

Abstract
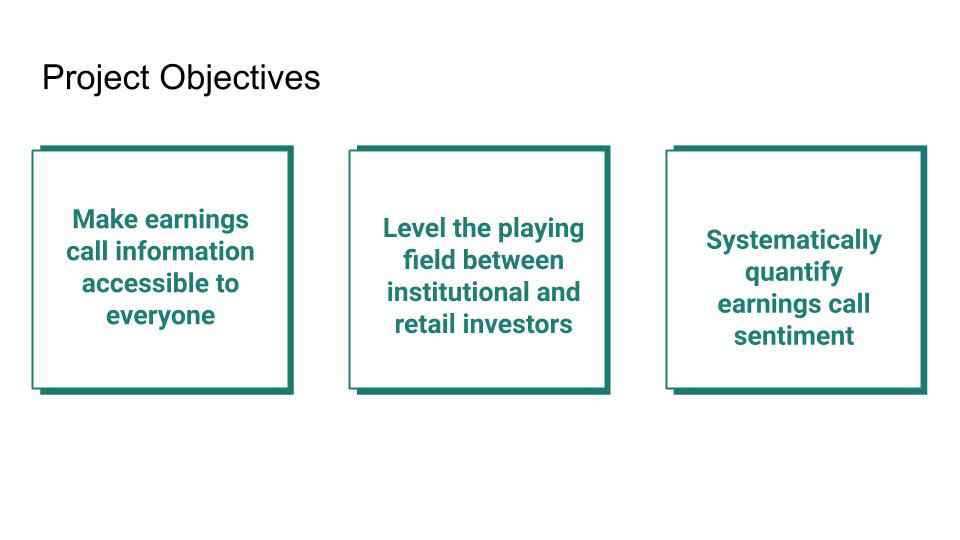
Corporate earnings calls contain valuable information about a company’s performance and future outlook; however, oftentimes, individual investors do not have the time or the resources to analyze the information being conveyed in the audio recordings of these calls quickly enough to make important investment decisions. Typically, past sentiment analysis work has mainly focused on transcripts rather than the actual audio of the earnings call. We want to make this information widely accessible by concisely quantifying the sentiment from the audio of the calls so that retail investors can make informed decisions using the information contained in the calls. Our solution will analyze the raw audio content of earnings calls using sentiment analysis techniques for audio signals.
Methods
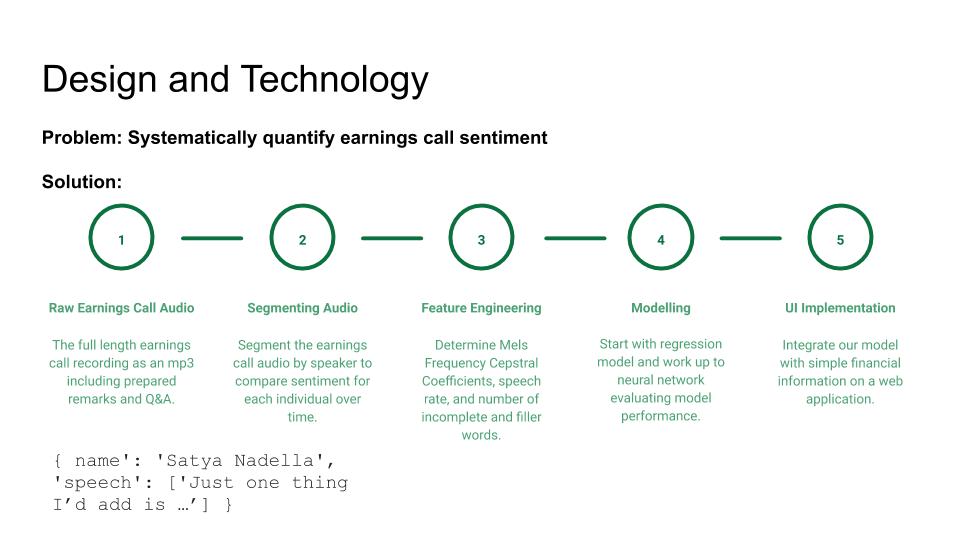
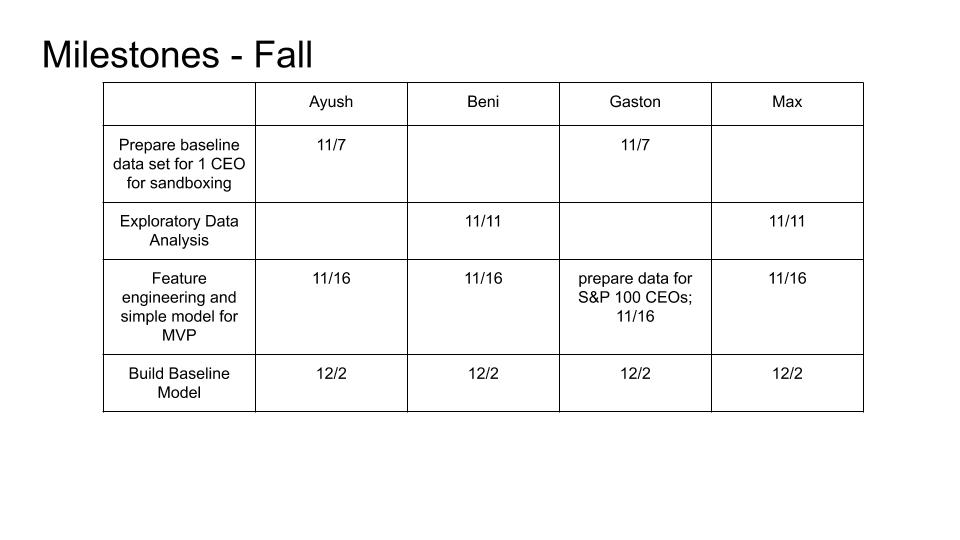
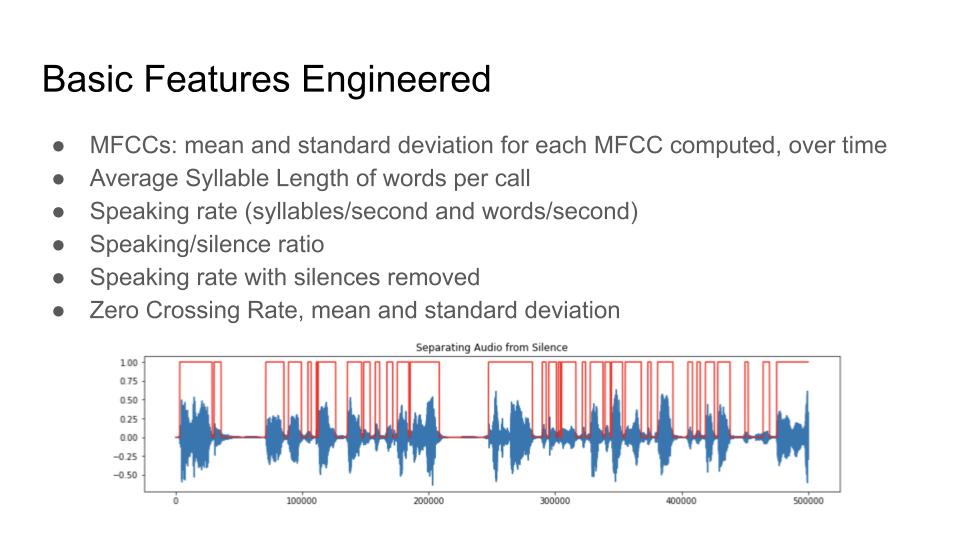
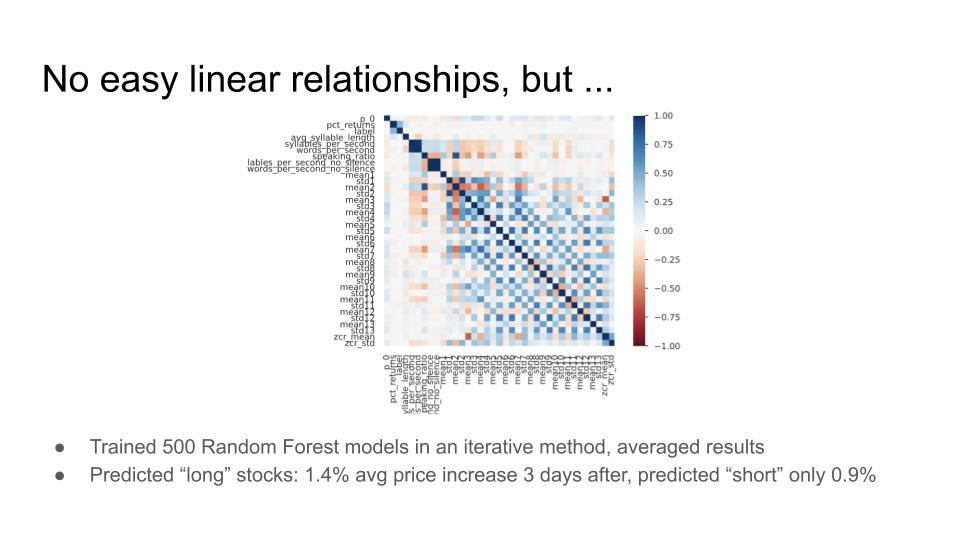
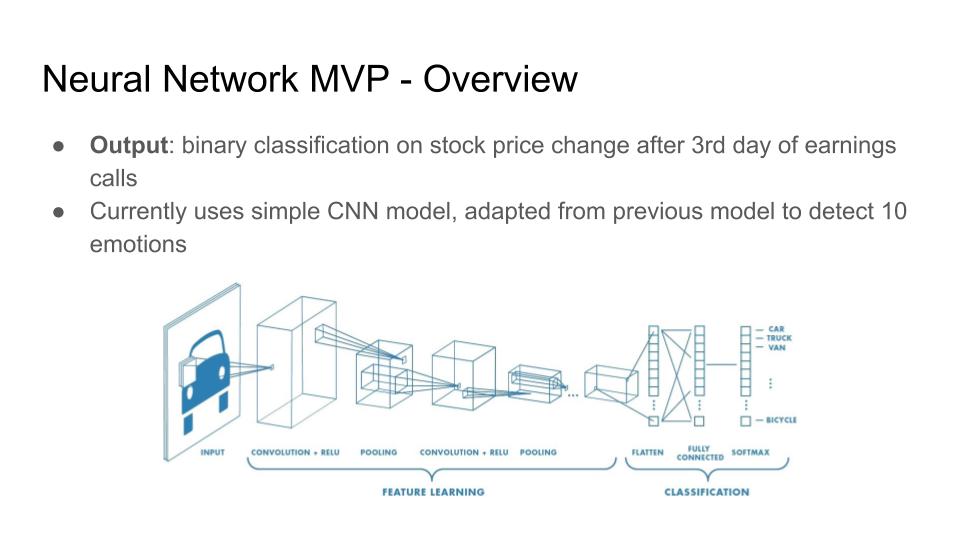
So far we have used a convolutional neural network as a binary classifier to predict whether a stock will go up or down within the three day window following an earnings call based on a variety of audio features extracted from the recording of the earnings call. Some features we have included in our model are Mel-frequency cepstrum coefficients (MFCCs) (mean and standard deviation throughout a speech instance), speaking rate, silence ratio, and zero crossing rate. In order to engineer and compute these features for specific speakers, we used a Python library called aeneas to force alignment between the audio transcript and the audio recording and then select only the parts of the audio that corresponded to the speakers relevant to our model (in this case, the CEO of each company). After computing the feature values, we fed them into our convolutional neural net, which made predictions of which companies' stocks would go up and which would go down.
Next steps
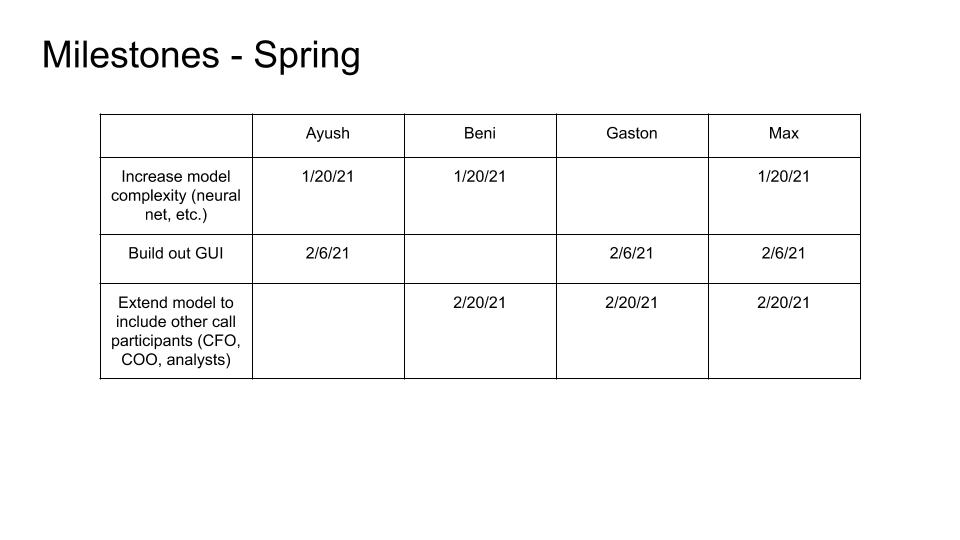
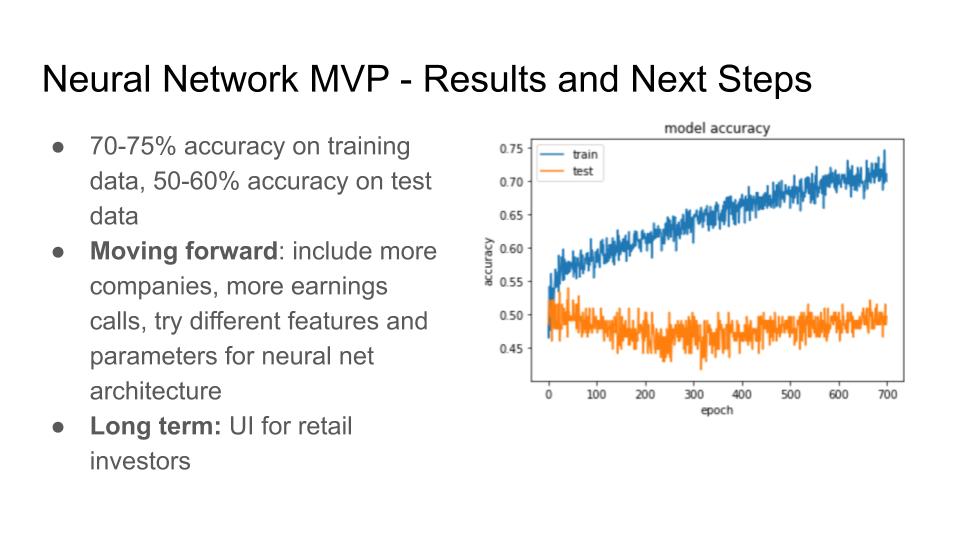
So far, we have focused mostly on an end-to-end neural network design based on features that are mostly uninterpretable. This has yielded us a moderately successful model. Next, we plan to make improvements in two ways: 1) Making adjustments to the neural network architecture in order to improve the performance of the model on the existing features, and 2) Investigating a different approach wherein we use a neural network to extract interpretable quantifications of speaker sentiment from the earnings call audio and subsequently using these interpretable sentiment features as inputs to a potentially simpler model. We believe that both approaches are promising, and we have already started laying the groundwork for work on both fronts.

Log in or sign up for Devpost to join the conversation.