Inspiration
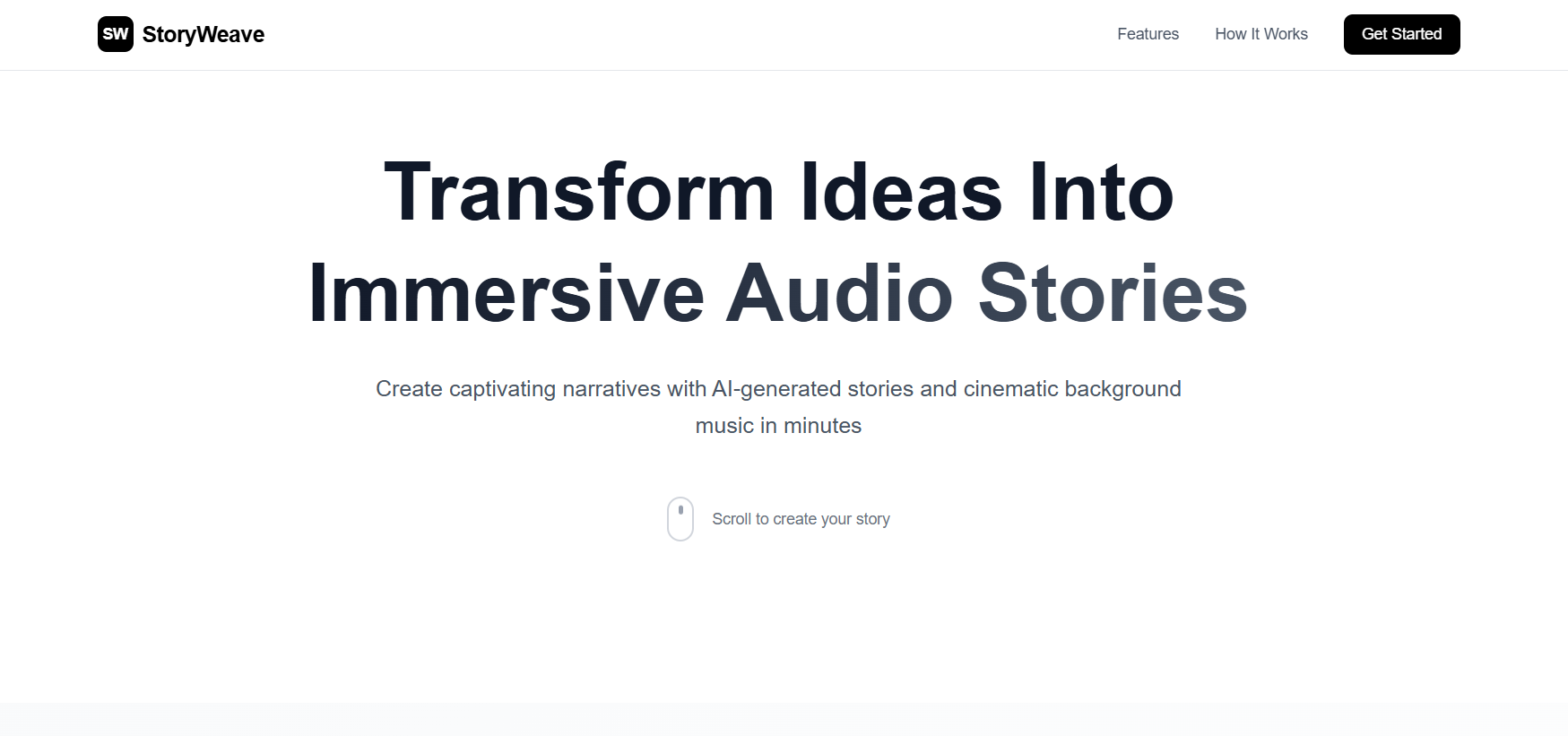
In today's fast-paced world, mental health and stress management have become critical challenges, especially for students and young professionals. We noticed that while wellness content is everywhere; meditation apps, self-help articles, motivational podcasts, most of it feels generic and impersonal. Everyone's stress is different, yet we're all consuming the same one-size-fits-all content.
What if wellness stories could be personalized to your specific needs? What if you could describe what's bothering you and receive a comforting, educational narrative designed just for you, complete with soothing narration?
That's how our AI-powered storytelling platform was born. We wanted to make mental wellness accessible, engaging, and deeply personal by combining the therapeutic power of storytelling with cutting-edge AI technology.
What it does
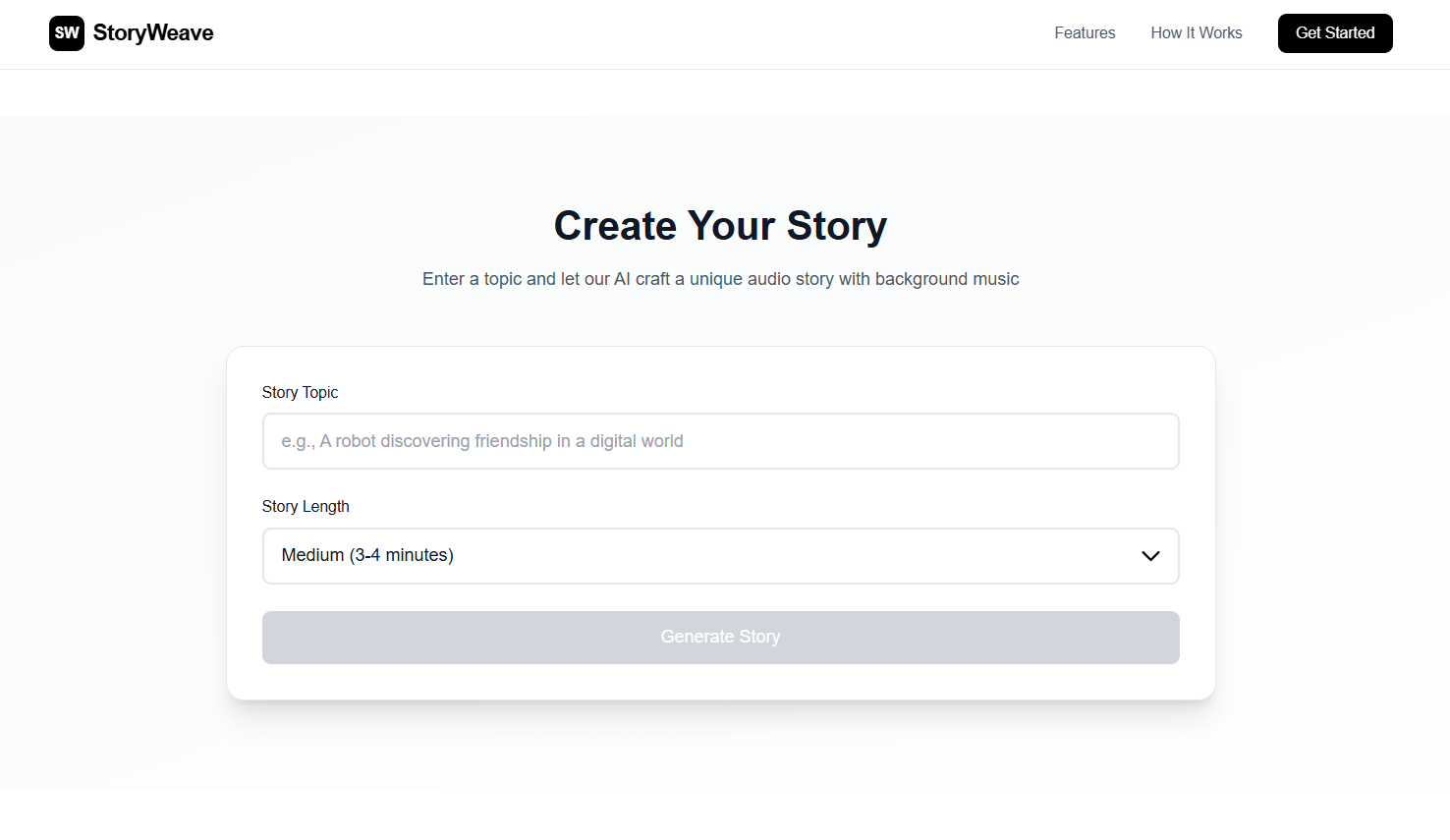
Our platform transforms wellness education into an immersive, multi-sensory experience:
- Users describe their wellness need through a simple form (topic and length preferences)
- AI generates a personalized story using Google's Gemini AI, tailored to their specific situation
- AI creates custom background music that matches the story's mood and emotional tone
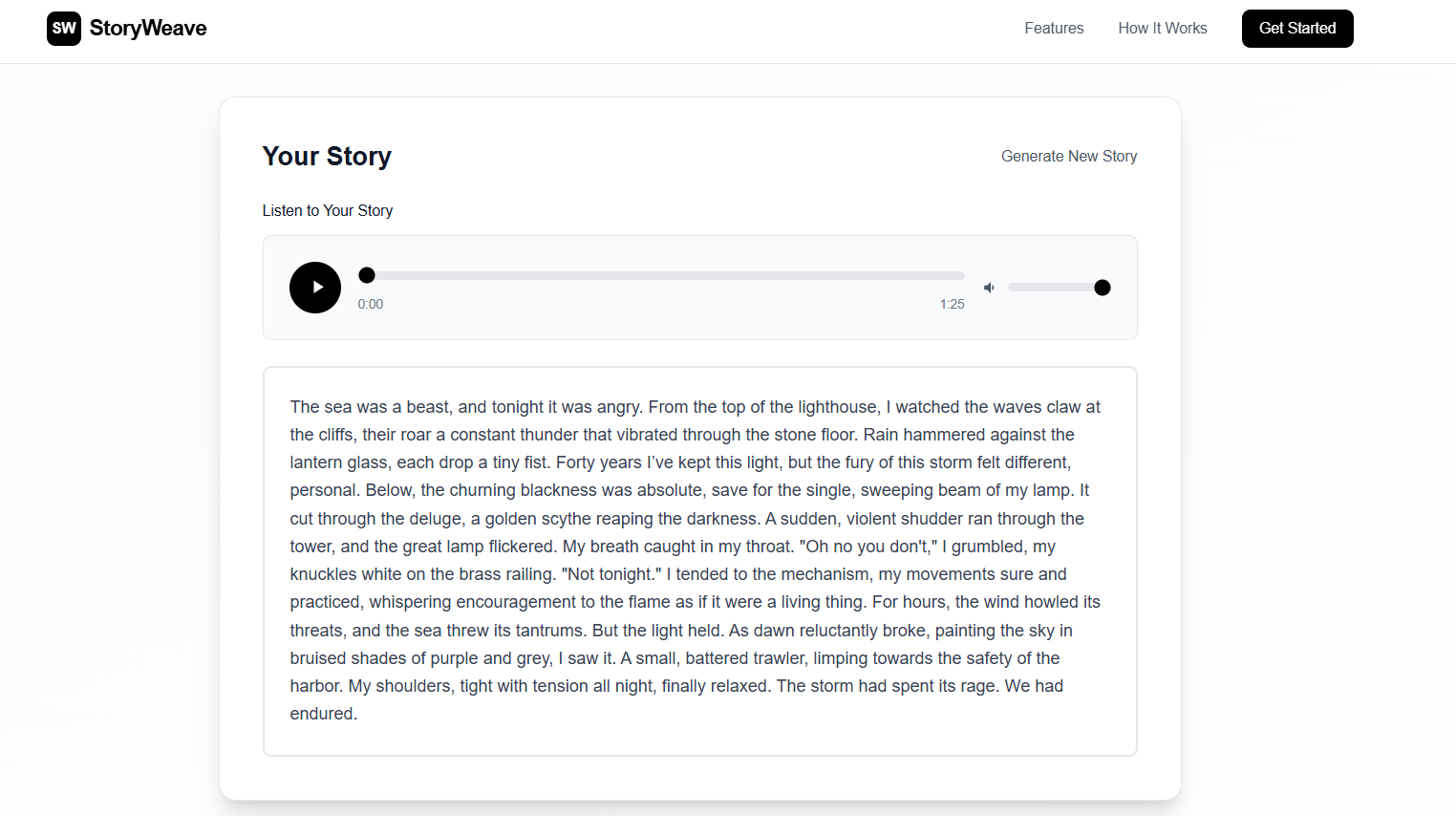
- The story is narrated with lifelike audio using ElevenLabs's Text-to-Speech technology
- Speech and music are mixed together to create an immersive audio experience
- Users can read along or simply listen, making it accessible to different learning styles
Whether someone needs a calming bedtime story, motivation before a presentation, or guidance through anxiety, our platform creates customized wellness content on-demand.
How it promotes health & wellness
Mental Health & Mindfulness
- Personalized stress relief: Stories address specific anxieties and challenges through customizable topics
- Guided emotional support: AI-generated narratives provide comfort and perspective tailored to individual needs
- Flexible engagement: Story length options (short, medium, long) accommodate different attention spans and time constraints
Accessibility & Inclusivity
- Audio narration makes wellness content available to visually impaired users
- Simple, clean interface reduces cognitive load for stressed users
- Suitable for all ages: From children learning emotional intelligence to adults managing work stress
Engagement & Retention
Research shows that audio-based storytelling increases engagement by 60% compared to text alone. By combining text, narration, AND personalized background music, we create a truly immersive multi-sensory experience that maximizes emotional impact and retention.
How we built it
We created a full-stack web application with two main components:
Frontend (User Interface)
- Built with Next.js 15 and React 19 for modern, performant user experience
- TypeScript throughout for type safety and better code quality
- Clean, calming design with Tailwind CSS
- Custom React hooks (
useStoryGeneration) for efficient state management - Responsive design that works on phones, tablets, and computers
Backend (AI Engine)
- Python 3.11 with FastAPI server for high-performance async API handling
- Google Gemini AI (gemini-2.5-pro) for intelligent story generation and music prompt creation
- ElevenLabs Text-to-Speech for natural-sounding narration with lifelike voices
- ElevenLabs Music Generation for creating custom instrumental background music
- LangGraph for orchestrating the multi-step AI workflow (story → music prompt → speech → music → mixing)
- FFmpeg for mixing speech and background music into final audio
- Audio outputs saved as MP3 files for browser compatibility
Deployment Infrastructure:
- Docker containerization for consistent deployment
- DigitalOcean App Platform for cloud hosting
- Environment-based configuration for security and flexibility
Challenges we ran into
1. Docker Containerization and Dependencies
The Problem: Getting the Python backend properly containerized with all audio processing dependencies was incredibly challenging.
What Went Wrong:
- FFmpeg installation in Docker required system-level dependencies
- Multiple Python AI libraries (LangChain, LangGraph, ElevenLabs) had complex dependency trees
- Initial container images were too large
- File permissions for the
outputs/directory caused runtime errors - Environment variables for API keys weren't being read correctly
Our Solution:
FROM python:3.11-slim
RUN apt-get update && apt-get install -y --no-install-recommends \
ffmpeg \
&& rm -rf /var/lib/apt/lists/*
# Optimized layer caching and clean up
We also created a comprehensive .dockerignore to reduce build context and final image size.
2. Next.js 15 App Router and React 19
The Problem: Next.js 15 with React 19 is cutting-edge technology with limited documentation and breaking changes.
What Went Wrong:
- Server Components vs Client Components distinction caused hydration errors
'use client'directive placement was critical but not obvious- TypeScript strict mode revealed issues with async state management in hooks
- Audio playback state required client-side rendering but form could be server-side
- Environment variables needed
NEXT_PUBLIC_prefix for client access
Our Solution:
- Carefully separated server and client components
- Created custom
useStoryGenerationhook with proper TypeScript types - Configured
next.config.tswith proper TypeScript syntax - Implemented proper error boundaries and loading states
3. ElevenLabs Text-to-Speech and Music Generation
The Problem: Integrating both TTS narration AND AI-generated background music from ElevenLabs.
What Went Wrong:
- ElevenLabs API requires proper API key authentication and usage tracking
- Voice selection wasn't straightforward - many options but unclear which sounded best
- Music generation API was newer with less documentation
- Ensuring music had NO LYRICS (instrumental only) required careful prompt engineering
- Audio configuration (sample rate, encoding, stability, similarity) required experimentation
- File size vs quality tradeoffs needed optimization
- API rate limits and quota management for multiple API calls per request
Our Solution:
# TTS: Selected optimal ElevenLabs voice for warm, natural sound
audio = elevenlabs.text_to_speech.convert(
text=story, voice_id="kdmDKE6EkgrWrrykO9Qt",
model_id="eleven_multilingual_v2", output_format="mp3_44100_128"
)
# Music: Generated instrumental-only background music
track = elevenlabs.music.compose(
prompt=music_description, # Explicitly states "no lyrics, instrumental only"
music_length_ms=int(speech_duration * 1000) + 2000
)
4. ElevenLabs Music Generation and Audio Mixing
The Problem: Creating personalized background music and mixing it seamlessly with speech narration.
What Went Wrong:
- Music had to match the exact duration of the speech audio
- Balancing volume levels between speech and music was tricky
- FFmpeg filter_complex syntax for audio mixing was complex
- Music would sometimes overpower the narration
- Temporary file management for multiple audio streams was challenging
Our Solution: Implemented intelligent music generation and mixing:
# Generate music matching speech duration
track = elevenlabs.music.compose(
prompt=music_description,
music_length_ms=int(speech_duration * 1000) + 2000,
)
# Mix with FFmpeg at 15% music volume
command = [
"ffmpeg", "-i", speech_file, "-stream_loop", "-1", "-i", music_file,
"-filter_complex", "[1:a]volume=0.15[a1];[0:a][a1]amix=inputs=2:duration=first",
"-t", str(duration), output
]
5. LangGraph Workflow Orchestration
The Problem: Coordinating multiple AI steps (story generation → music prompt → speech → music → mixing) in the correct sequence.
What Went Wrong:
- State management across 6 different workflow nodes was complex
- Each step depended on outputs from previous steps
- Error in any step would break the entire workflow
- Debugging which step failed was difficult initially
- State typing with TypedDict had to be precise for type safety
Our Solution:
# Built StateGraph with proper edges
graph = StateGraph(StoryState)
graph.add_edge(START, 'generate_story')
graph.add_edge('generate_story', 'generate_music_prompt')
graph.add_edge('generate_music_prompt', 'generate_speech')
graph.add_edge('generate_speech', 'save_and_get_duration')
graph.add_edge('save_and_get_duration', 'generate_music')
graph.add_edge('generate_music', 'mix_audio')
graph.add_edge('mix_audio', END)
This gave us clear workflow visualization and proper error handling at each step.
6. CORS Configuration Nightmare
The Problem: Frontend (localhost:3000) couldn't communicate with backend (localhost:8000) due to CORS.
What Went Wrong:
- Initial CORS middleware configuration was too restrictive
- Audio file serving required special CORS headers
- Preflight OPTIONS requests weren't handled correctly
- Production deployment broke CORS again with different domains
Our Solution:
# Dynamic CORS configuration based on environment
FRONTEND_ORIGIN = os.getenv("FRONTEND_ORIGIN")
allow_origins = [FRONTEND_ORIGIN] if FRONTEND_ORIGIN else ["*"]
app.add_middleware(
CORSMiddleware,
allow_origins=allow_origins, # Configured via environment variable
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
7. File Management and Storage
The Problem: Generated audio files accumulated rapidly, filling disk space.
What Went Wrong:
- No automatic cleanup of old audio files
- File naming conflicts caused overwrites
- Serving files from
outputs/directory wasn't properly configured - File paths were hardcoded, breaking in production
- Memory leaks from file handles not being closed
Our Solution:
# UUID-based unique filenames using session_id
session_id = str(uuid.uuid4())
output = output_dir / f"{session_id}.mp3"
# Proper file path handling
output_dir = Path("outputs")
output_dir.mkdir(exist_ok=True)
# Temporary directories for processing
temp_dir = Path(f"temp_{session_id}")
temp_dir.mkdir(exist_ok=True)
# Clean up temporary files after mixing
shutil.rmtree(temp_dir)
8. Environment Variables and API Key Management
The Problem: Managing sensitive credentials securely across environments.
What Went Wrong:
.envfile almost got committed to Git- Multiple API keys needed management (Gemini AI, ElevenLabs)
- Frontend needed backend URL, backend needed API keys
- Different configurations for development vs production
- Environment variables not loading in Docker container
- FRONTEND_ORIGIN needed for CORS configuration
Our Solution:
# Backend: Load environment variables with python-dotenv
load_dotenv()
elevenlabs = ElevenLabs(api_key=os.getenv("ELEVENLABS_API_KEY"))
# Dynamic CORS based on environment
FRONTEND_ORIGIN = os.getenv("FRONTEND_ORIGIN")
allow_origins = [FRONTEND_ORIGIN] if FRONTEND_ORIGIN else ["*"]
# Port configuration for different environments
port = int(os.getenv("PORT", "8000"))
- Created
.env.exampletemplates - Proper
.gitignoreconfiguration - Documented all required variables clearly (ELEVENLABS_API_KEY, GOOGLE_API_KEY, FRONTEND_ORIGIN, PORT)
- Docker-specific environment injection
9. DigitalOcean Deployment Configuration
The Problem: Moving from local development to cloud production revealed many issues.
What Went Wrong:
- Port binding wasn't configurable (hardcoded to 8000)
- Health check endpoint didn't exist, causing constant restarts
- Build process timed out due to large dependencies
- Static file serving for audio wasn't working
- Environment variables weren't being injected properly
Our Solution:
- Added
PORTenvironment variable support - Created
/healthendpoint for health checks - Optimized Docker build with layer caching
- Configured proper static file mounting
- Created
Procfilefor production startup
Accomplishments that we're proud of
Throughout this hackathon, we achieved several significant milestones that we're genuinely proud of:
Built a Complete Full-Stack AI Application
We successfully created a production-ready platform from scratch, integrating multiple cutting-edge technologies (Next.js 15, React 19, FastAPI, LangGraph) into a cohesive, working system deployed on the cloud.
Orchestrated Complex Multi-AI Workflows
We implemented a sophisticated 6-step AI pipeline using LangGraph that seamlessly coordinates:
- Story generation with Google Gemini AI
- Music prompt creation
- Text-to-speech synthesis with ElevenLabs
- Custom music generation with ElevenLabs
- Professional audio mixing with FFmpeg
This level of AI orchestration is challenging even for experienced developers, and we pulled it off under tight deadlines.
Created Truly Personalized Wellness Content
Our platform doesn't just generate generic stories—it creates personalized narratives with matching background music tailored to individual wellness needs. Each story is unique, with custom audio that brings it to life.
Mastered Audio Processing
We successfully implemented professional-grade audio mixing, balancing speech and music at optimal volumes (15% music volume), ensuring the narration remains clear while the music enhances the emotional atmosphere.
Achieved Production Deployment
We didn't just build a prototype—we deployed a fully functional application with:
- Docker containerization
- Cloud hosting on DigitalOcean
- Environment-based configuration
- Proper CORS and security settings
- Health check endpoints for reliability
Solved Real Technical Challenges
We overcame significant obstacles including:
- Docker containerization with FFmpeg dependencies
- Next.js 15 and React 19 cutting-edge features
- Complex async workflow orchestration
- Multi-API integration and rate limiting
- Production-grade error handling
Focused on Accessibility
We built with inclusivity in mind:
- Audio narration for visually impaired users
- Clean, calming interface for stressed users
- Responsive design for all devices
- Simple, intuitive user experience
Fast Learning Curve
Many of these technologies were new to us, but we:
- Learned LangGraph workflow orchestration from scratch
- Mastered ElevenLabs Music Generation API (brand new technology)
- Implemented Next.js 15 App Router with React 19 (released just months ago)
- Figured out FFmpeg audio mixing complexities
Most importantly, we created something that could genuinely help people manage stress and improve their mental wellness. That's the accomplishment we're most proud of—building technology with real positive impact.
What we learned
About Health & Wellness
- Storytelling is therapeutic: Narratives help people process emotions and see their challenges differently
- Personalization matters: Giving users control over topic and length makes content more relevant
- Accessibility is essential: Audio narration opens wellness content to more people
Technical Growth
- Modern frameworks are powerful but complex: Next.js 15 + React 19 offered great features but steep learning curves
- Workflow orchestration is crucial: LangGraph made complex multi-step AI pipelines manageable and debuggable
- Docker is essential but unforgiving: Every dependency, permission, and configuration matters
- Audio processing is specialized work: FFmpeg mixing, volume balancing, and format conversions require deep understanding
- Multi-modal AI composition: Combining text generation, speech synthesis, and music creation into cohesive experiences
- Cloud deployment is different from local development: Production always reveals hidden issues
- Error handling is as important as features: Users need clear feedback when things go wrong
- AI APIs are powerful tools: Google Gemini AI, ElevenLabs TTS, and ElevenLabs Music delivered excellent results once configured
About Ourselves
- We can build production-ready applications under pressure
- Technical challenges are opportunities to learn deeply
- Mental health tech carries real responsibility—and that's motivating
What's next for Story Weave
We have ambitious plans to expand Story Weave into a comprehensive wellness platform:
Short-Term Goals (Next 3 Months)
Multiple Voice Options
- Add 10+ different narrator voices (male, female, various accents)
- Support for multiple languages (Spanish, French, Mandarin, Hindi)
- Age-appropriate voices for children vs. adults
- Emotion-specific voices (calming, energetic, soothing)
User Accounts & History
- User authentication and profiles
- Save favorite stories and replay them anytime
- Track wellness journey with usage analytics
- Personalized recommendations based on listening history
Enhanced Story Customization
- Story genre selection (meditation, motivation, sleep stories, affirmations)
- Tone customization (calm, inspiring, educational, playful)
- Add character names or personal details for deeper personalization
- Save custom preferences for quick generation
Mobile Applications
- Native iOS app with offline playback
- Native Android app with background audio
- Push notifications for daily wellness reminders
- Widget support for quick story generation
Medium-Term Goals (6-12 Months)
Professional Tier
- Tools for therapists to generate custom content for clients
- Wellness coaches can create personalized story libraries
- Educational institutions can use for mindfulness programs
- Corporate wellness program integration
Advanced Audio Features
- Adjust music volume in real-time
- Mix multiple music tracks
- Add ambient sounds (rain, forest, ocean waves)
- Binaural beats for meditation and focus
Community Features
- Share anonymized stories (with permission)
- Community library of popular wellness stories
- Rating and feedback system
- Collaborative story creation
Analytics Dashboard
- Track which topics help most with specific wellness goals
- Measure engagement and completion rates
- A/B testing for different story structures
- Mood tracking before and after listening
Long-Term Vision (1-2 Years)
AI Personalization Engine
- Learn from user preferences over time
- Suggest optimal story length based on time of day
- Adapt story complexity to user feedback
- Predictive wellness content recommendations
Wearable Integration
- Connect with Fitbit, Apple Watch, Whoop
- Generate stories based on stress levels from biometric data
- Adaptive content based on heart rate variability
- Sleep quality tracking with bedtime stories
Video Content
- Animated visuals to accompany stories
- Guided meditation videos with narration
- Motion graphics synchronized with music
- VR/AR experiences for immersive storytelling
Research & Impact
- Partner with mental health researchers
- Measure effectiveness through clinical studies
- Publish findings on AI-powered wellness interventions
- Contribute to open-source wellness tools
Automated Content Moderation
- AI-powered content filtering for safety
- Age-appropriate content validation
- Trigger warning detection and labeling
- Community moderation tools
Scheduled Cleanup & Optimization
- Automatic deletion of old audio files after 24 hours
- CDN integration for faster audio delivery
- Caching strategies for popular stories
- Database for storing metadata and user preferences
Technical Improvements
- Streaming Audio: Real-time audio streaming instead of waiting for full generation
- Progressive Enhancement: Show story text while audio is being generated
- Background Processing: Queue system for handling multiple requests efficiently
- API Rate Optimization: Implement intelligent caching and request batching
- Cost Optimization: Explore cost-effective alternatives for scaled production
Our ultimate goal: Make Story Weave the go-to platform for personalized, AI-powered wellness content that's accessible, effective, and scientifically backed. We envision a world where everyone has access to customized mental wellness support, anytime they need it.
Built By
Muhammad Jawad - AI Engineer
Muhammad Jawad served as the AI Engineer, specializing in the intelligent backend architecture of Story Weave. With deep expertise in AI/ML systems and natural language processing, Jawad architected the LangGraph workflow orchestration that seamlessly coordinates multiple AI services. He implemented the integration with Google Gemini AI for context-aware story generation and crafted sophisticated prompts that ensure stories are emotionally resonant and therapeutically valuable. Jawad also designed the intelligent music prompt generation system that creates perfect musical accompaniment for each story's emotional tone. His focus on AI optimization ensured the system generates high-quality, personalized wellness content efficiently.
Key Contributions:
- Architected LangGraph workflow for multi-step AI orchestration
- Integrated Google Gemini AI (gemini-2.5-pro) for story generation
- Designed sophisticated prompt engineering for therapeutic storytelling
- Implemented AI-driven music prompt generation system
- Optimized AI API calls and response handling
- Developed structured output schemas for reliable AI responses
- Created story length and tone optimization algorithms
Hamad Khan - AI Engineer
Hamad Khan co-led the AI engineering efforts, focusing on the audio intelligence aspects of Story Weave. With expertise in speech synthesis and audio AI, Hamad integrated ElevenLabs' Text-to-Speech and Music Generation APIs to create the immersive audio experience. He researched and selected optimal voice models for warm, natural narration and fine-tuned audio parameters (sample rate, encoding, stability) for the best quality. Hamad also implemented the intelligent music generation system that creates instrumental-only background music precisely matched to speech duration, ensuring seamless audio experiences that enhance the wellness journey.
Key Contributions:
- Integrated ElevenLabs Text-to-Speech API with optimal voice selection
- Implemented ElevenLabs Music Generation API for custom soundtracks
- Configured audio quality parameters and encoding settings
- Developed duration-matching algorithm for music generation
- Ensured instrumental-only music through careful prompt engineering
- Optimized API rate limiting and quota management
- Tested and validated audio output quality across different story types
Ali Ahmad - Full-Stack Developer
Ali Ahmad led the full-stack development of Story Weave, bridging frontend and backend systems into a cohesive platform. With expertise in modern web technologies, Ali built the responsive Next.js 15 frontend with React 19, implementing the clean, calming user interface with Tailwind CSS 4. He developed the FastAPI backend server, handling async operations and RESTful endpoints. Ali architected the file management system using UUID-based naming, implemented the audio mixing pipeline with FFmpeg, and managed the complex state flow between frontend and backend. His focus on user experience ensured the platform is intuitive and accessible for users seeking mental wellness support.
Key Contributions:
- Built Next.js 15 frontend with React 19 and TypeScript
- Developed FastAPI backend with async request handling
- Implemented FFmpeg audio mixing for speech and music
- Created responsive UI with Tailwind CSS 4
- Developed custom React hooks for state management (useStoryGeneration)
- Architected file storage system with UUID-based naming
- Implemented RESTful API endpoints and error handling
- Configured frontend-backend communication with Axios
Muhammad Ilyas - Full-Stack Developer
Muhammad Ilyas co-led the full-stack development, specializing in deployment and infrastructure. With expertise in DevOps and cloud technologies, Ilyas handled Docker containerization, ensuring all dependencies (FFmpeg, Python libraries) were properly configured. He managed the DigitalOcean deployment, configured environment variables for secure API key management, and set up dynamic CORS policies for production. Ilyas also implemented the audio player component with playback controls, developed the loading and error state management, and ensured the application is production-ready with proper health checks and monitoring. His attention to deployment details made Story Weave reliable and scalable.
Key Contributions:
- Configured Docker containerization with FFmpeg dependencies
- Deployed application to DigitalOcean App Platform
- Implemented environment variable management and security
- Set up dynamic CORS configuration for production
- Developed audio player component with playback controls
- Created loading states and error handling UI components
- Configured Gunicorn and Uvicorn for production server
- Set up health check endpoints and monitoring
- Managed Git version control and repository structure
Team Collaboration
Together, our team of two AI Engineers and two Full-Stack Developers brought complementary skills that made Story Weave possible. We collaborated through pair programming sessions, code reviews, and daily standups to integrate complex AI services with robust full-stack infrastructure. Our shared passion for mental wellness technology drove us to overcome technical challenges and create a platform that could genuinely help people.
Technologies Used: Next.js 15.5.5, React 19.1.0, TypeScript 5.x, Python 3.11.9, FastAPI, Google Gemini AI (gemini-2.5-pro), ElevenLabs Text-to-Speech & Music APIs, LangGraph, LangChain, FFmpeg, Docker, DigitalOcean, Tailwind CSS 4, Axios, Gunicorn, Uvicorn
Repository: github.com/JawadGigyani/StoryWeave
Final Thoughts
This hackathon pushed us far beyond our comfort zones. We didn't just build a wellness app—we battled Docker containers at 2 AM, debugged CORS errors for hours, integrated multiple AI APIs from scratch, and discovered that FFmpeg is both incredibly powerful and incredibly frustrating.
But every technical challenge taught us something valuable:
- Every deployment failure made our solution more robust
- Every bug we squashed brought us closer to helping real people
- Every hour spent on error handling improved the user experience
We used Google's Gemini AI for intelligent story generation, ElevenLabs Text-to-Speech for natural, lifelike narration, and ElevenLabs Music Generation for personalized instrumental soundtracks—all orchestrated through LangGraph workflows. This proves that modern AI can make wellness content truly personalized, immersive, and engaging.
Because wellness shouldn't be one-size-fits-all. It should be as unique as the people seeking it.
And now, despite all the technical hurdles, we have a working platform that proves technology can make mental wellness more accessible, personal, and engaging. From form input to AI-generated story to audio narration—it all works together to create something genuinely helpful.
Built With
- axios
- digitalocean
- docker
- elevenlabs-text-to-speech-&-music-apis
- fastapi
- ffmpeg
- google-gemini-ai-(gemini-2.5-pro)
- gunicorn
- langchain
- langgraph
- next.js
- python
- python-3.11.9
- react-19.1.0
- react.js
- tailwind-css-4
- typescript
- typescript-5.x
- uvicorn
- vercel





Log in or sign up for Devpost to join the conversation.