-
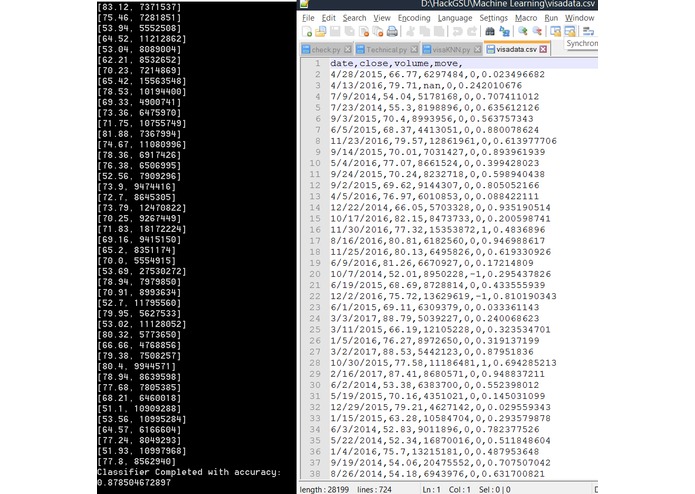
KNN Classifier for VISA
-
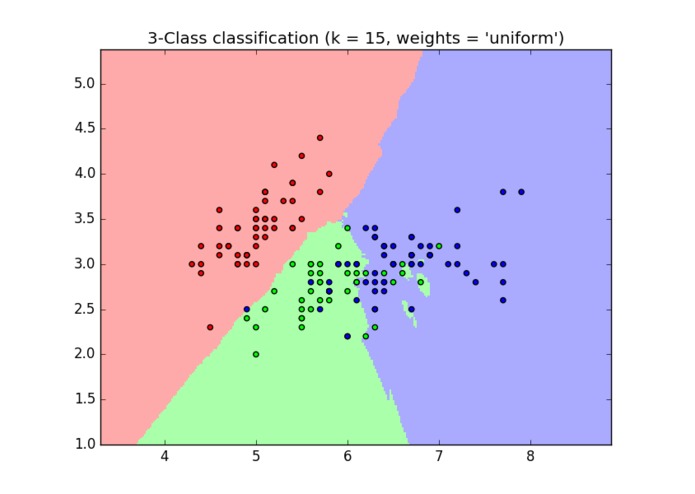
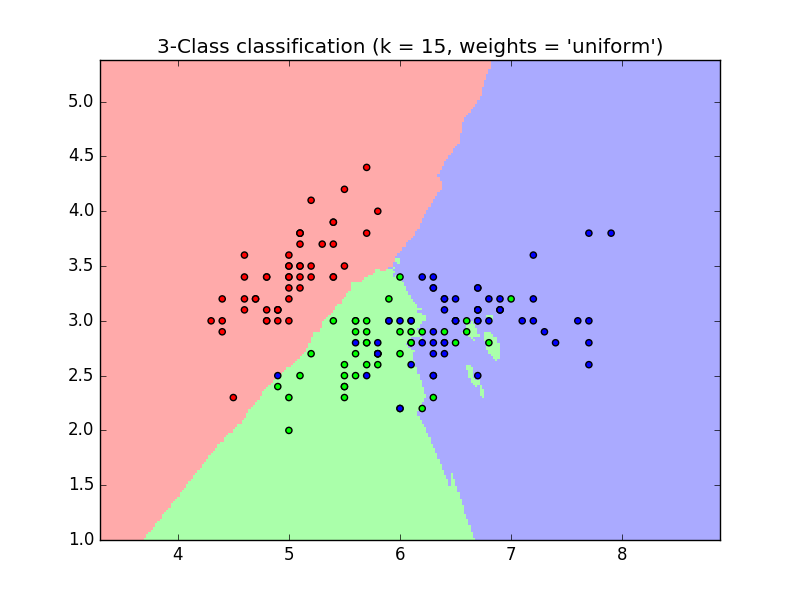
Example of KNN with Uniform Weights
-
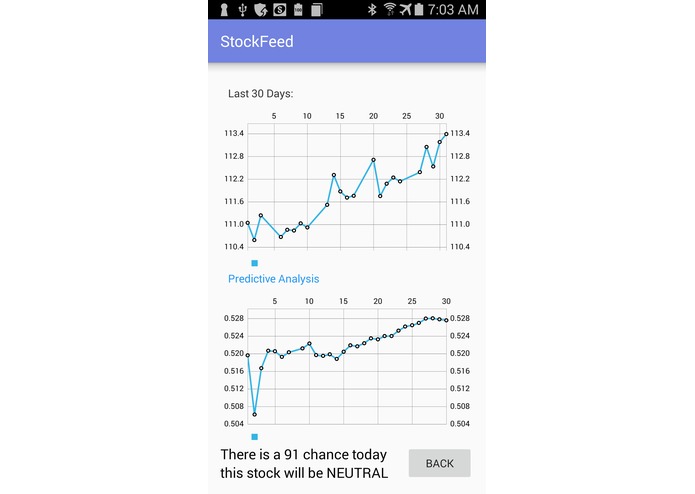
Disney Profile
Inspiration
The stock market is famously impossible to predict. We gave it a try.
What it does
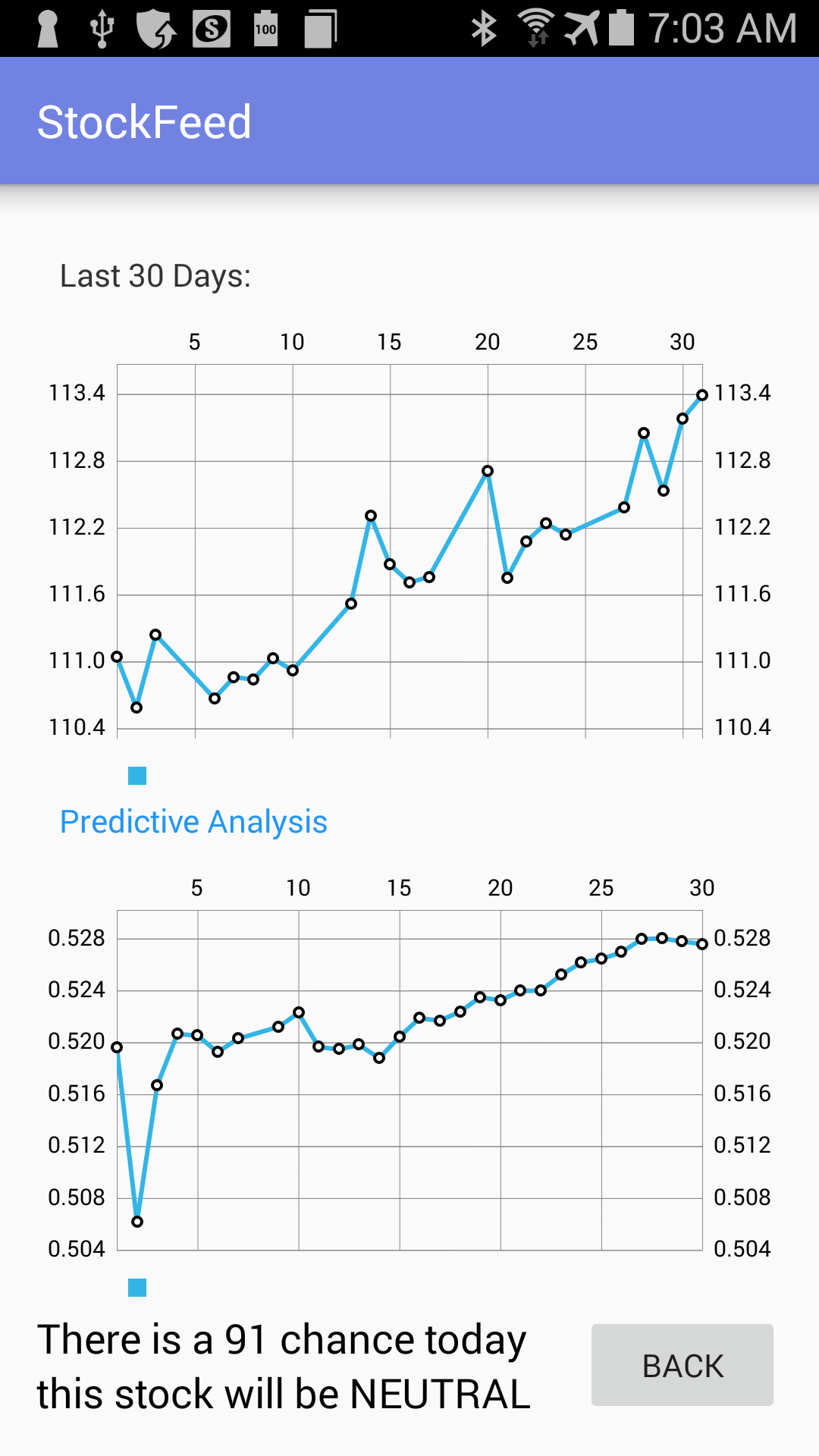
StockFeed works by combining fundamental and technical analysis. Massive quantities data are scraped from various news sources and Twitter, and sentiment analysis is used to gauge public opinion of the company. On the quantitative side, we built a machine learning model that predicts movement based on its volume and price. For ease of demonstration, the results have been wrapped in a mobile application.
How we built it
To keep the data manageable, we focused on 10 companies selected from the Dow Jones 30: Apple (AAPL), Disney (DIS), IBM (IBM), Microsoft (MSFT), Walmart (WMA), Nike (NKE), Verizon (VZ), Visa (V), McDonalds (MCD), and Intel (INTC).
We used the Nytimes and Bing's news search API to find online articles, and parsed the relevant text from a pool of relevant articles published within the last month. The sentiment of the sentences was then found through hierarchical classification using the Natural Language Toolkit (NTLK).
Twitter tweets were found by keyword using GetOldTweets-python, a Twitter API that bypasses the one week limit on Twitter's official API, which was then also classified using the NTLK.
Stock data was pulled through HTTP Get requests through the Stockvider API. Daily data over the past three years was saved and at each datapoint we determined whether the stock went up, down, or sideways at each datapoint. We used scikit learn to perform the machine learning KNN algorithm with close and volume as attributes, and the stock's eventual move as the label. One model was created for each company, with 70% of the initial data used to train the model and the other 30% used for verification.
We showcased the final project using an Android appliction, with the data preloaded into a Firebase database, and displayed side-by-side graphs to compare our compiled data with real time stock data.
Challenges we ran into
US newspapers with public search apis are not very common, which is why the Bing-search API was a huge boon. In order to gather data, we used GET and POST requests extensively with various search and information APIs, often to the point where we were throttled and had to find another way to successfully obtain the desired data.
The machine learning aspect was also a struggle, as none of us had any prior experience in the field.
What's next for StockFeed
A web or desktop application would be much better suited to display the large amounts of data and calculations made. If given more time, we would have also aggregated text data from more sources than just Twitter and the news, as well as expanded past the 10 companies from the Dow. We also plan to try applying machine learning to the sentiment as well as the stock, instead of just heuristics.



Log in or sign up for Devpost to join the conversation.