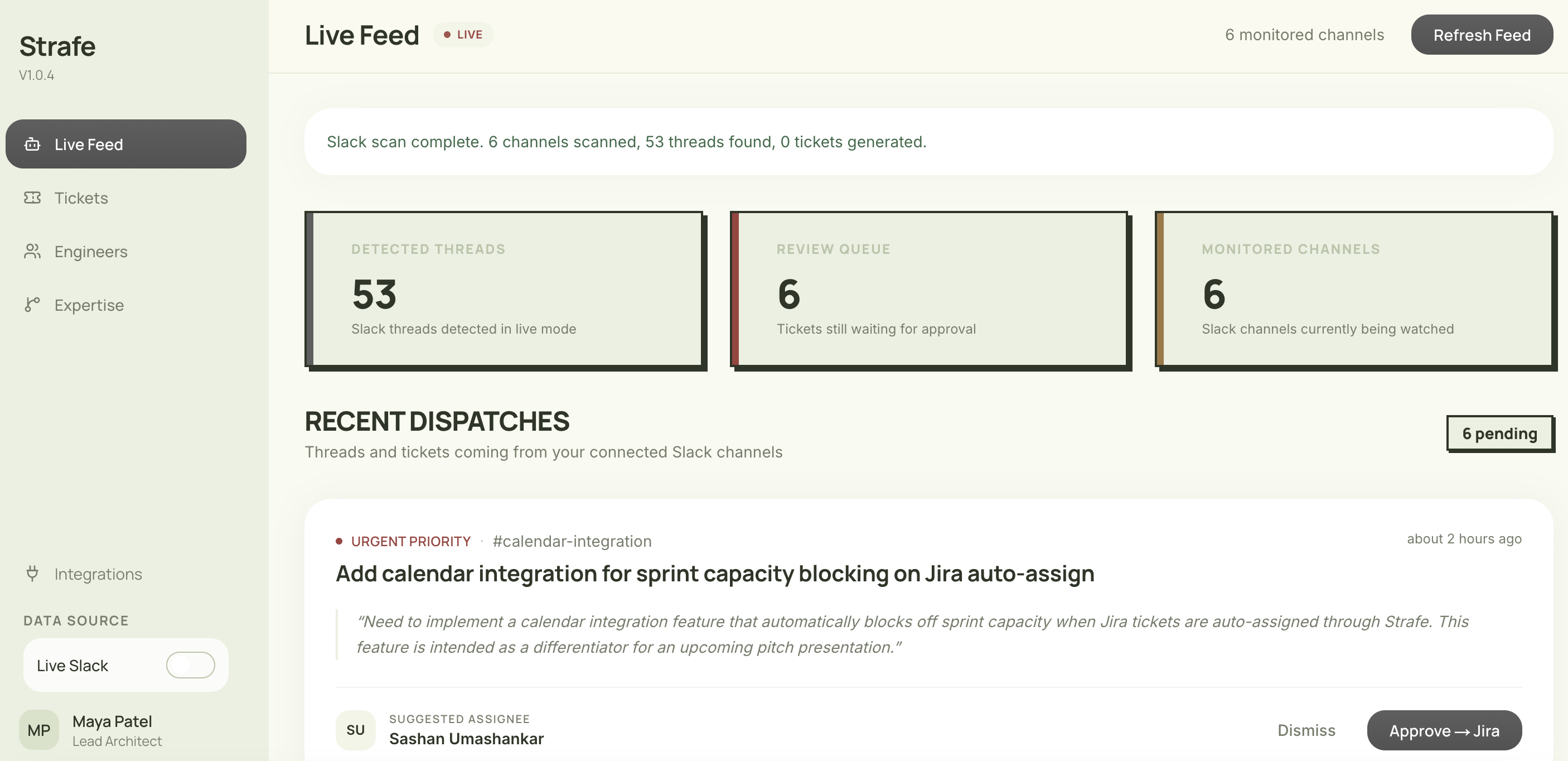
The Live Feed page shows real-time AI decisions, turning Slack conversations into tasks and filtering out noise.
-
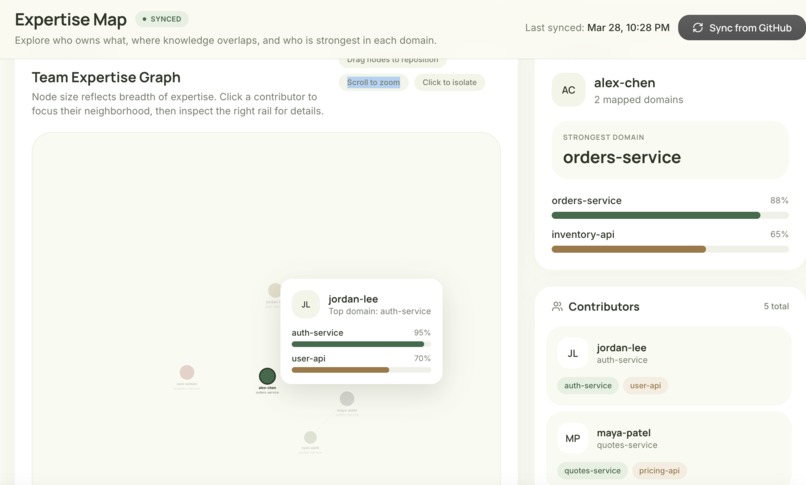
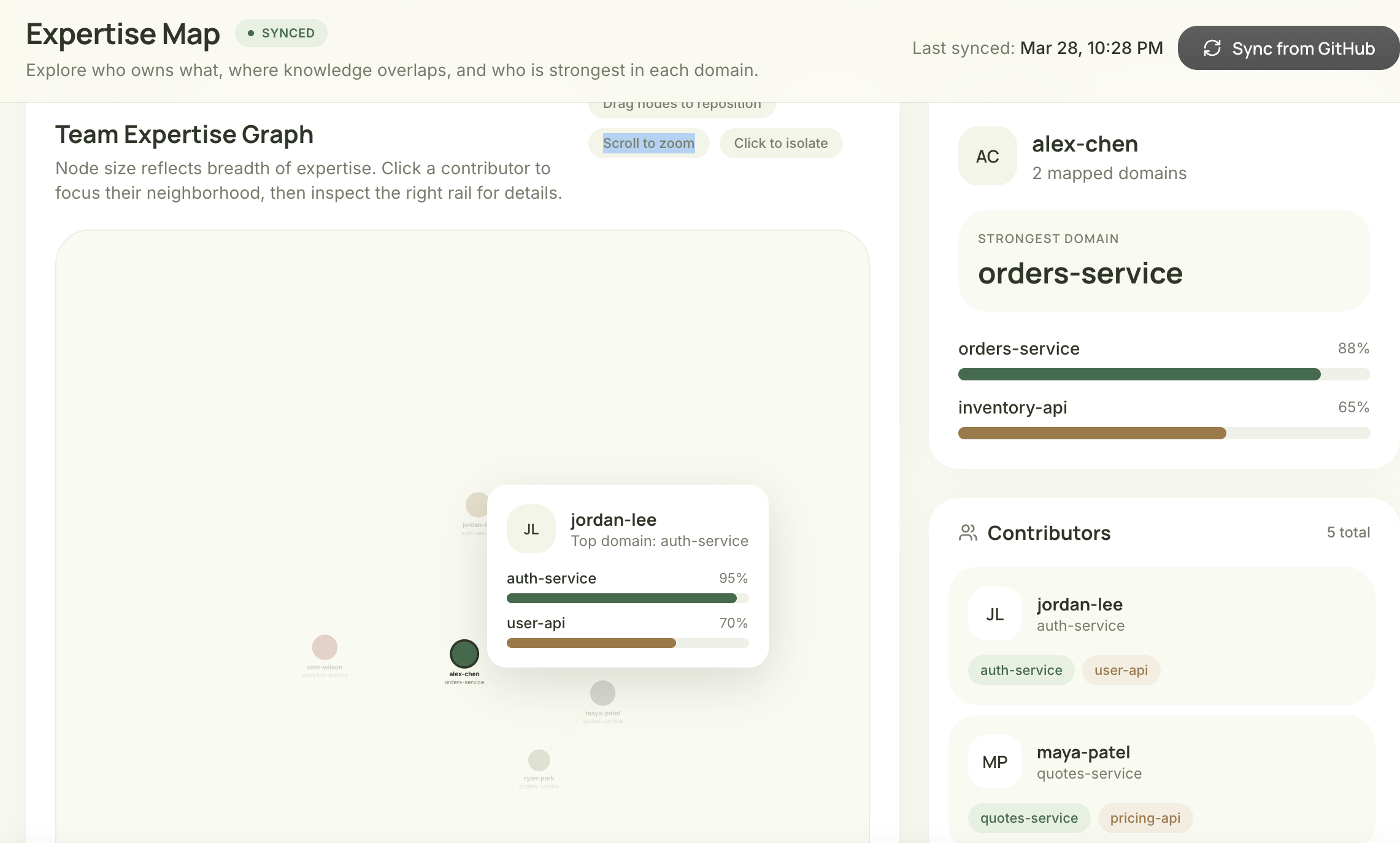
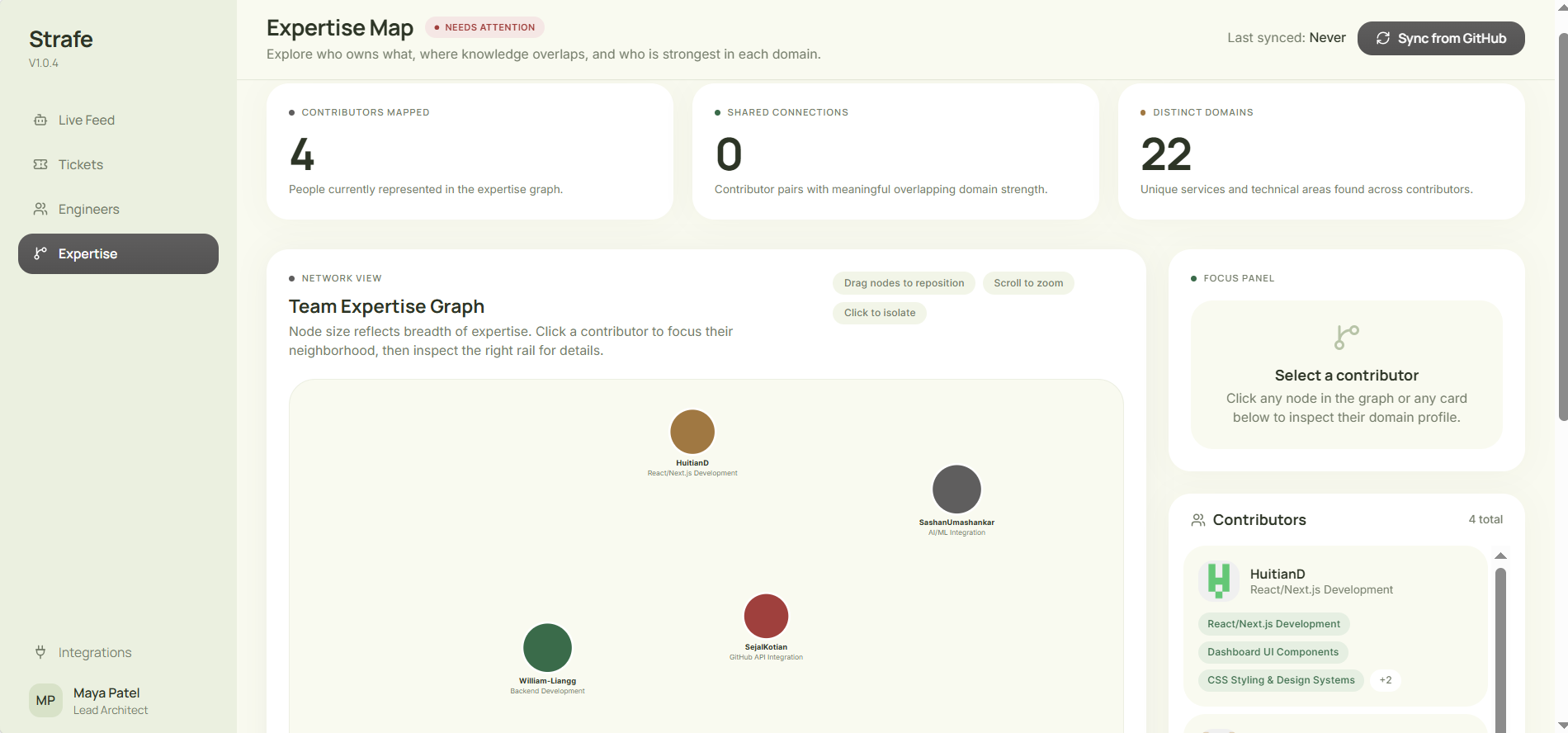
Expertise Map visualizes team skills from GitHub, showing ownership, strengths, and workload distribution.
-
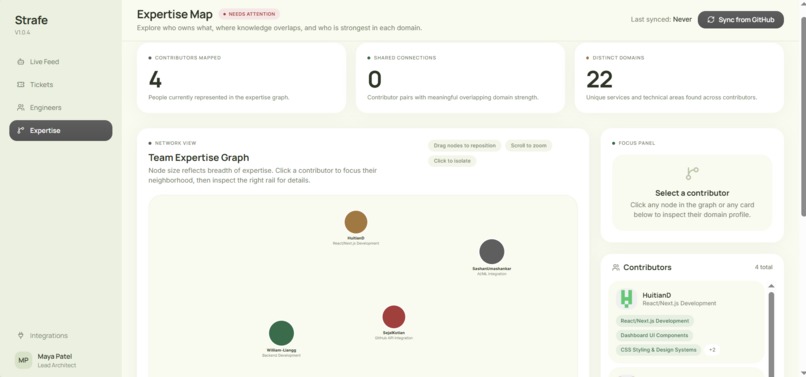
Builds a real-time knowledge graph of our team from live GitHub activity.
Inspiration
With much of our team having past experiences in enterprise, we recognized the fast-moving nature of Slack channels. Many times bug reports and feature requests get lost in the Slack conversations. Product managers lose visibility, and engineers find themselves doing unstructured adhoc work.. We wanted to build an agent that lives where the conversation happens and handles the overhead of project management automatically, acting as an AI agent for Product Managers.
What it does
Strafe acts as an autonomous member of your engineering team that lives inside Slack to catch the work that usually gets lost in channels, distinguishing between casual conversation and actual tasks. Once it detects a task in the Slack channel, it writes a complete Jira ticket with a title, task description, and story points, all based on the context of the messages.
What makes Strafe super unique and “smart” is how it handles who gets assigned what task and when. Instead of just picking a random developer, it analyzes your team’s GitHub PR history through an expertise map to see who actually has the experience for that specific part of the code. It then cross-references their Google Calendar to make sure they actually have the bandwidth to take it on. At the end, it gives leadership a clear " Analytics" dashboard, showing exactly how much of the team’s time is being used up by unplanned work versus the original roadmap.
How we built it
We used Anthropic's Claude (claude-sonnet) to classify Slack threads and determine whether they contain actionable engineering work. When a task is detected, Claude generates a fully structured Jira ticket and streamlines the decision-making process: it extracts the title, description, priority, story point estimate, and suggested assignee directly from the conversation context and GitHub commit history. To ensure meaningful assignee suggestions, we built a GitHub analyzer that scans commit history, PR authorship, and code review activity across all branches to map each engineer's areas of ownership. Claude infers 3–6 expertise domains per contributor and scores them 0–1 by contribution volume. The backend runs on FastAPI with Celery handling async task processing and Redis as the message broker. Slack events hit a webhook, get queued as Celery tasks, and pass through the Claude pipeline. Then, draft tickets appear in the dashboard within 10–15 seconds of the original message. Strafe is a full-stack Next.js application, giving managers a real-time ticket queue with one-click approve/reject and inline editing before tickets are pushed to Jira. An analytics layer surfaces the breakdown of adhoc vs. planned work by sprint, channel, and engineer.
Challenges we ran into
The biggest challenge was getting all three external integrations - Slack, Github, Jira to work reliably together with real credentials and live data rather than mock/demo seed data which did surface a cascade of issues, with each fix revealing the next layer of the stack that needed attention. We had to make sure a ticket generated from a Slack thread carried the right context, the right assignee, and landed in the right Jira project and sprint, requiring every piece of the pipeline to be reliable at the same time. This required tight coordination across the Slack ingestion pipeline, the Claude classification layer, the GitHub expertise sync, and the Jira API, where a failure or inconsistency in any one of them would silently break the entire flow downstream.
Accomplishments that we're proud of
We are most proud of turning a messy, real-world problem into a working end-to-end system (Slack-to-Jira) in just 24 hours. A message posted in Slack gets read by the bot, classified by Claude, turned into a structured ticket with priority and story points, intelligently assigned, and surfaced on the dashboard for human review. The expertise graph assignee system is something we're particularly proud of as well. Instead of random assignment, the system analyzes real GitHub commit and PR history to understand who owns what code, so the right engineer gets the ticket every time
What we learned
Building Strafe taught us that how you prepare the data for AI ingestion is super important. We realized that if you just dump a messy Slack transcript/conversation into an AI, the output is a mess too. We learned how to improve our context management, which meant building a system that cleans up the conversation before the AI ever sees it. By clearly labeling who said what and when, the AI stopped getting confused by random conversation in Slack and started understanding the actual task reports that needed to be addressed.
We also recognized that the value proposition of Strafe comes from tracking the organization efficiency for the product managers. By tracking "unplanned work" as a specific metric, Strafe gives managers the hard data they need to show management exactly why a project is slowing down. It turns excuses into a clear chart that defends the team's roadmap and task delegation
What's next for Strafe
Moving forward, we want Strafe to not just flag problems but to actually help solve them beyond task descriptions. Currently, the agent can tell an engineer that a bug exists, but the engineer still has to spend time hunting for the problem. By linking Slack bug reports directly to recent GitHub activity, Strafe will identify specific commits or lines of code that were changed around the time the issue was reported. This allows developers to immediately get to debugging or programming, improving organization productivity.
We also look to close the communication loop between engineering and the rest of the company. Right now, Strafe is great at pushing data from Slack into Jira, but we want it to pull data back just as effectively. When a developer moves a ticket to "Done" in Jira, Strafe will automatically locate the original Slack thread and post a "Resolved" badge. This keeps all members of the team informed in real-time without making the engineer manually tell everyone about the resolved problem, taking away from their time.
Built With
- celery
- claudeapi
- css
- d3.js
- fastapi
- gcal
- githubapi
- jiraapi
- next.js
- oauth
- postgresql
- python(fastapi)
- redis
- slackapi
- sqlalchemy
- swr
- typescript




Log in or sign up for Devpost to join the conversation.