Stigmergy — Project Description
An autonomous DFIR platform where math decides, the ledger records, and the LLM only explains — so a hallucinating agent can never cause a wrong containment decision or forge an evidence trail.
Inspiration
AI-driven attacks now outrun human responders. MIT measured a 47× speed-up in 2024; Anthropic's GTG-1002 report (Nov 2025) documented an intrusion run at 80–90% AI autonomy. The Find Evil! brief frames the core tension exactly right: connecting an LLM agent to 200+ SIFT tools makes it fast, but "it hallucinates more than we'd like." A forensic platform that hallucinates is worse than useless — it produces evidence a court, or an incident commander, cannot trust.
We didn't want to make the agent a little more careful. We wanted an architecture where the agent's hallucinations cannot reach the decision or the evidence record at all.
What it does
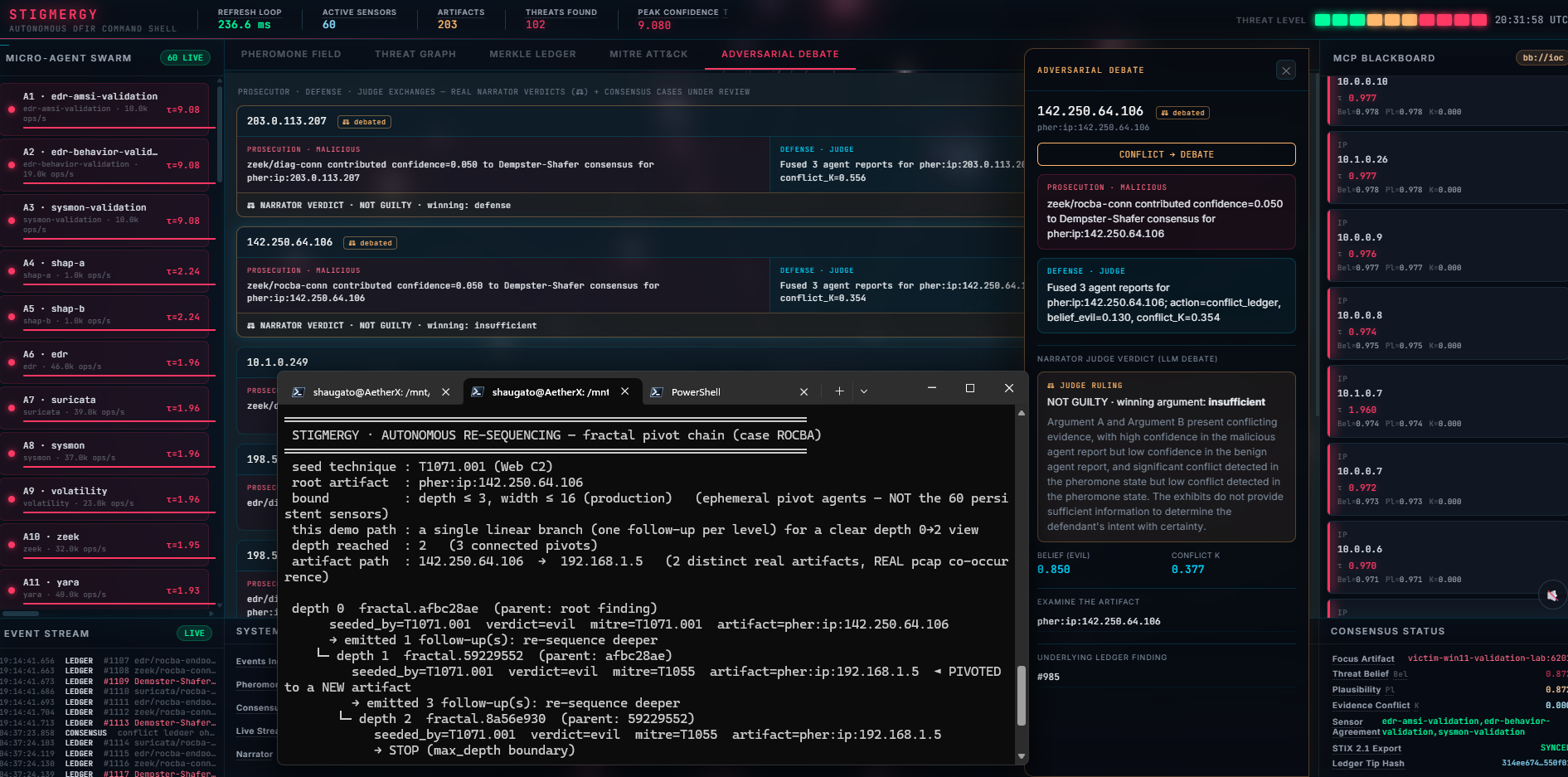
Stigmergy is a local, defensive autonomous SOC/DFIR platform built around a deterministic hot path and an out-of-band reasoning plane:
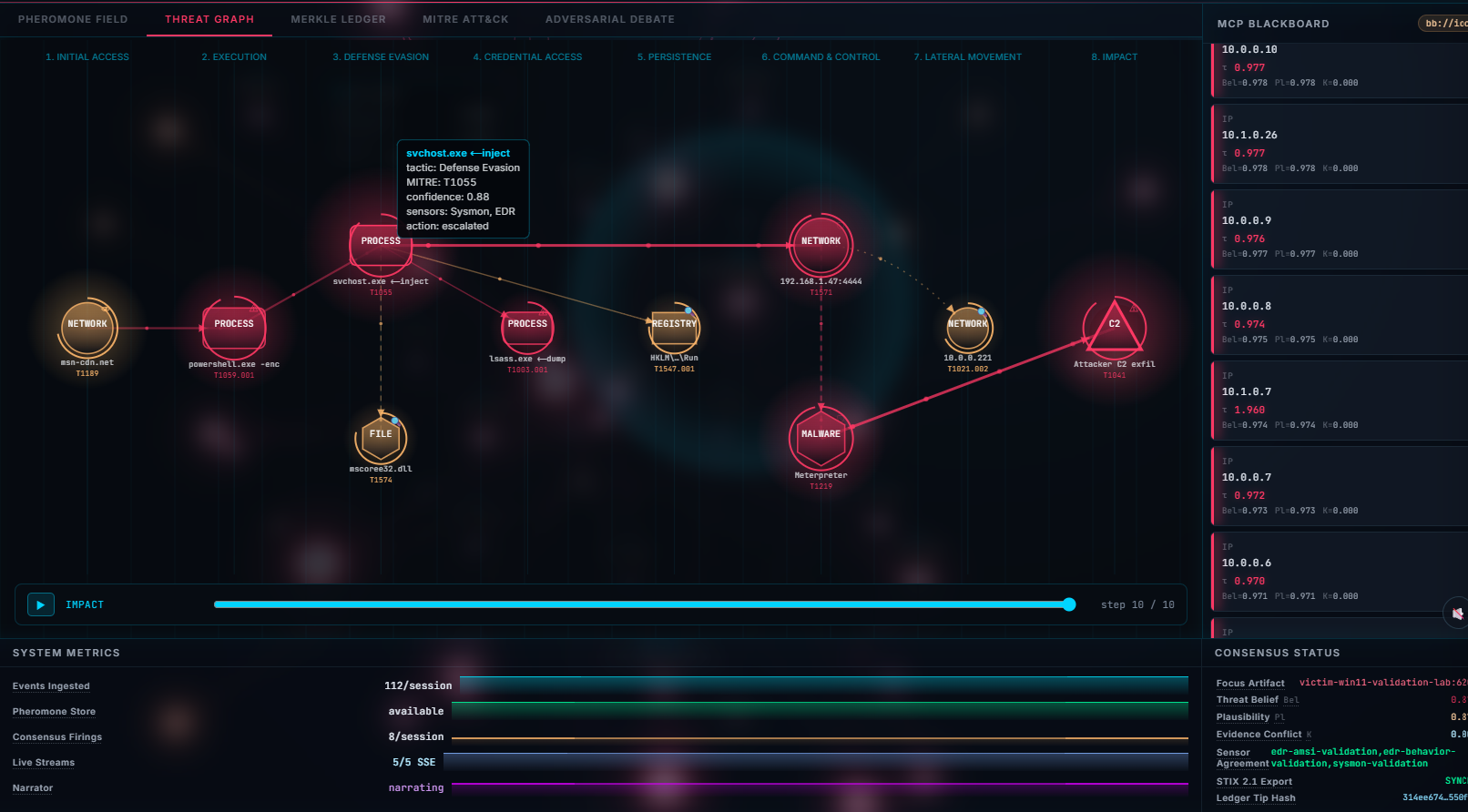
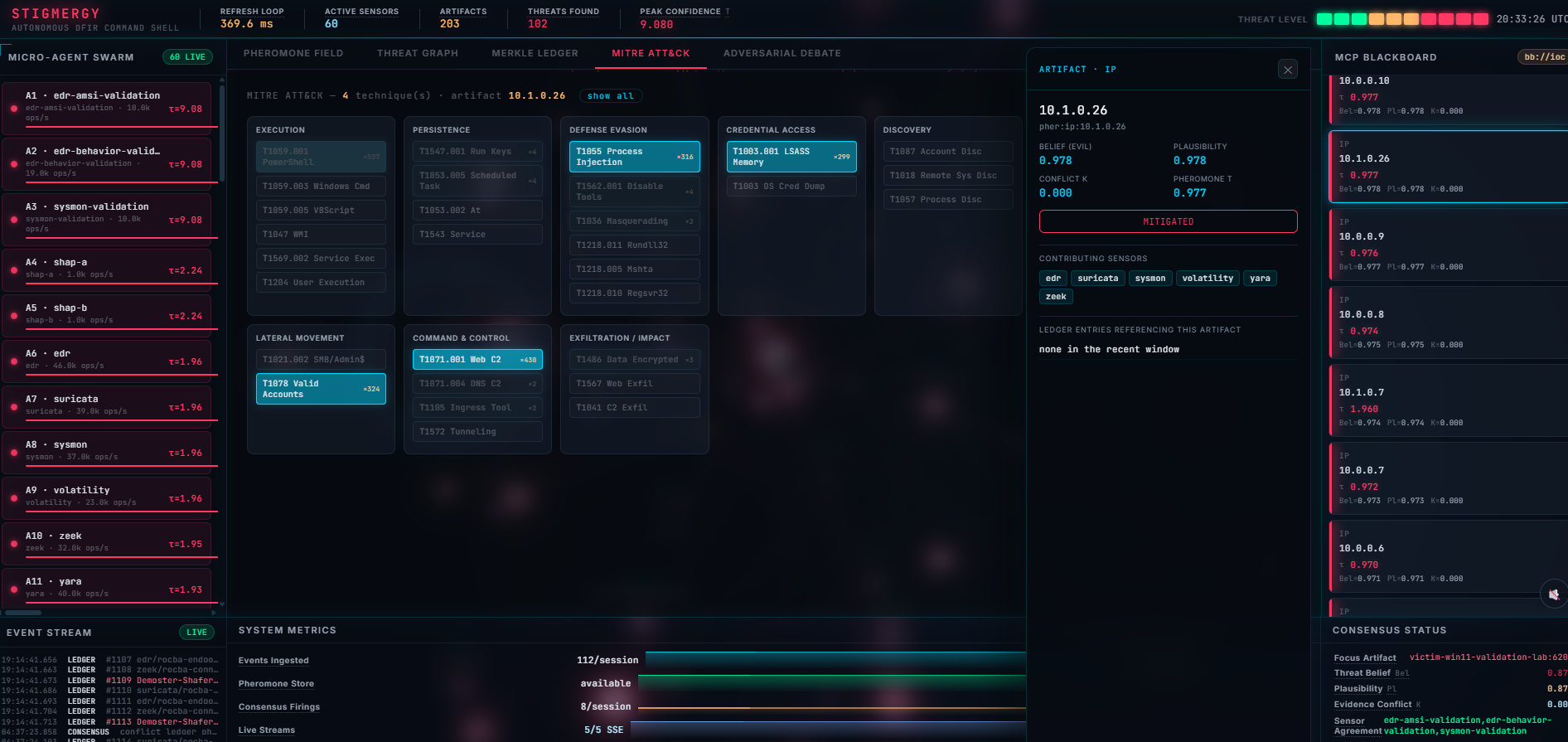
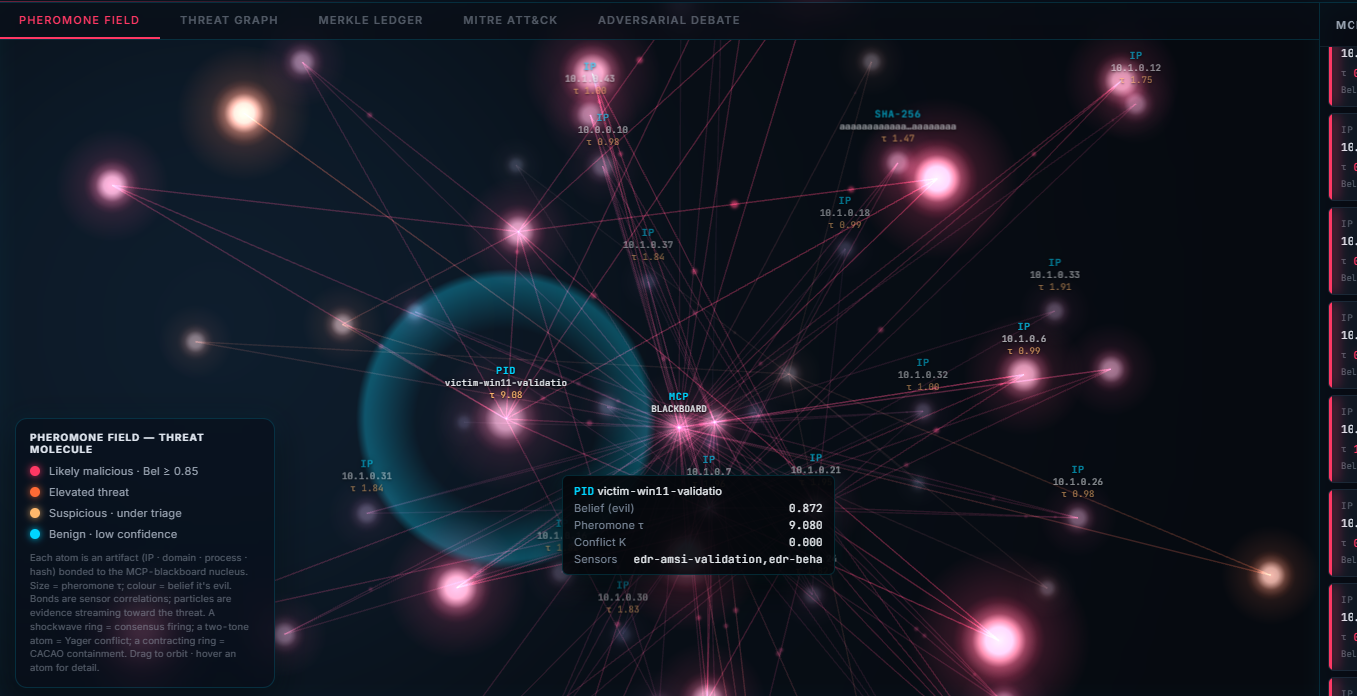
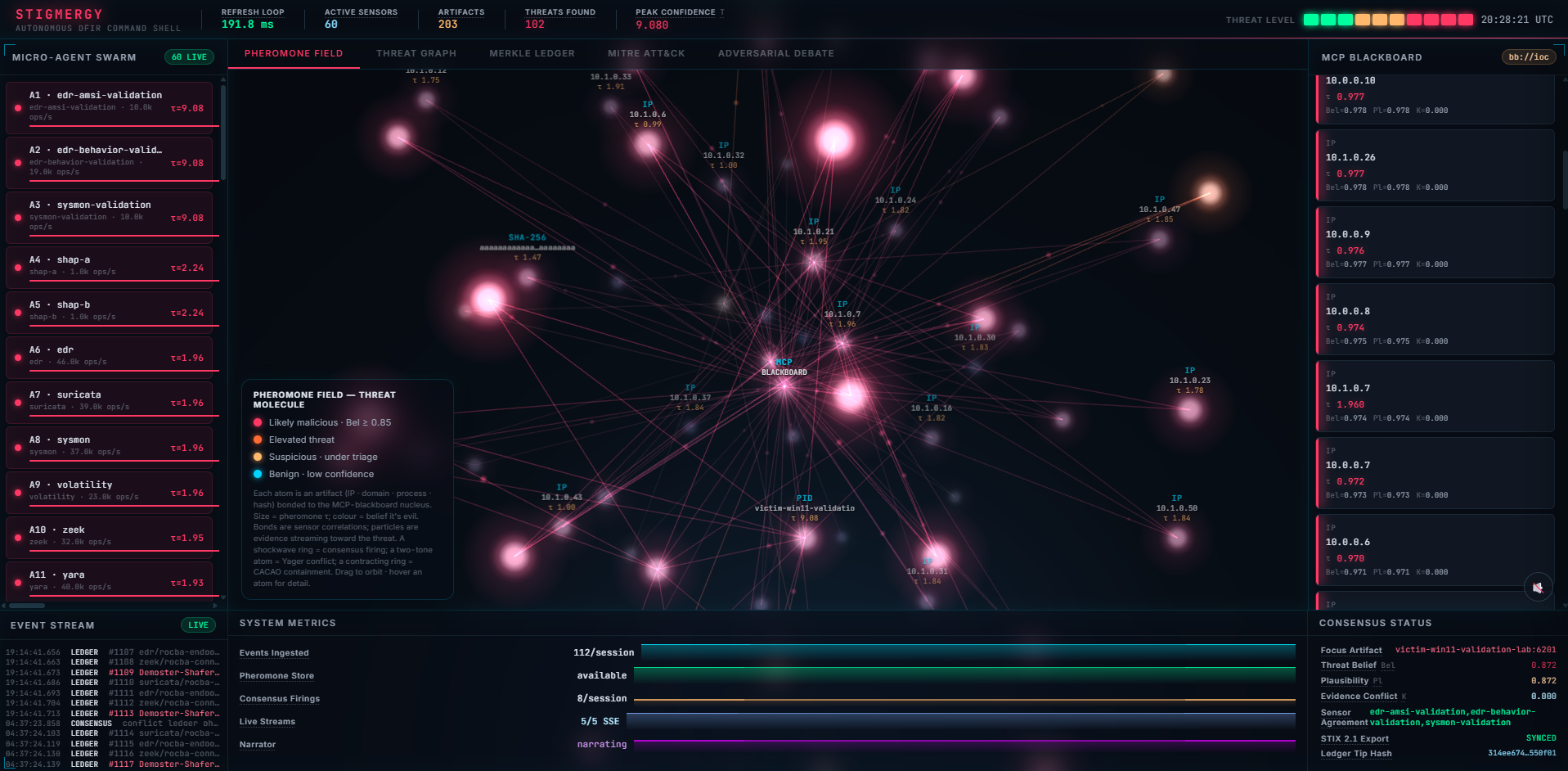
- Sensors (Volatility, YARA, Zeek, Sleuth Kit, tshark, Plaso, bulk_extractor, TAXII CTI) deposit Dempster–Shafer evidence onto a stigmergic pheromone field in Valkey.
- A deterministic fusion engine computes Belief / Plausibility / conflict_K and a threshold evaluator chooses observe / mitigate / conflict / escalate — with no LLM in the loop.
- Every decision is appended to a forensic ledger: Pydantic-v2 schema, UUIDv7 IDs, BLAKE3 hash chain, Ed25519 signatures, Merkle-batched and anchored to Sigstore Rekor.
- Only then, off the hot path, do LLM fractal pivot agents (depth ≤3,
width ≤16) re-sequence the investigation: a finding spawns an ephemeral,
depth-bounded pivot that chooses the next related artifact to examine from the
real evidence — in the carved ROCBA run it pivoted from the C2 IP
142.250.64.106to192.168.1.5, the host that had contacted it (a real pcap co-occurrence), withparent_id/seed_technique/depthlineage signed to the ledger (see execution-logs/pivot_chain.md). A prosecutor/defense/judge debate narrator (Zheng-2023 position-swap bias mitigation) then rules on contested findings. The math already decided whether an artifact is evil; the agent decides where to look next based on what it finds. - Response is CACAO 2.0 safe-mode playbooks; interop is STIX 2.1 / OCSF 2004 / Diamond Model; the whole thing is visible in a six-pane live dashboard.
The agent reaches all of this through a Custom MCP Server (the brief's
Approach #2): 62 typed, schema-validated tools with reference-resolved exhibit
IDs. There is no execute_shell_cmd — the agent physically cannot run an
arbitrary command.
How we built it
- Transport / state: Valkey (pheromone field + Lua atomic deposits), NATS JetStream (durable event streams), ZeroMQ (hot-path IPC), Bytewax (event-time windowed ingest with watermarks).
- Decision core: a from-scratch Dempster–Shafer combinator with Yager conflict handling, Platt/Isotonic calibration, and Shapley agent attribution.
- Ledger: SQLite WAL + BLAKE3 + Ed25519, two-pass signing, hourly tamper verification via a systemd timer, Merkle anchoring to Rekor.
- Inference: llama-cpp-python serving Llama-3.2-3B locally, with
outlines/xgrammarFSM-constrained JSON so agent output is schema-valid by construction. - MCP substrate: fastmcp 2.x exposing
bb://resources and the typed tool catalog; high-frequency events ride a shadow pub/sub channel so the blackboard only sees threshold crossings. - Ops: ~12 systemd units under a
findevil.target, OpenTelemetry + Prometheus metrics, structured logs.
The real-data run
We ran the platform against the official SANS Find Evil! ROCBA memory image
(Standard Forensic Case). The downloaded image had a corrupt block that defeated
Volatility's kernel detection — so we pivoted to bulk_extractor stream-carving
(corruption-tolerant) to recover real network indicators (IPs, domains,
URLs, emails) and drove those through the live fusion → ledger pipeline. The
new findings are signed and chain-verified. Full trace:
execution-logs/, provenance:
dataset.md, honesty:
accuracy-report.md.
Challenges we ran into
- Pascal GPU dead end. Our P620 is compute-capability 6.1; CUDA 13 dropped Pascal, and a from-source sm_61 build of llama.cpp worked but ran 2–3× slower than CPU for our short completions. We documented it and kept CPU inference — the hot path has no LLM, so the SLA is unaffected.
- Corrupt official image. Covered above — turned a blocker into a documented limitation by switching to a carving tool that doesn't need image structure.
- Keeping the LLM honest. The hard part wasn't calling the model; it was designing so that nothing the model says can change a decision or the record. That drove the architectural-guardrail design (see architecture-diagram.md).
Accomplishments we're proud of
- A 936-entry cryptographically clean ledger (
findevil verify→ok=true), grown with real-image-derived findings during this sprint. - Hot-path p50 0.567 ms / p99 1.071 ms — far under the 6 ms / 20 ms target.
- 87 passing tests, 33 detection scenarios, all standards proven live (STIX/OCSF/CACAO/Rekor).
- A guardrail story we can defend: architectural, not prompt-based.
What we learned
Evidence integrity is an architecture property, not a prompt property. Once we stopped asking the model to behave and started building a system where misbehavior is structurally inert, every other decision got simpler.
What's next
- Structured Volatility analysis on a clean image (process trees, malfind injection) to complement the carving run.
- Multi-host correlation across the APT disk-image set.
- Live TAXII feeds wired to a real CTI provider as standing pheromone priors.
Stigmergy is local, defensive infrastructure. It contains no offensive tooling and was validated only against synthetic telemetry and legitimate sample forensic images.

Log in or sign up for Devpost to join the conversation.