Inspiration
The Sustainable Hopkins Innovative Projects (SHIP) club is hoping to start a new project this semester, in collaboration with Friends of Stony Run, to remove invasive plants found on the Stony Run Trail near campus. This new sustainability venture calls for an innovative software system to connect SHIP members, Hopkins volunteers, Friends of Stony Run, and everyday hikers. It is difficult to keep track of heavily overgrown areas and where weed removal efforts are already in progress along the 3-mile path. Additionally, identifying the invasive species can be very difficult for new volunteers. We are passionate about getting JHU students to be more conscious of the invasive species surrounding us and making it easier to take action!.
What it does
Our website will facilitate trail-clean-up efforts in two major domains: tracking and identification.
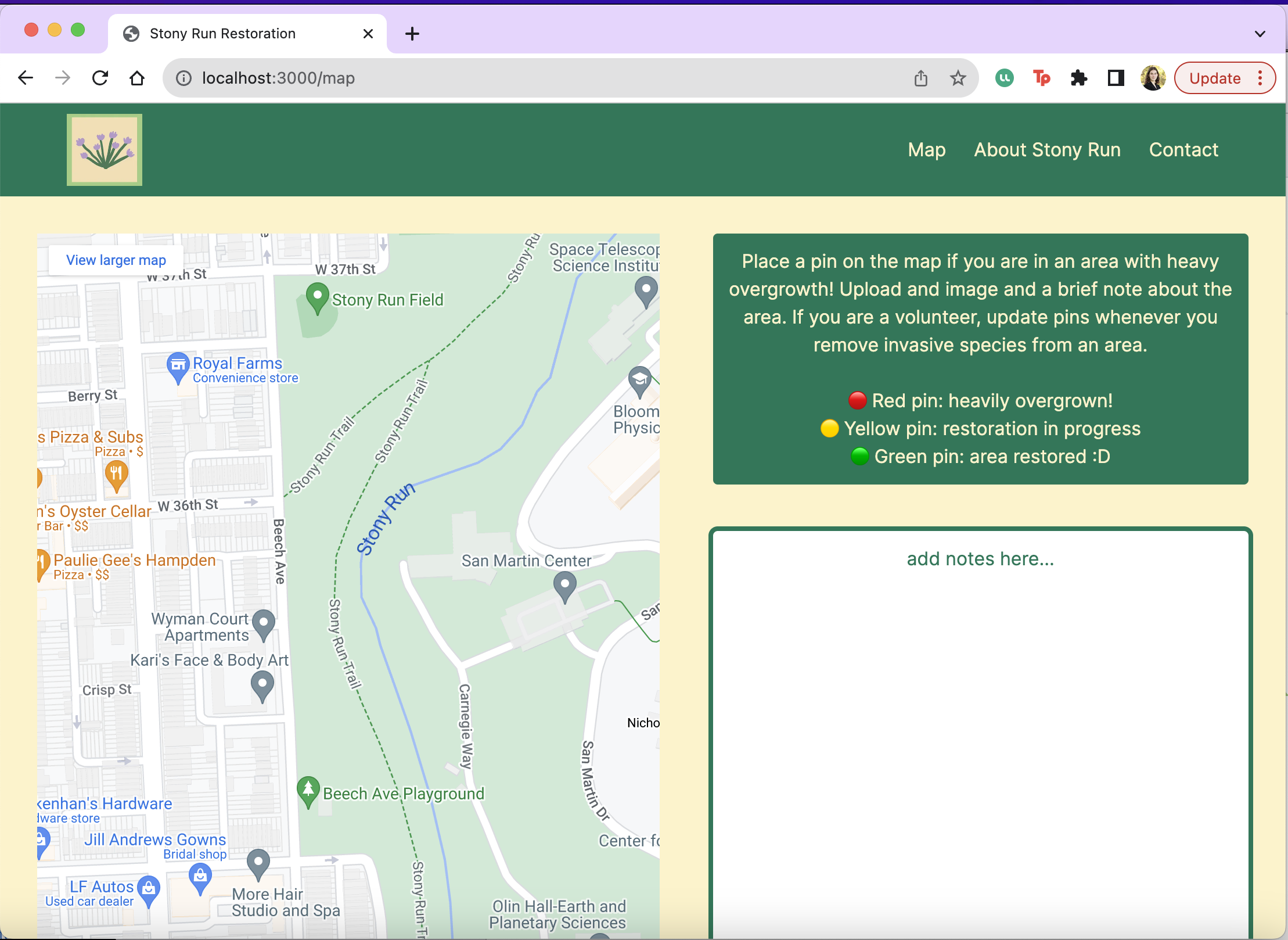
- Tracking: Using Google Maps API, users will be able to drop pins along a map of Stony Run Trail to communicate where there is need for weed removal along with a feature to add notes and images regarding the specific area. Student volunteers will then be able to visit those pinned areas and mark their efforts on the map. Red pins will indicate the location of invasive species that need to be removed, while the green pins will indicate the places where invasive species have already been removed.
- Identification: We will have a built in AI model that is able to classify invasive and native species in a photo of a given area. This tool will significantly reduce the barrier for entry to become a volunteer cleaning Stony Run. ## How we built it We built a Python web crawler, using the 'Requests' library to send HTTP requests, and the 'Beautiful Soup' library for parsing HTML. Our program saved the images into a large dataset. We then used 'TensorFlow' to preprocess our data. Specifically, we resized the images to a consistent size so that they had the same dimensions for training. We also did some data augmentation, including random zooming, random flips, and random brightness augmentations. This technique helped reduce overfitting. Subsequently, we split our data into the training set and the test set in an 80-20 ratio, and trained our model. We used Next.js, a React framework, to develop the website frontend.
Challenges we ran into
There were lots of unforeseeable challenges. For example, the web scraping process what more challenging than we thought it would be. It turns out that the Google API restricts web scraping to 20 images, as it is a dynamic website. To build an accurate model, we needed hundreds, if not thousands, of images. We had to think of ways to circumvent that problem. Finally, we decided to do multiple searches of the same plant, with slight variations in each search.
Accomplishments that we're proud of
None of us have ever built a web app before, so it was really exciting to watch this project come together!
What we learned
We each have acquired a new, unique, and useful skillset from this project including basic front end web-dev and neural network training.
What's next for Stony Run Restoration
Given our limited experience and time constraints, this project is still very much in the works. All of our members are looking forward to continuing development of the website, and we are extremely excited to get more students and other users of the Stony Run Trail on board with our project!
Built With
- beautiful-soup
- css
- google-maps
- html5
- javascript
- next.js
- python
- react
- tensorflow

Log in or sign up for Devpost to join the conversation.