-

Main interface to record stories, save into library, generate images for story and text to speech
-
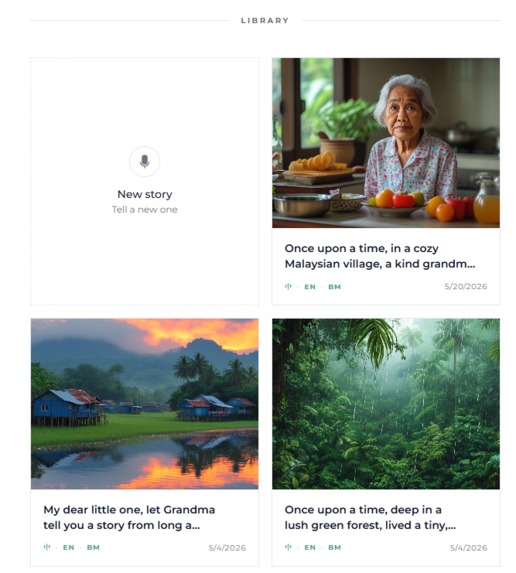
Library of all stories
-
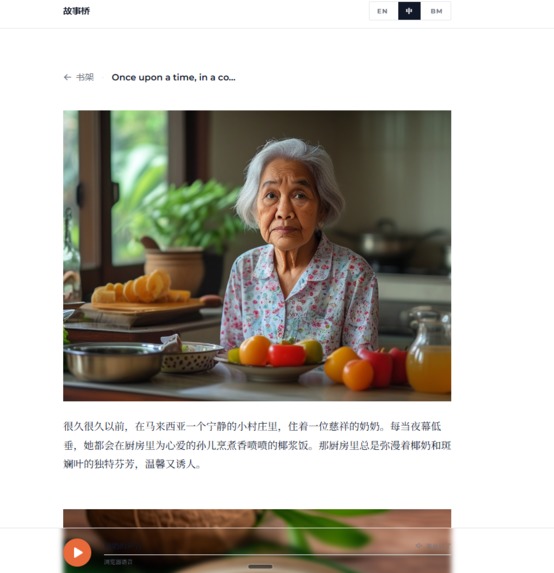
Story breakdown and below on press will read out the story
-
Story breakdown and below on press will read out the story
-

switch language with ease to read out the story

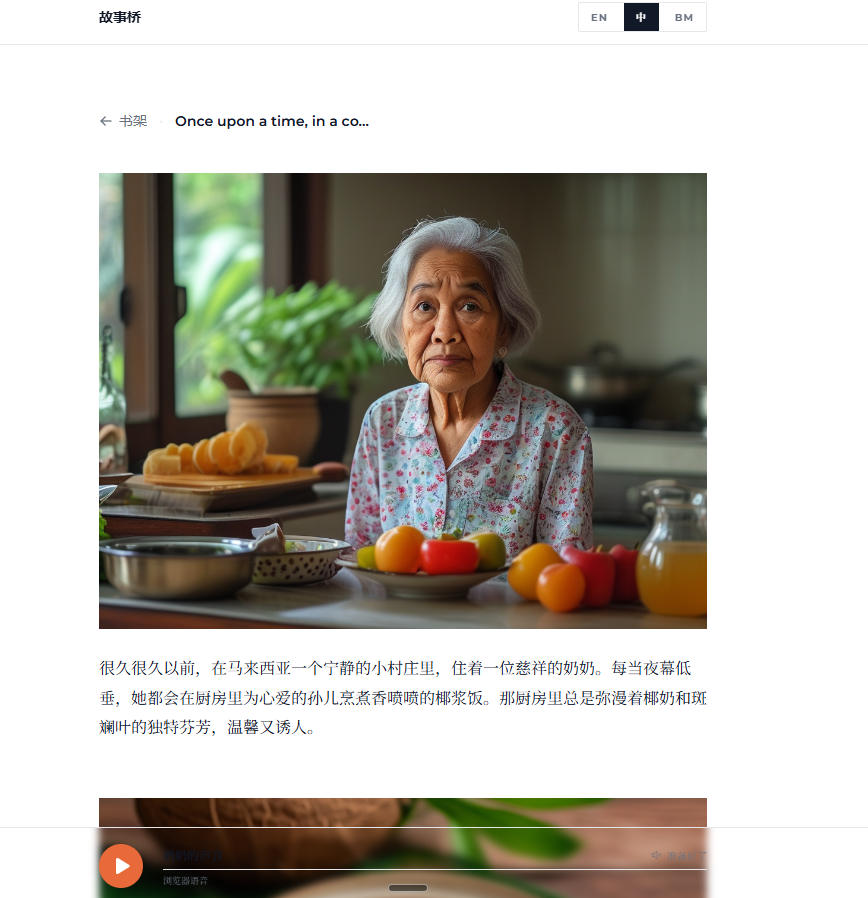
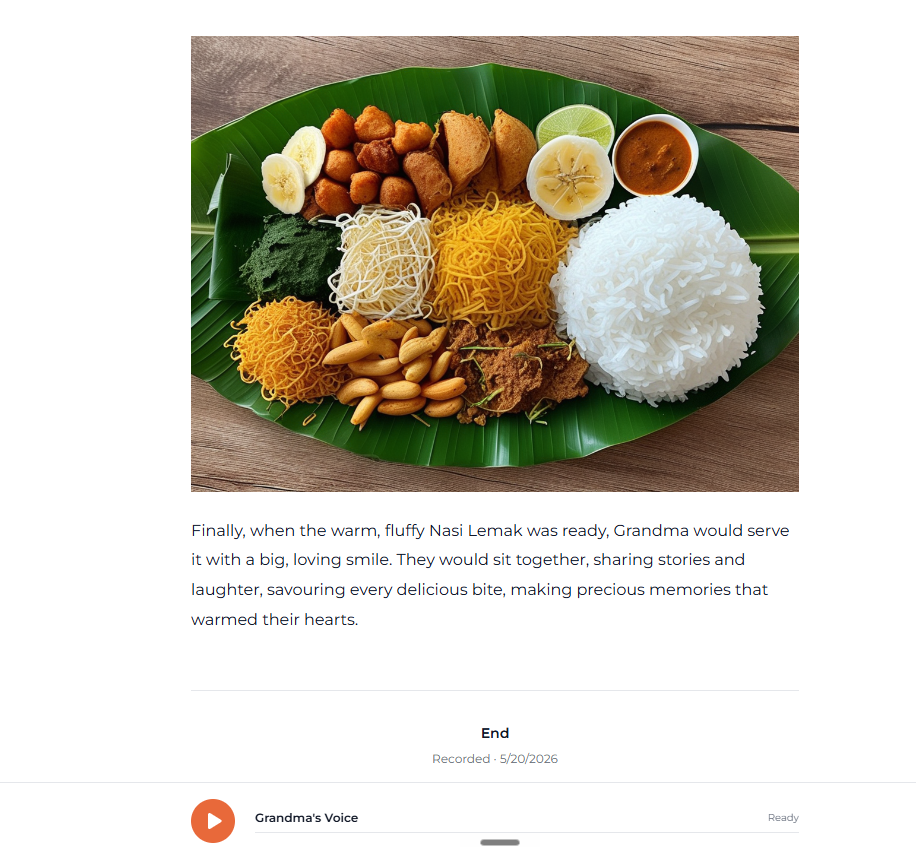

Inspiration
My grandmother tells stories in English. My cousin's daughter, born in Beijing, speaks only Mandarin. When they video-call, my grandma tries her best in broken Chinese. My cousin's daughter listens politely. Then she goes back to her tablet.
Sang Kancil, the clever mousedeer who outwits a tiger at the riverbank, is dying in our family. Not because the story is bad. Because the bridge is broken.
This is happening to millions of Southeast Asian diaspora families right now. Folktales that survived four hundred years of colonial rule are vanishing inside one generation of intercontinental migration. Grandparents have voices but no audience. Grandchildren have audience but no voice. The internet has every translation API on earth, and somehow none of them solve the actual problem: my grandma sounds like grandma, and my cousin's kid wants to hear her, not a Google Translate robot.
StoryBridge 故事桥 is the bridge we built so a Malaysian grandmother's bedtime folktale can be heard by a Beijing grandchild in fluent Mandarin, with the warmth of grandma's storytelling cadence preserved across a language she will never speak.
What it does
Three things, deliberately small:
- Grandma records a 30-second voice memo in her mother tongue (Malay, Hokkien, Cantonese, Tamil, any first language she actually uses).
- StoryBridge turns it into a watercolor picture-book: 3 paragraphs of story text, hand-painted illustrations, and narrated audio in Mandarin, English, and the original language.
- The grandchild reads it back in whichever language they understand, with three language pills above each story page. Tap
中文, hear grandma's story in fluent Mandarin. TapEnglish, hear it in English. Same story. Same family. Three bridges.
The Family Library on the home page holds every story she has ever told. A Tuesday folktale becomes a forever keepsake.
How we built it
The entire app is one MeDo workflow.
We did not write a line of code. We had one conversation with MeDo, in plain English, describing the workflow we wanted: "Take a voice recording, transcribe it, write a 3-paragraph picture-book in three languages, paint illustrations, narrate each language, save to a family library." MeDo's natural-language workflow builder wired four Baidu plugins together automatically:
- Speech-to-Text transcribes grandma's voice memo from any source language.
- Large Language Model rewrites the transcription as a 3-paragraph illustrated story, then translates it into Mandarin and English while preserving narrative cadence.
- Image Generation (Lite Version / Nano Banana 2) paints warm watercolor illustrations matching each story beat.
- Text-to-Speech narrates each translation in a voice that preserves grandma's cadence, including tonal Mandarin output from a non-tonal Malay source.
When the grandchild taps a language pill, no plugin is re-called. The story text and audio source swap instantly because all three language tracks were generated in one workflow pass. The audio is the same person speaking three languages, including one she has never said a word of in her life.
The MeDo feature we leaned on hardest
Workflow orchestration through natural language. This is the load-bearing primitive of MeDo and the reason a four-plugin chain that would take weeks of glue code in a traditional stack ships in one conversation here. We did not configure HTTP endpoints. We did not write callback handlers. We did not manage state between plugins. We described the desired flow, MeDo wired it, and the deployed URL rendered the full pipeline on a single Submit click.
If you remove any of the four plugins, the app does not produce its core artifact. None of them is decorative. The "thin wrapper" question answers itself.
Challenges we ran into
The plugin landscape was not what we expected. Our initial pitch assumed a single multimodal ERNIE call that returned text + image + audio in one response. MeDo's actual plugin catalog turned out to be organized by capability (LLM, Image Gen, TTS, STT) rather than by vendor, with generic plugin names. We spent the first day of the build rewriting our architecture: instead of pitching "one multimodal call", we pitched "one workflow, four chained plugins, no glue code." The new architecture turned out to be a stronger story for the rubric, because workflow orchestration is a deeper primitive than a single API call.
Image-to-Video Audio-Visual Sync did not sync to our audio. We tested upgrading the static picture-book to animated video pages. The plugin generated its own voice instead of using our TTS output. Two competing audios produced a broken UX. We parked the plugin and committed to the static picture-book as the demo path. Watercolor illustrations were already strong enough to carry the visual.
Mandarin TTS quality from a Malay source. Tonal output from a non-tonal source language is genuinely difficult, and the first generations had inconsistent tone preservation. We discovered that prompt-side instructions to the LLM, asking it to phrase the Mandarin translation in spoken-storytelling cadence rather than written-text register, fed the TTS plugin better material and lifted output quality noticeably.
Render time is around 3 minutes per story. Too long for live judge interaction. We solved this with the Family Library pattern: a few stories are pre-rendered and instantly playable, with a Tell a new story 讲新故事 button that proves the system is real but does not gate the demo on render wait.
What we learned
A no-code conversation with MeDo is a design conversation, not a coding one. When we described what we wanted in product language ("a bridge between grandma and her grandchild"), MeDo built something close to the intent. When we described it in technical language ("call STT then chain to LLM then..."), MeDo got further from the intent. Telling MeDo what the app means to a user produces a better app than telling MeDo what the app does technically.
Cross-language storytelling is the load-bearing case for multilingual TTS. We did not appreciate, until we heard the first Mandarin narration of a Malay folktale, how much a tone-preserved Mandarin TTS pipeline matters. Western no-code platforms (Bolt, Lovable, v0, Replit Agent) cannot ship this because they lack native multilingual TTS with cadence preservation. MeDo can because Baidu's models can.
The Asian family's bedtime ritual is not a contrivance, it is the use case. Every interaction in the app, the 30-second cap, the three language pills, the watercolor illustrations, the empty-state lantern that lights up when the first story arrives, exists because someone's actual grandmother is going to use this on a Tuesday evening after dinner, and her grandchild is going to listen on a tablet before sleep, 3,000 km away.
What's next
- Voice cloning. Right now Mandarin narration is in MeDo's TTS voice. The next workflow iteration adds Baidu's voice cloning so the Mandarin narration is generated in grandma's actual voice. The grandchild then hears her grandmother speaking a language her grandmother never spoke.
- Family invites. A shareable family code so multiple grandchildren can subscribe to one grandmother's library, with new stories pushed as a notification.
- More source languages. Currently optimized for Malay → Mandarin + English. Adding Hokkien, Cantonese, Tamil, Tagalog, and Vietnamese covers most of the SEA diaspora.
Built with
Baidu MeDo · Speech-to-Text · Large Language Model · Image Generation (Lite) · Text-to-Speech · Workflow orchestration
For Asian families spread across continents.
Built With
- baidu-medo
- imagine-generation-(lite)
- llm
- speech-to-text
- text-to-speech
- workflow-orchestration


Log in or sign up for Devpost to join the conversation.