-
-
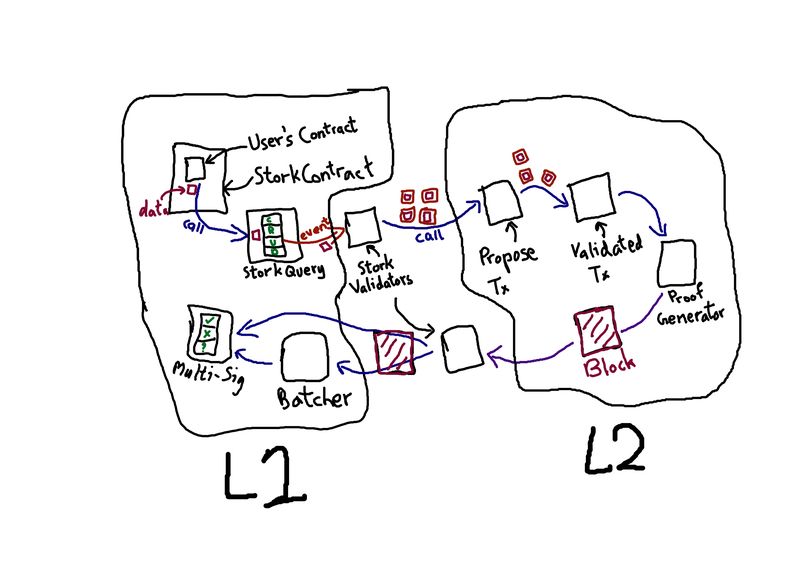
The run though example
-
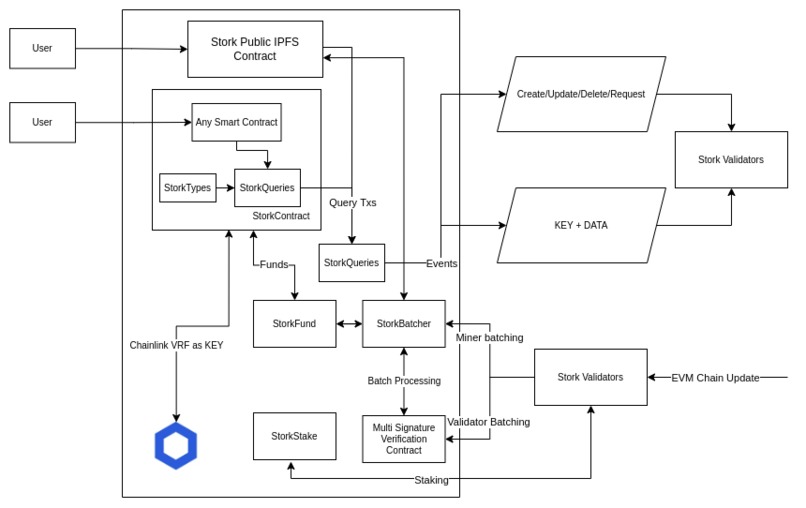
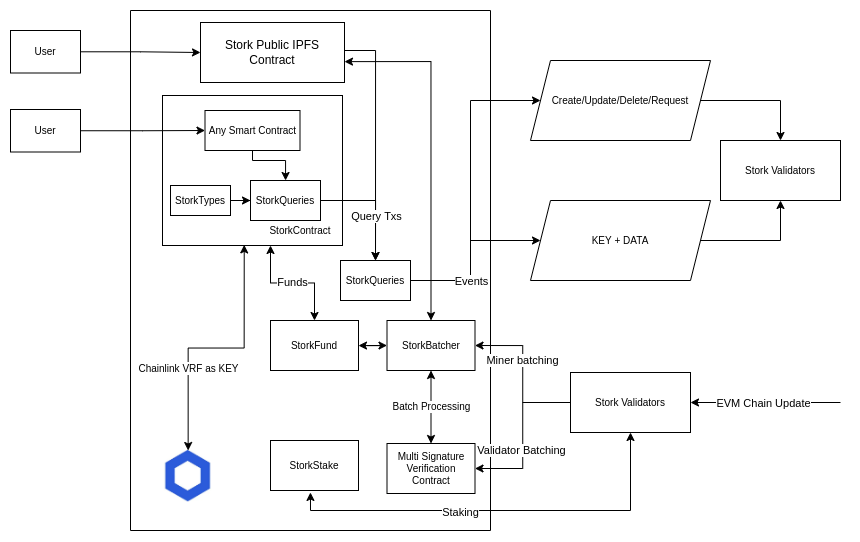
Architecture Diagram of L1
-
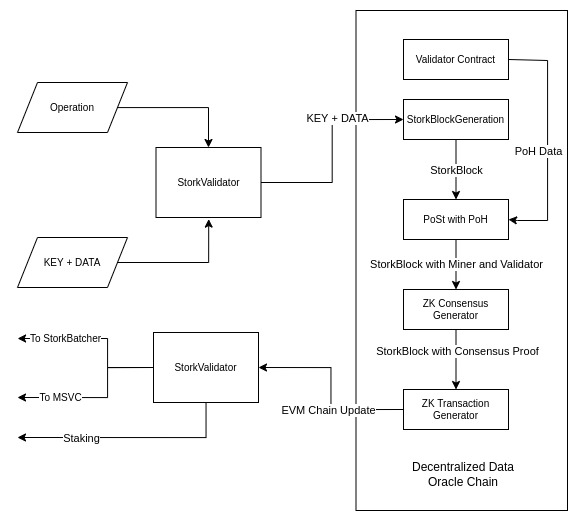
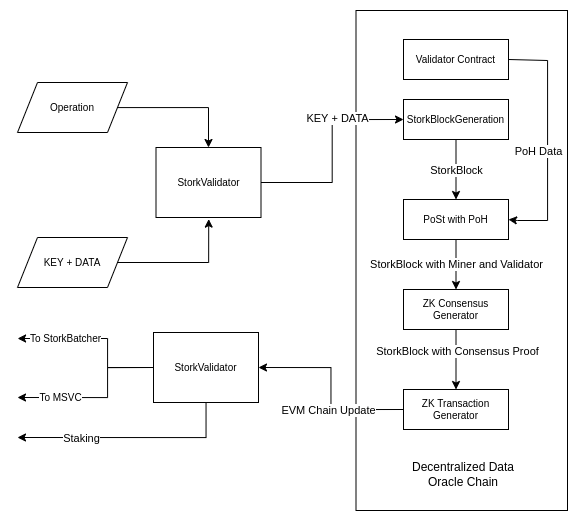
Architecture Diagram of L2
Inspiration
The high gas fees on L1's and the very high cost of storing and reading storage variables made me think, is this why we don't have large scale projects like how we do on centralized systems? The programs where there is a mountain of data being stored just to be interacted with users.
What it does
The "hybrid contracts" on L-1 import our StorkContracts as a library similar to openzeppelin's ERC-20, and now start querying data to and from StorkNet through queries. Queries are the CRUD operations, so you can say that the entire project is kinda like a database for smart contracts.
How we built it
After figuring out the parts involved the entire thing was coded on solidity, the L-2 chain essentially is any ETH fork but ontop of that has our implementation of a blockchain, it has its own consensus, networking, block production, proof of data and transactions (each transaction is just a query that is made to StorkNet) created using non-interacting ZK hashes.
Challenges we ran into
- The networking part was pretty tough,
- Figuring out the different smart contracts required as a monolithic approach would be ill suited for the project
Accomplishments that we're proud of
- Creating the database part
- The consensus mechanism that we used
- The fact the entire project was coded in just over a week
What we learned
- Creating a "common data storage type"
- Creating queries
- Batch operations on queries
- ZK proofs
- Oracle systems
What's next for StorkNet
- Increase the number of queries that are possible
- Maybe find a way to reduce the deployment cost of each hybrid contract (the extra code that you need to import while making the contract is about 2.6x the cost of a regular deployment)
- Improve the security of the protocol
- Do some hardcore testing, and patch up bugs
- Patch up security vulnerabilities using tools like slither and others from Crytic, trailofbits
Built With
- chainlink
- moralis
- remix
- solidity
- typescript


Log in or sign up for Devpost to join the conversation.