-
-

stockroom logo
-
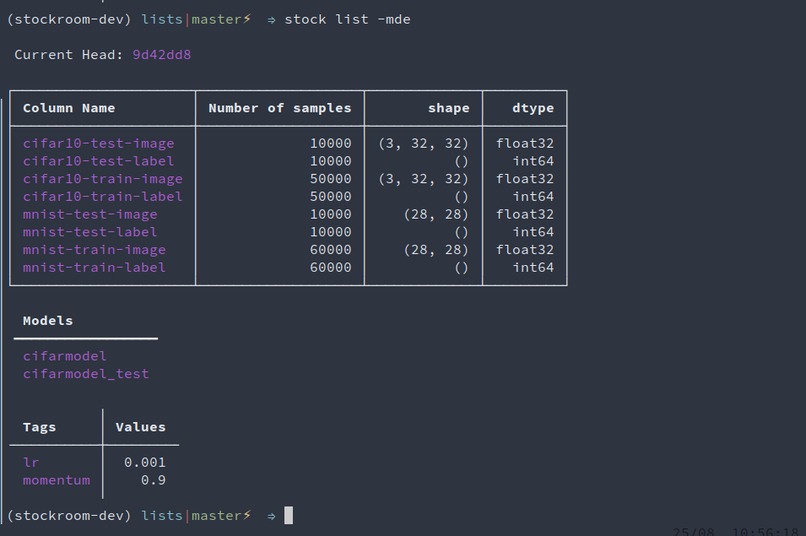
listing data, model and experiments
-
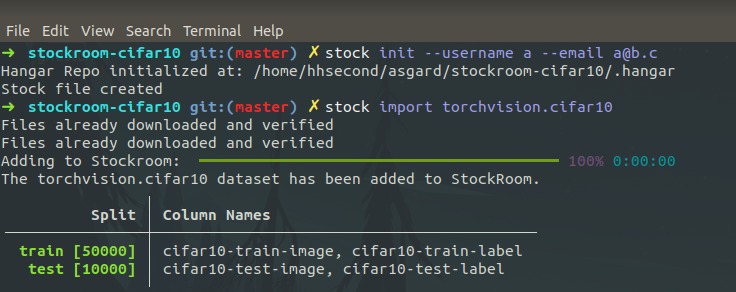
Adding data to stockroom with cli


Inspiration
Version controlling for machine learning is not a solved problem although there are several attempts. The major challenge is that the software 2.0 consist of different components such as code, model, data, and experiment parameters. All the existing attempts that we know have taken a similar approach to version controlling ML but comes with different APIs or different features as their USP. But we had realized the need for a completely different, radical enough, approach that could change the way versioning story has been written
What it does
Versioning data/model/experiment is important. Let's look at some of the challenges
- These entities could be huge in size. Copying and deleting them on each git checkout is just not efficient
- Time-traveling through the commit history is extremely hard since that involves moving of this GB/TB/PB of data between folders (something like what git does - moving files from
.gitto the root of the repo) - You'd need to version your code. So it's ideal if you can manage to have your version control system like
gitgo hand in hand with the version controlling system for ML - Model parameters are tensors under the hood. Storing them as tensors would open the possibility of easily analyzing them
- It's very often a case that the whole data is not fittable into an end system like a laptop. Ability to partially fetch the data is important
- It is very likely that you run a lot of experiments and saves model parameters multiple times. If somebody would need to fetch all of these experiments only to use that last successful, optimized one, it's a pity. Ability to clone some part of repository is important
- Direct integration to common frameworks saves time. For experts and for beginners.
- Collaboration is the key, but it's painful if every collaborator need to have the complete repository with them to add more data or a new model and some experiment parameters
Any modern ML versioning system that relies on traditional version controlling software has these underlying limitations. With stockroom (through hangar) we introduce a new approach. We keep the data in a common format in a backend and make it accessible only with our python APIs. Your repository also keeps the metadata about your data (including the content hash) so that another person can clone only the metadata (few Mbs in size) and start collaborating without fetching the whole repository. You will also have the ability to fetch data by name instead of cloning the whole
PS: Stockroom is built on top of hangar
How we built it
Stockroom, right now, only be able to take tensors, ints, floats, or strings as input. We have built the whole platform on top of hangar which is optimized for tensor storage. We have made three user interfacing classes (we call it shelves).
- Data
- Model
- Experiment
Each shelf knows what data it would get and choose the right optimization strategy in the backend. We have made the python API dictionary-like so that it wouldn't introduce a learning curve.
Data
Dealing with data in the stockroom is done through the Data shelf.
from stockroom import StockRoom, make_torch_dataset
stock = StockRoom()
image = stock.data['image']
label = stock.data['label']
image[0].shape # something like (3, 224, 224)
label[0].shape # almost always ()
dataset = make_torch_dataset([image, label])
But how would we add data into the stockroom. You can use the same APIs but it's ideal to use the importers since we are doing some more optimization to increase the data saving speed. We have made some of the pytorch ecosystem datasets built into stockroom (more on the way) and it is available through the stock CLI. This is how you would import cifar10 into stockroom from torchvision
~$ stock import torchvision.cifar10
Model
The model shelf is designed to take the parameters returned from state_dict() call. StockRoom takes each layer and saves it as a tensor. Metadata of these layers would be saved separately. We build it back when it is accessed. Stockroom's storage is content addressed. So if you are training only a few of the layers and other layers are frozen, we will be able to save only the changed parameters from your state_dict and keep a reference to the non-changed parameters
stock = StockRoom(enable_write=True)
mymodel = get_model()
# training
stock.model['resnet'] = mymodel.state_dict()
# loading from checkpoing
newmodel = get_model()
newmodel.load_state_dict(stock.model['resnet'])
Experiment
This shelf is for storing your hyperparameters, other details you'd like to track as part of your training etc. We'd wanted to make it take activations from intermediate layers as well if you wish to save them. But we couldn't do for the hackathon.
stock = StockRoom()
# training loop
with stock.enable_write():
stock.experiment['lr'] = lr
Challenges we ran into
The major hurdle for any storage system is to keep the data consistent and keep from corruption. Thus hangar allows only one write-enabled object to be created. Working with this limitation while keeping a sane and easy UI (in python) was an extremely difficult UX problem. Because we'd want to send the readers to multiprocessed dataloaders while keeping them from not writing into the storage from multiple processes. Dealing with different types of dataset was another big concern. Different datasets have different properties and hence having a proper way of interacting with data without introducing complexities was tough.
Accomplishments that we are proud of
Stockroom itself is a proud entity for all of us. It's efficient, it's easy, it fits into users' coding style and the user doesn't need to learn another tool to start using stockroom. We are also planning about stockroom universe where we could make utilities like finding data leak or visualizing weights etc that could go well with stockroom's API
What we learned
The way PyTorch users interact with data and model was an invaluable knowledge that we have gained by talking to different people. Building a tool like stockroom would teach you a ton!. Storage optimization, API design etc. And it will expose a 1000 different problems that you'd otherwise never see. For instance, what if you have 100 TB data and you are using 1000 nodes for a distributed training setup. You'd be downloading this huge dataset to all the shards/nodes. But what if stockroom's partial cloning would help you here and download only what is required for each node on the fly. It's possible with stockroom and we would have never thought about a possibility like this if it wasn't for stockroom
What's next for stockroom
We are excited. We have a laid-out roadmap in our wiki that has few things that we would want to build soon. But in general, I think we'd want to work on stockroom and make it a super light weight, easy to learn but highly efficient and version controlling system that is tightly coupled to pytorch and it's ecosystem tools




Log in or sign up for Devpost to join the conversation.