-
-
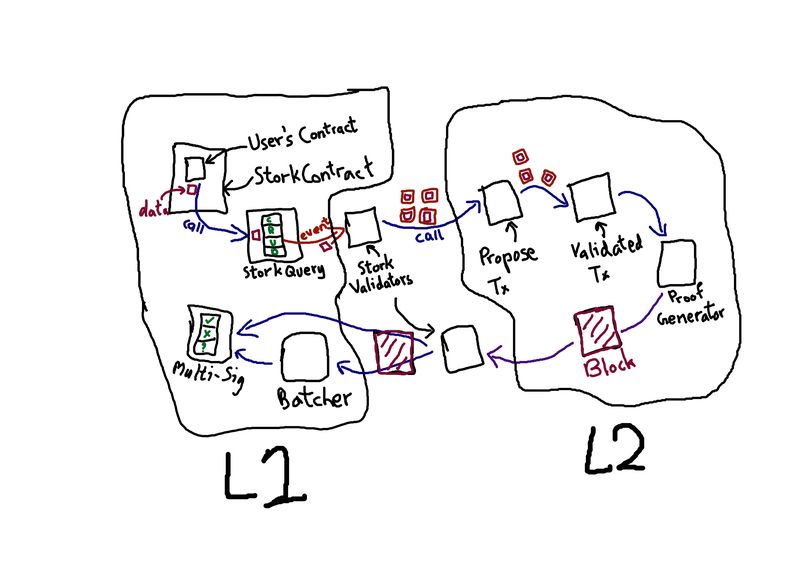
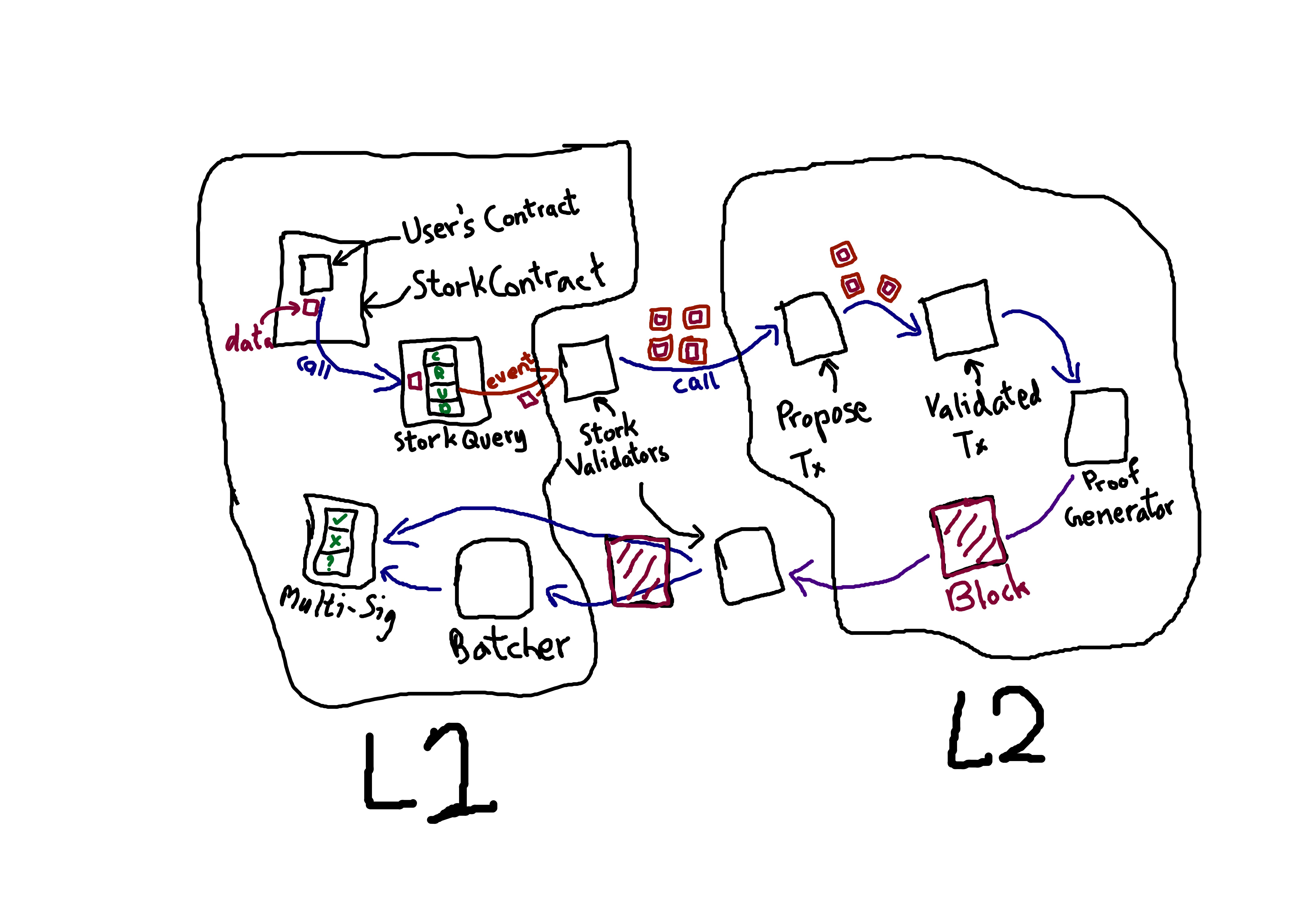
Architecture Flow
-
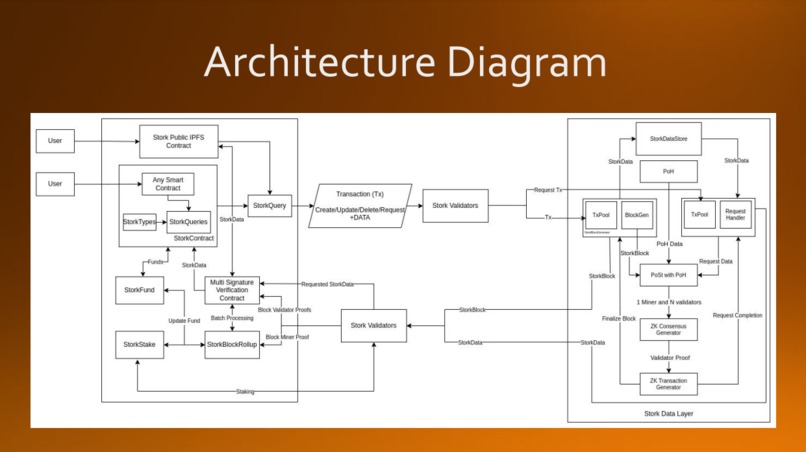
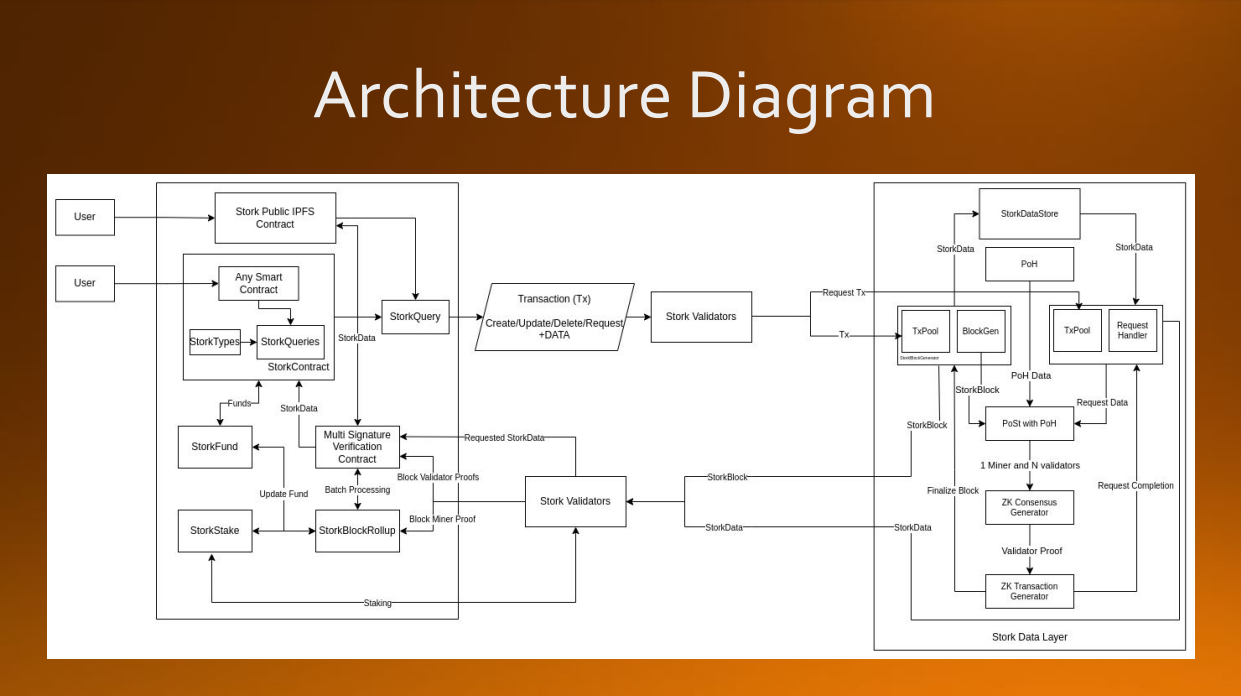
Architecture Diagram
-
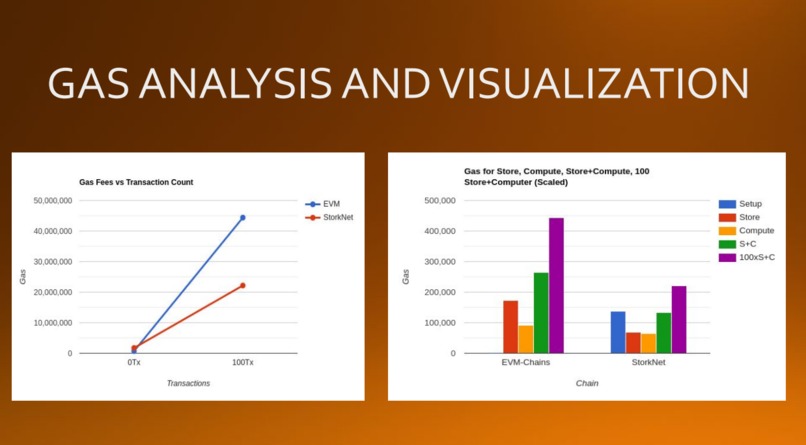
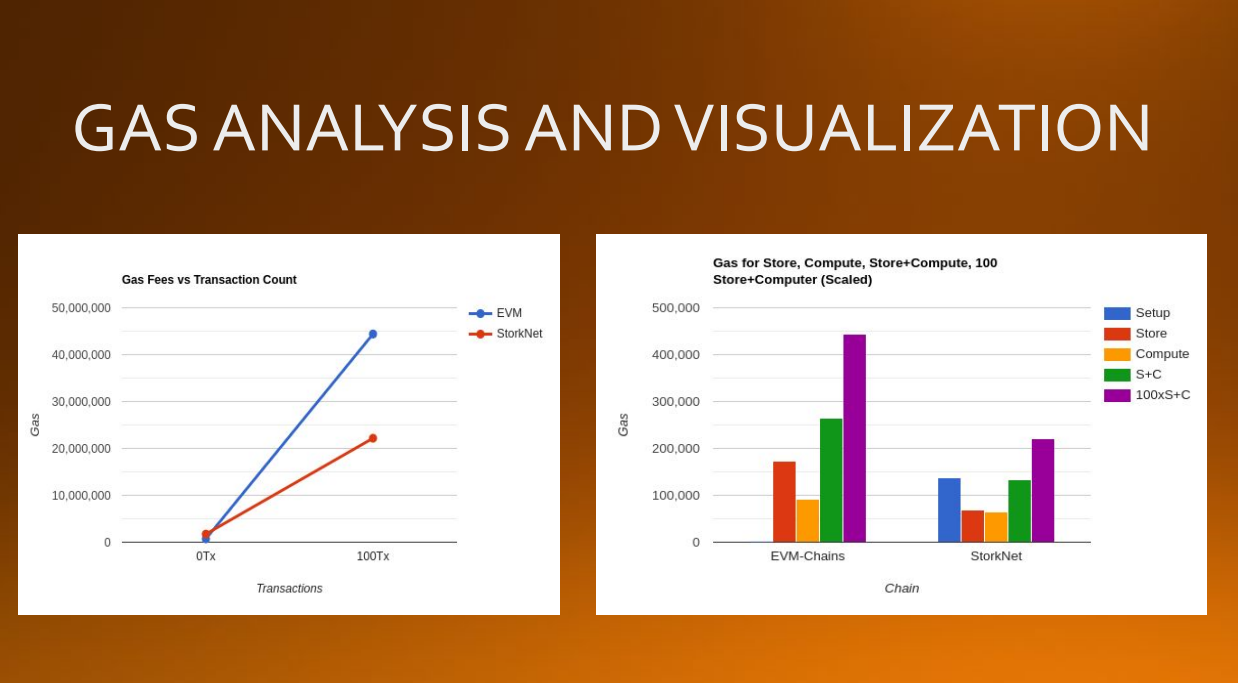
Gas Analysis Graphs
-
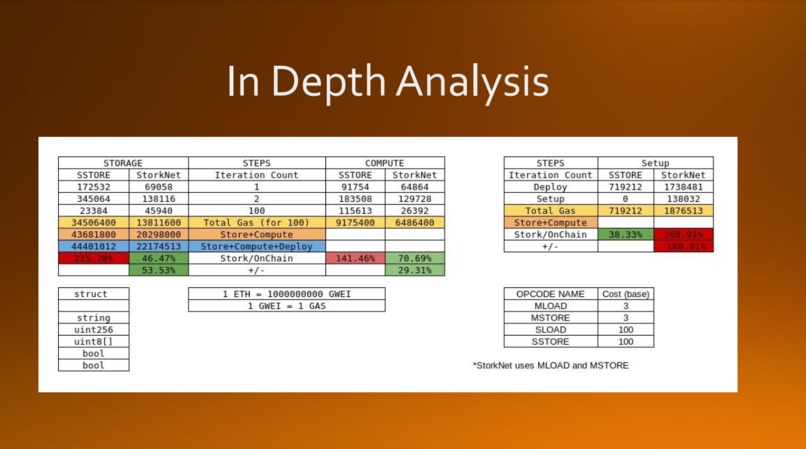
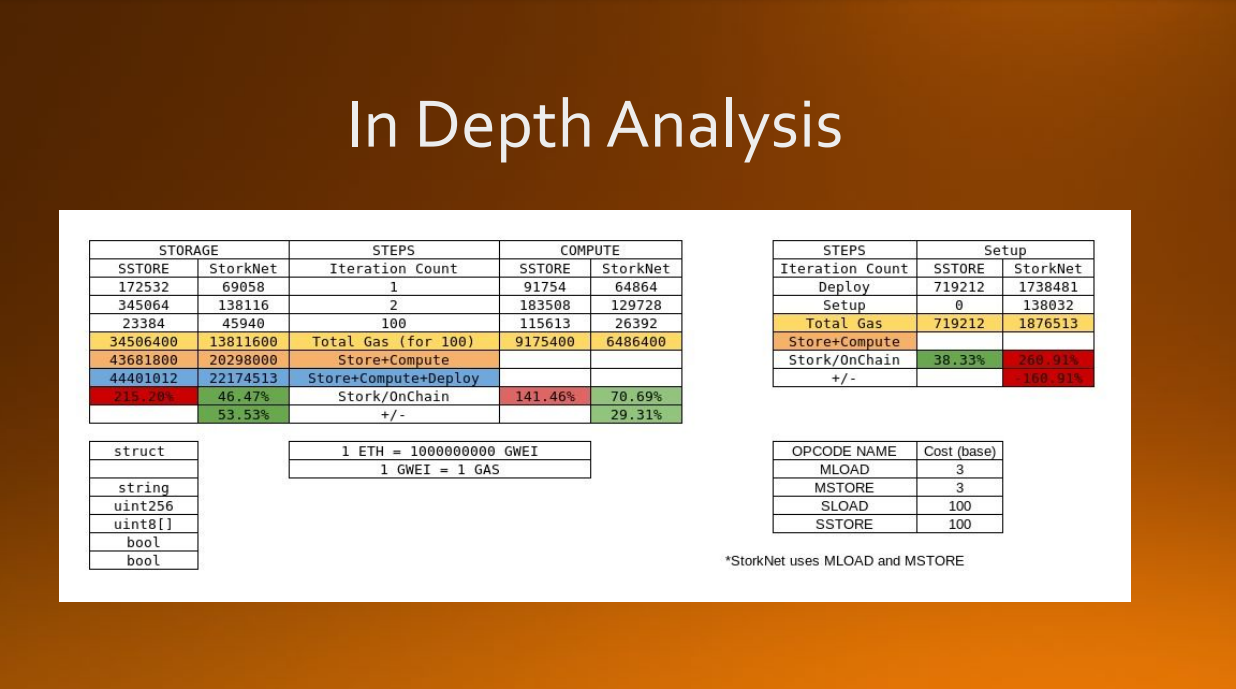
Indepth Gas analysis
Inspiration
Modularity and data storage are two regions of computer science architecture that I've been interested in. As blockchains by nature are quite monolithic and also function as black boxes where data stored on one chain is pretty much locked onto it. This combined with the high gas fees of the SSTORE opcode led me to think that decoupling the data storage layer from the execution layer could benefit not only the gas fees but also allow for cross chain data and function interoperability.
What it does
Each execution-EVM chain (L1, L2, etc) have smart contracts that contain data within them. The data-layer StorkChain can be interacted with by queries. The queries and the libraries required to execute the queries are deployed on the execution-EVM chains, these allow the smart contracts to interact with the data-layer, StorkChain.
The smartcontracts need to be coded in a querying style. These queries are picked up by staked validators and dumped on StorkChain, that undergoes a consensus round that executes periodically.
The transactions executed on StorkChain are the queries (Create, Request, Update, and Delete).
Create and Update data are as simple as calling the Create function with the data that needs to be stored.
Request data however includes the fallback function's name, the destination network, and smart contract address.
How we built it
Learning about oracle networks, mongoDB, and other similar products helped design the protocol.
The data-layer is essentially a blockchain ontop of an EVM network, it has it's own consensus mechanism, staking, block generation, etc.
Challenges we ran into
Deciding the format of data being stored as EVM data types don't declare the types, so there had to be a way to tell the data-layer that this string of bytes can be decoded with this datatype tuple so that parametric querying can be done.
Accomplishments that we're proud of
Creating a demo that functions for the L1 side of the protocol and the data-layer itself, along with a working rollup.
Creating a custom data-type formatting that declares the variables and their types, so that the network can understand the data being stored.
Architecting something this large took a lot of time and revisions, especially the blockgenerator on the data-layer.
Managing to reduce gas costs while also allowing for cross-chain interoperability.
What we learned
A decent amount of Oracle networks from Chainlink white papers, and from mongoDB.
How rollups and bridges work.
What's next for StorkNet
Increasing the number of queries and create sharding for parallel executions for more throughput.
Allow web2 application to use StorkNet too.
Built With
- data-layer
- foundry
- geth
- gitpod
- hardhat
- oracle-networks
- solidity

Log in or sign up for Devpost to join the conversation.