Inspiration
We started off by thinking, "What is something someone needs today?". In light of the stock market not doing so well, and the amount of false information being spread over the Internet these days, we figured it was time to get things right by understanding the stock market. We know that no human could analyze a company without bias of the history of the company and its potential stereotypes, but nothing can beat using an NLP to understand the current situation of a company. Thinking about the capabilities of the Cohere NLP and what we know and want from the stock market led us to a solution: Stocker.
What it does
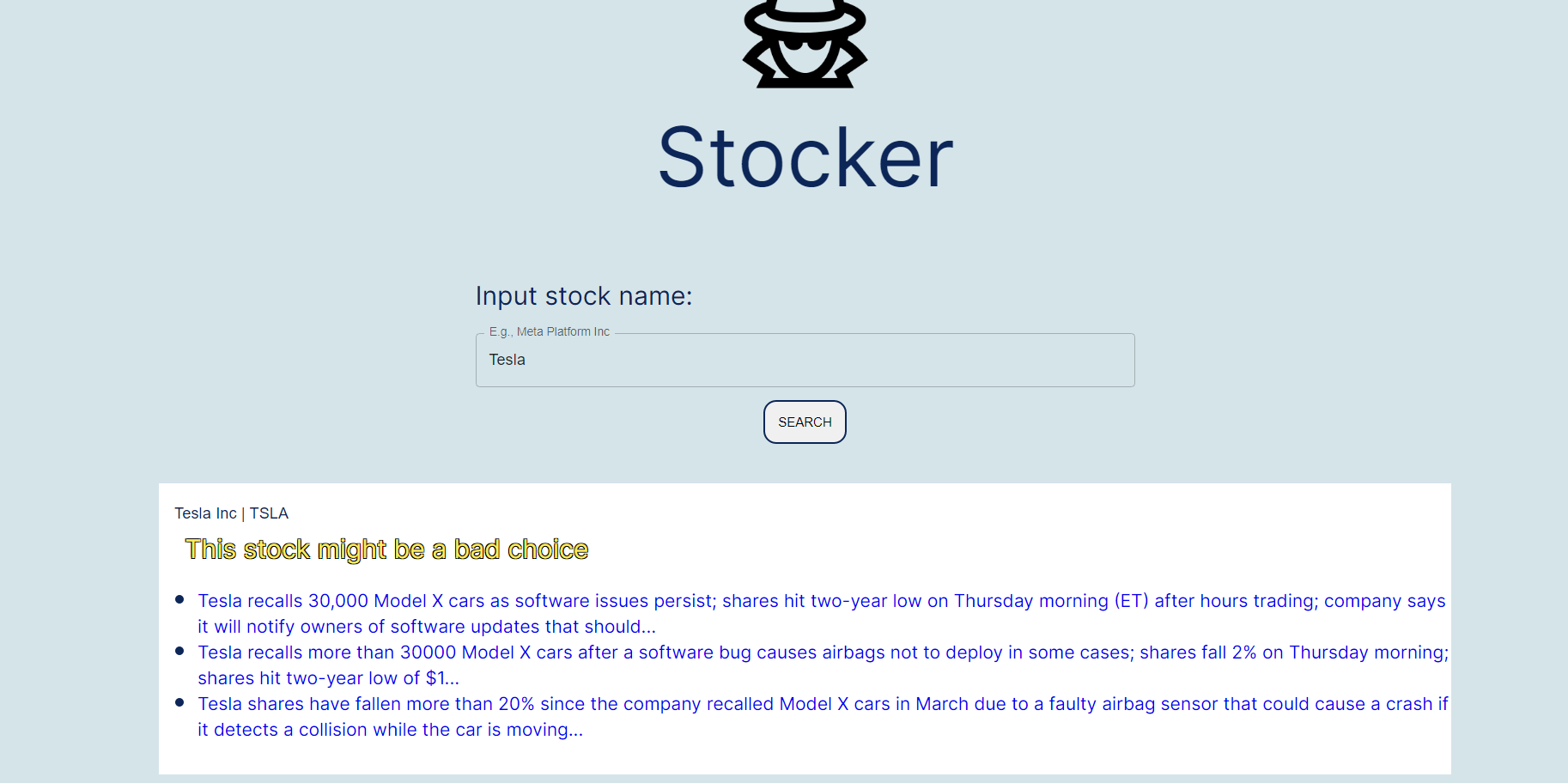
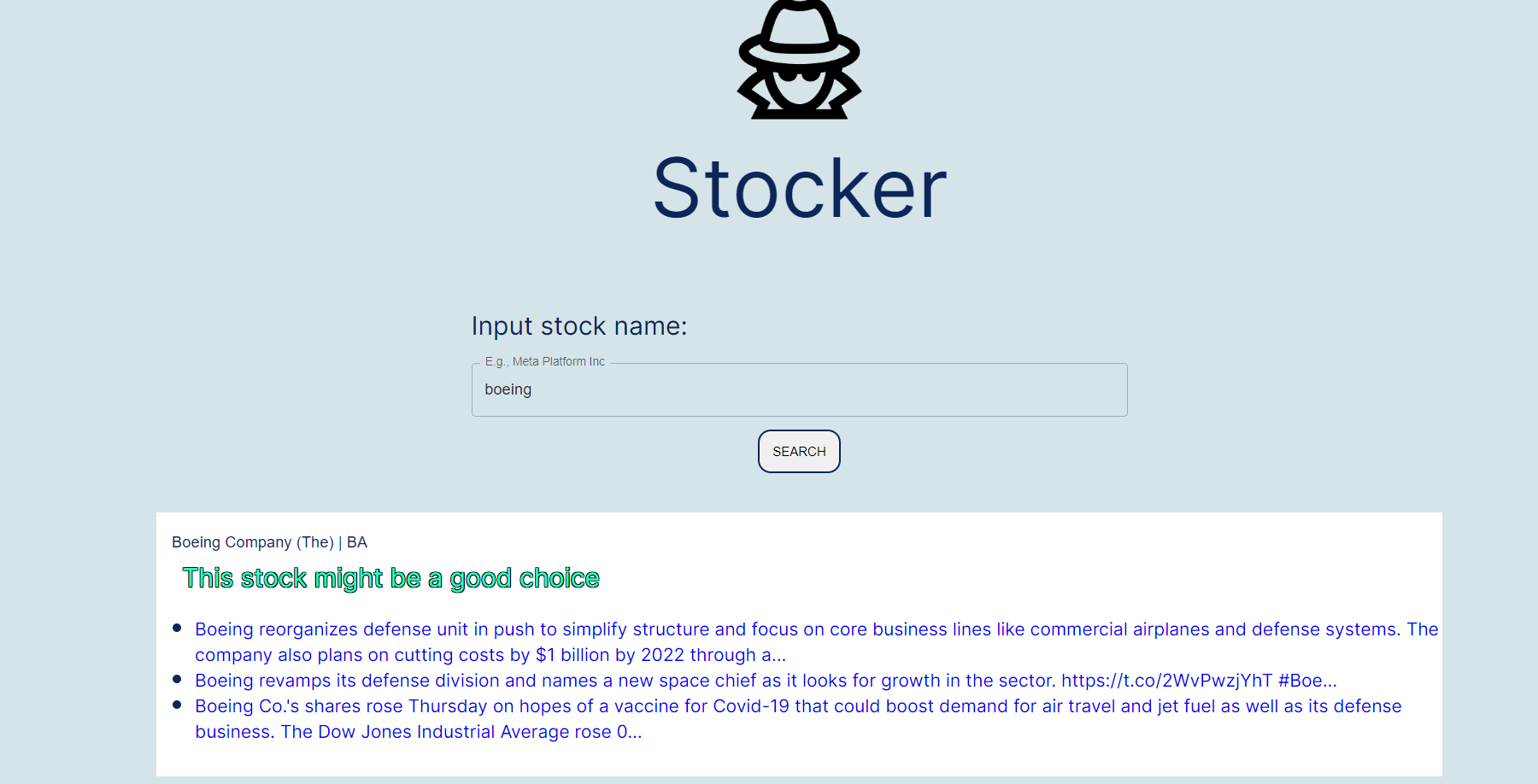
The main application allows you to search up words that make up different stocks. Then, for each company which matches the inputted string, we run through the backend, which grabs the inputted company and searches through the recent news of the company via a web scrapper on Google News. Then, we collect all of the headings and evaluate the status of the company according to a rating system. Finally, we summarize all the data by using Generate on all of the text that was read through and outputs it.
How we built it
The stocks corresponding to the search were grabbed via the NASDAQ API. Then, once the promise is fulfilled, the React page can update the list with ratings already prepended on there. The backend that is communicated runs through Google Cloud, and the backend was built in Python along with a Flask server. This backend communicates directly with the Cohere API, specifically on the Generate and Classify functionalities. Classify is used to evaluate company status from the headings, which is coupled with the Generate to get the text summary of all the headings. Then, the best ones are selected and then displayed with links to the specific articles for people to verify the truthfulness of the information. We trained the Classify with several tests in order to ensure the API understood what we were asking of it, rather than being too extreme or imprecise.
Challenges we ran into
Coming up with a plan of how to bring everything together was difficult -- we knew that we wanted to get data to pass in to a Classify model, but how the scraping would work and being table to communicate that data took time to formulate a plan in order to execute. The entire backend was a little challenging for the team members, as it was the first time they worked with Flask on the backend. This resulted in some troubles with getting things set up, but more significantly, the process of deploying the backend involved lots of research and testing, as nobody on our team knew how our backend could specifically be deployed.
On the front-end side, there were some hiccups with getting the data to show for all objects being outputted (i.e., how mapping and conditional rendering would work in React was a learning curve). There were also some bugs with small technical details as well, but those were eventually figured out.
Finally, bringing together the back-end and front-end and troubleshooting all the small errors was a bit challenging, given the amount of time that was remaining. Overall though, most errors were solved in appropriate amounts of time.
Accomplishments that we're proud of
Finally figuring out the deployment of the backend was one of the highlights for sure, as it took some time with researching and experimenting. Another big one was getting the front-end designed from the Figma prototype we made and combining it with the functional, but very barebones infrastructure of our app that we made as a POC. Being able to have the front-end design be very smooth and work with the object arrays as a whole rather than individual ones made the code a lot more standardized and consolidated in the end as well, which was nice to see.
What we learned
We learned that it is important to do some more research on how standard templates on writing code in order to be deployed easily is very useful. Some of us also got experience in Flask while others fine-tuned their React skills, which was great to see as the proficiency became useful towards the point where the back-end, front-end, and REST API were coming together (sudden edits were very easy and smooth to make).
What's next for Stocker
Stocker can have some more categories and get smarter for sure. For example, it can actually try to interpret the current trend of where the stock has been headed recently, and also maybe other sources of data other than the news. Stocker relies heavily on the training model and the severity of article names, but in the future it could get smarter with more sources such as these listed.









Log in or sign up for Devpost to join the conversation.