-
landing page
-
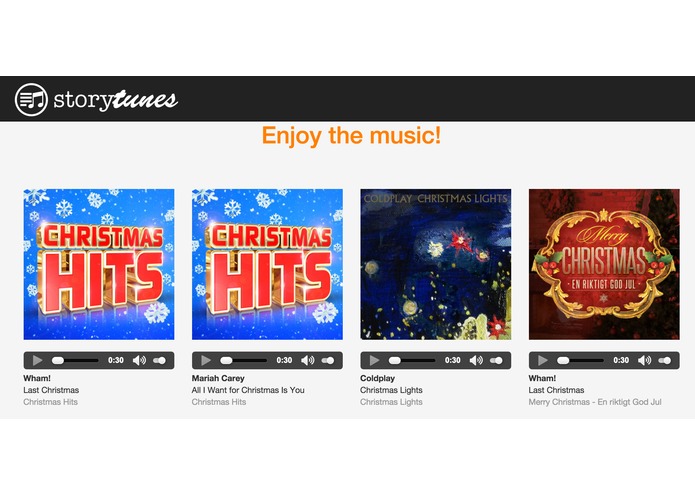
songs returned for article about christmas

Inspiration
We wanted to enrich the reading experience and provide new means for music discovery by identifying suitable songs for news articles or stories.
What it does
Based on an article URL provided by the user we get the text, title, keywords and entities from the Alchemy API. We use the musiXmatch lyrics dataset of the million song dataset (http://labrosa.ee.columbia.edu/millionsong/challenge) to generate a list of topic cluster of the available songs. Using the Alchemy information we then classify the article to one of this topics and retrieve the nearest songs. In addition we use the article entities to retrieve top songs directly from music APIs. Those combined results are then surfaced on the front end.
Challenges we ran into
Combining the various modules to create the end-to-end flow proved to be more time consuming then we thought initially.
Accomplishments that we are proud of
Integration of complex machine learning techniques and usage of various APIs and getting the whole thing together in the given timeframe.
What I learned
Importance of clear focus on minimum viable product and early integration testing.
What's next for storytunes
Improving the topic classification of songs and articles by finetuning the LDA algorithm. Allowing the user to login and import songs directly to spotify, myhumm or other playlists. Allowing the user to rate the retrieved songs. Improving efficiency of backend processes.











Log in or sign up for Devpost to join the conversation.