-
-
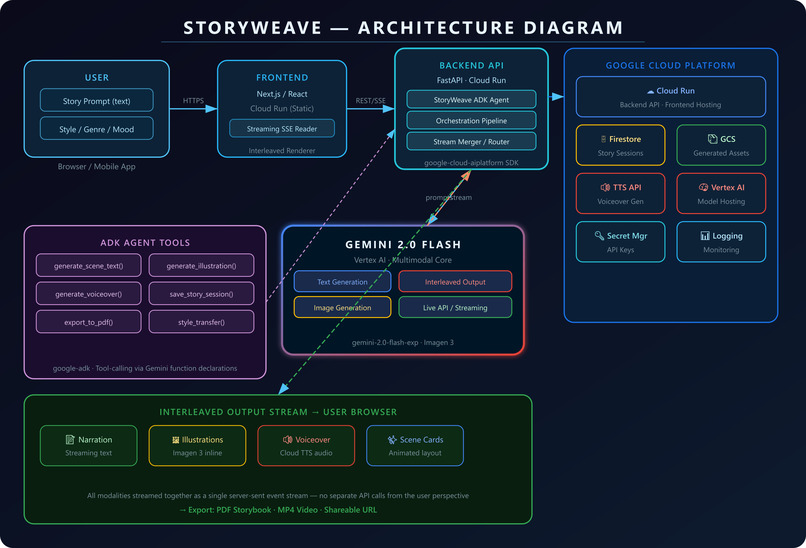
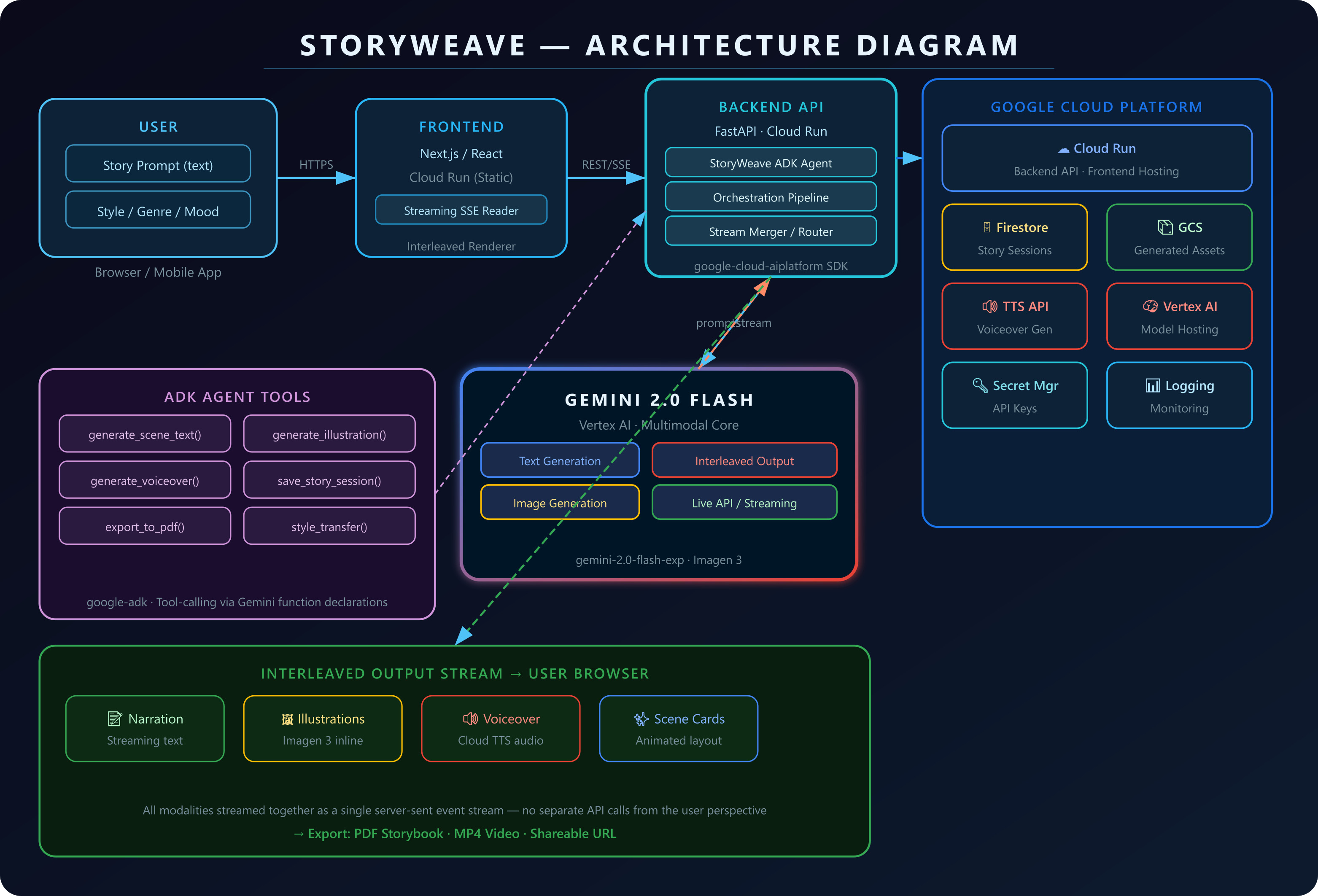
Architecture
About StoryWeave: AI Multimodal Creative Director
Inspiration
Every great story lives in multiple dimensions at once. When you read a powerful novel, you see the scene. When you watch a film, you feel the score. But creating multimedia stories — children's books, marketing narratives, educational explainers, pitch decks with visuals — has always required assembling a team: a writer, an illustrator, a voice director, an editor. Even with modern AI tools, you still bounce between five different apps, copy-pasting between a text generator, an image generator, and a text-to-speech tool, stitching the pieces together by hand.
That fragmentation is the problem we set out to destroy.
We were inspired by the question: what if the AI didn't just write the story — what if it directed it? A real creative director doesn't hand off tasks sequentially. They hold the whole vision in their head simultaneously — the words, the images, the sound — and orchestrate them into one coherent experience. Gemini 2.0's native interleaved output capability made us believe that vision was finally technically achievable. We wanted to build the thing that proved it.
What it does
StoryWeave is an AI Creative Director agent that transforms a single text prompt into a complete, publication-ready multimedia story — streaming narration, scene illustrations, and voiceover audio all at once, interleaved in real time.
A user types a premise — say, "A lighthouse keeper discovers an ancient map hidden in the walls of her tower" — selects an illustration style (watercolor, oil painting, cinematic, ink sketch), and hits generate. What follows is unlike any AI experience they've seen before:
- Narration streams word-by-word, literary prose appearing as if being typed by an unseen author
- Illustrations materialize inline, exactly where the story dictates — not after the fact, but woven into the flow
- A voiceover audio player appears for each scene, synthesized in a natural Journey voice, ready to play
When it's done, the user can export a PDF storybook, share a permanent URL, or download the audio. The entire experience — from blank prompt to illustrated, narrated story — takes under 90 seconds.
How we built it
StoryWeave is built on a fully Google Cloud-native stack, architected for streaming performance.
The Agent: We used the Google Agent Development Kit (ADK) to build a SequentialAgent with three specialized sub-agents — a NarrativeAgent for literary prose, a VisualDirectorAgent for illustration prompts and Imagen 3 calls, and an AudioDirectorAgent for Cloud TTS voiceover synthesis. Each sub-agent has access to purpose-built ADK FunctionTool wrappers that call the appropriate GCP service.
The Core: Gemini 2.0 Flash Experimental on Vertex AI is the backbone. We use response_modalities=["TEXT", "IMAGE"] to enable native interleaved output — the model can emit text tokens and image data within a single response stream. We also embed custom markers ([IMAGE: ...], [AUDIO: ...], [SCENE_END]) in the system prompt, which our parser intercepts in real time to trigger parallel Imagen 3 and Cloud TTS calls without ever blocking the text stream.
The Stream: The backend is a FastAPI application deployed on Cloud Run, exposing a Server-Sent Events (SSE) endpoint. Each modality — text delta, image data, audio URL — is a different SSE event type. The frontend's streaming reader routes each event to the right renderer: text goes to the typewriter component, image events trigger the illustration fade-in, audio events mount the waveform player. No polling. No page refreshes. One connection, everything flowing through it.
The Infrastructure:
- Vertex AI — Gemini 2.0 Flash + Imagen 3 model hosting
- Cloud Run — Backend API + frontend hosting, auto-scaling to zero
- Cloud Firestore — Story session persistence and shareable URL storage
- Google Cloud Storage — Generated image and audio asset storage
- Google Cloud Text-to-Speech — Journey voice synthesis
- Secret Manager — API key and credential management
- Cloud Logging — Observability and debugging
Challenges we ran into
Coordinating async modalities without blocking the stream was the hardest architectural problem. Image generation via Imagen 3 takes 3–6 seconds per scene. If we awaited each image before continuing the text stream, the user experience would feel like a loading spinner — exactly what we were trying to avoid. The solution was asyncio.create_task(): image and audio generation fire as background tasks the moment their marker is parsed, and their results are pushed back into the SSE channel as they complete, overlapping with the ongoing text stream. The user sees text immediately, and images appear a few seconds later exactly where the story placed them.
Gemini's native image output vs. Imagen 3 required a deliberate architectural choice. Gemini 2.0's interleaved image output is powerful but optimized for general visual understanding. For stylistically consistent illustrations — watercolor, oil painting, folk art — Imagen 3 gives far superior control via style descriptors. We built a hybrid: Gemini handles all text generation and orchestration, while Imagen 3 is called via the ADK tool for each illustration. The prompt for each illustration is itself written by Gemini's VisualDirectorAgent, which translates the narrative into precise art direction.
Streaming SSE + Cloud Run required careful configuration. Cloud Run's default request timeout and response buffering settings will silently break long SSE connections. We had to set --timeout 300, configure X-Accel-Buffering: no headers, and ensure the response stream never went silent for more than 30 seconds (we emit keepalive events between scenes).
Prompt engineering for consistent narrative voice across multiple scenes was surprisingly difficult. Gemini needed strong guidance to maintain character continuity, tonal consistency, and the specific literary register we wanted — without repeating itself. We developed a multi-pass approach: the NarrativeAgent receives a running "story bible" (character names, established setting details, tone adjectives) that is updated after each scene and prepended to the next scene's prompt.
Accomplishments that we're proud of
We're proud that the core experience genuinely feels like something new. Not "AI writes a story." Not "AI makes an image." But a single creative act that produces text, illustrations, and audio simultaneously — the way a human creative director would think about all three at once.
We're proud of the zero-blocking stream architecture: a user on a slow connection still sees narration immediately, with illustrations arriving as they're ready. The experience degrades gracefully rather than stalling.
We're proud of the ADK multi-agent design. Breaking the creative process into specialized sub-agents — each with a distinct role and system prompt tuned to that role — produced meaningfully better outputs than a single monolithic prompt. The NarrativeAgent writes like a novelist. The VisualDirectorAgent thinks like an art director. The AudioDirectorAgent edits like a voiceover producer. Separation of concerns turns out to be as powerful in prompt design as it is in software engineering.
And we're proud that everything — backend, frontend, database, assets, secrets — runs on Google Cloud with no external services required.
What we learned
Interleaved output is the future of multimodal UX. The moment users see text and an image appear together in the same flow — rather than in separate panels or sequential steps — something clicks. It feels qualitatively different from "here's text, here's an image." The interleaving creates the sense that the AI is thinking in multiple modalities at once, which is exactly what makes it feel like a creative director rather than a tool.
Streaming architecture forces good product thinking. Building for SSE forced us to think carefully about which events matter to the user and when. That discipline produced a cleaner UX than we'd have designed starting from a request/response model.
ADK's sub-agent model is genuinely powerful for creative tasks. Giving each sub-agent a narrow, well-defined responsibility — and a system prompt written for that specific creative role — produced outputs that were noticeably more refined than single-agent approaches. We'd apply this pattern to any creative generation task going forward.
Latency is a design material. The 3–6 seconds it takes Imagen 3 to generate an illustration isn't a bug — it's a feature if you design around it. The text streaming during that window creates anticipation. The illustration arriving mid-narrative creates a moment of delight. We learned to choreograph latency rather than fight it.
What's next for StoryWeave: AI Multimodal Creative Director
Live API narration with barge-in. The next version integrates Gemini's Live API for real-time voice narration — the story is read aloud as it generates, with the user able to interrupt and redirect the narrative mid-stream. "Actually, make her turn back" spoken aloud would reshape the story in real time.
Consistent character appearance across scenes. Today, each illustration is generated independently. We want to use Imagen 3's upcoming style-reference capabilities to lock character appearance — same face, same costume, same color palette — across every scene of a story.
Collaborative storytelling. Firestore's real-time listeners make multi-user story editing a natural extension: two people shaping the same narrative in real time, with the AI weaving their inputs together.
Video export. Using Cloud Run Jobs + ffmpeg, scenes can be assembled into a narrated video — illustrations animated with Ken Burns effects, voiceover synchronized, background music added via the YouTube Audio Library API.
Education vertical. StoryWeave's interleaved format is uniquely suited to educational explainers: a concept is introduced in prose, illustrated with a diagram, then summarized in a 15-second voiceover. We see a clear path to a specialized "Explainer" mode for teachers and course creators.
Built With
- 2.0
- 3
- 3.11
- agent
- ai
- apis
- asyncio
- backend
- cli
- cloud
- cloud-run
- css3
- development
- devops
- docker
- events
- experimental
- fastapi
- firestore
- flash
- framework
- frontend
- gcloud
- gemini
- genai
- google-adk
- google-cloud
- google-cloud-aiplatform
- google-cloud-firestore
- google-cloud-texttospeech
- html5
- imagen
- kit
- languages
- libraries
- logging
- manager
- models
- monitoring
- next.js
- pydantic
- python
- react
- run
- runtimes
- sdk
- secret
- server-sent
- services
- storage
- text-to-speech
- typescript
- uvicorn
- vertex
- vertex-ai

Log in or sign up for Devpost to join the conversation.