-
-
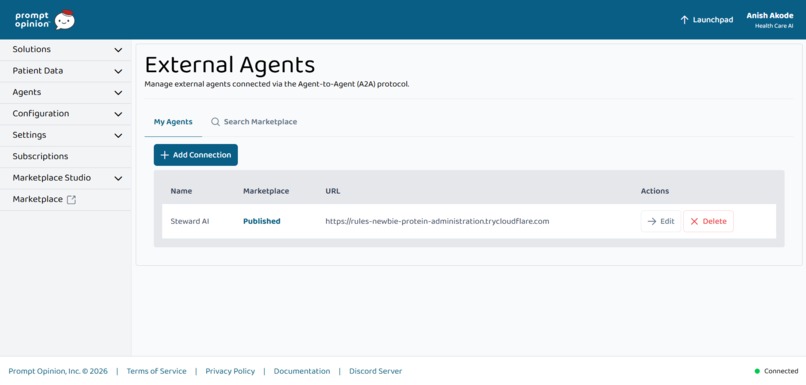
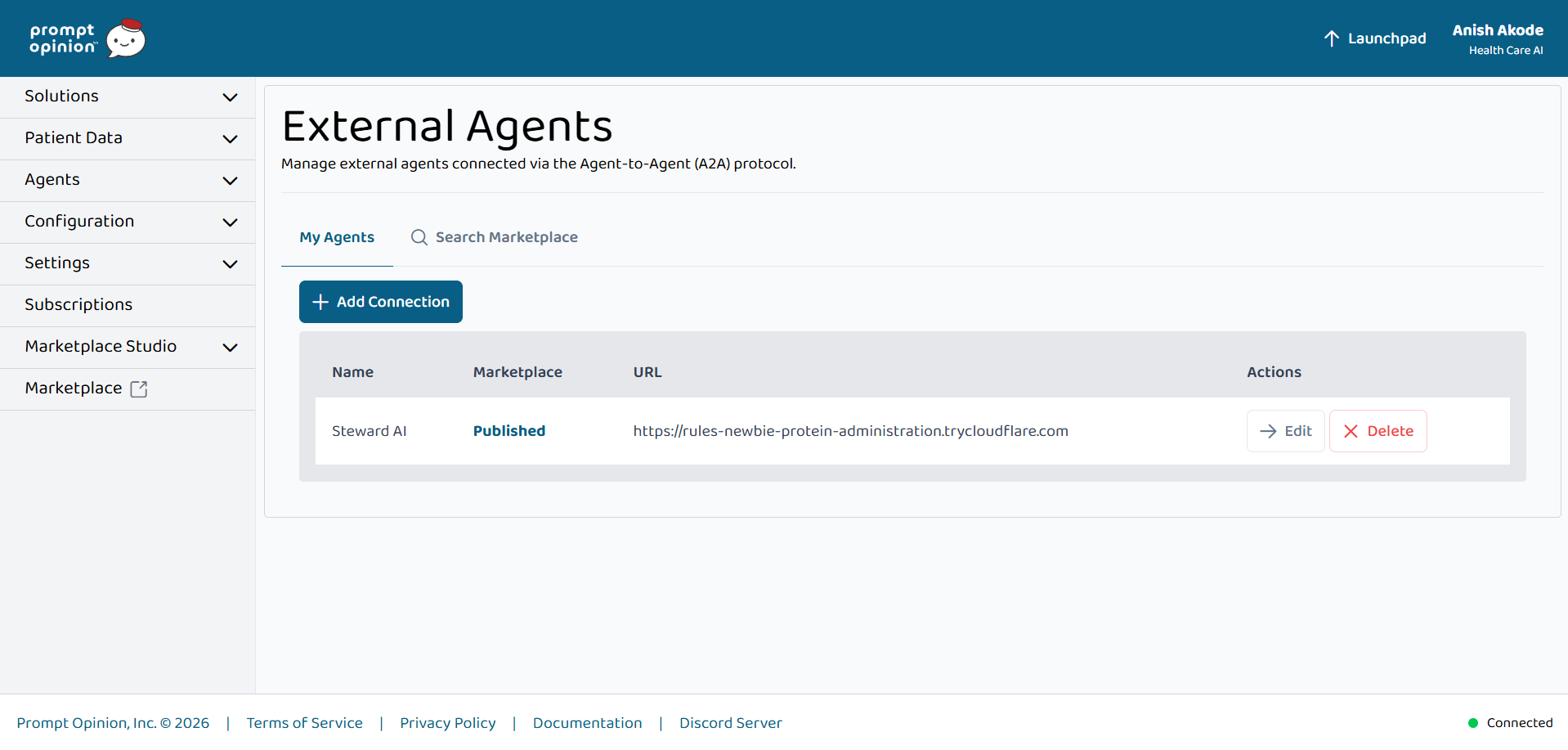
Steward AI published on Prompt Opinion via A2A—external agent wired for real stewardship workflows in the clinician workspace
-
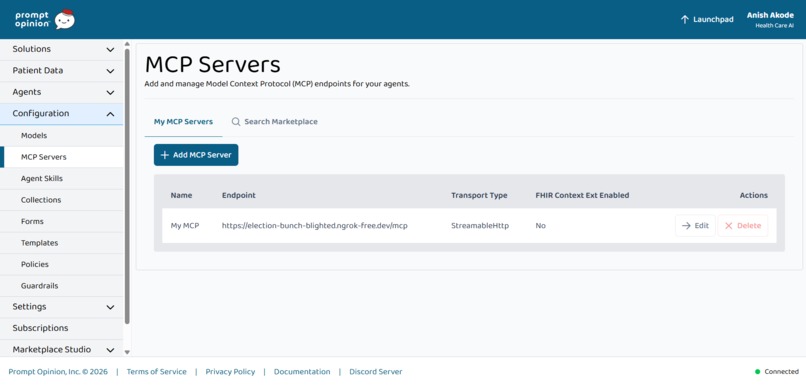
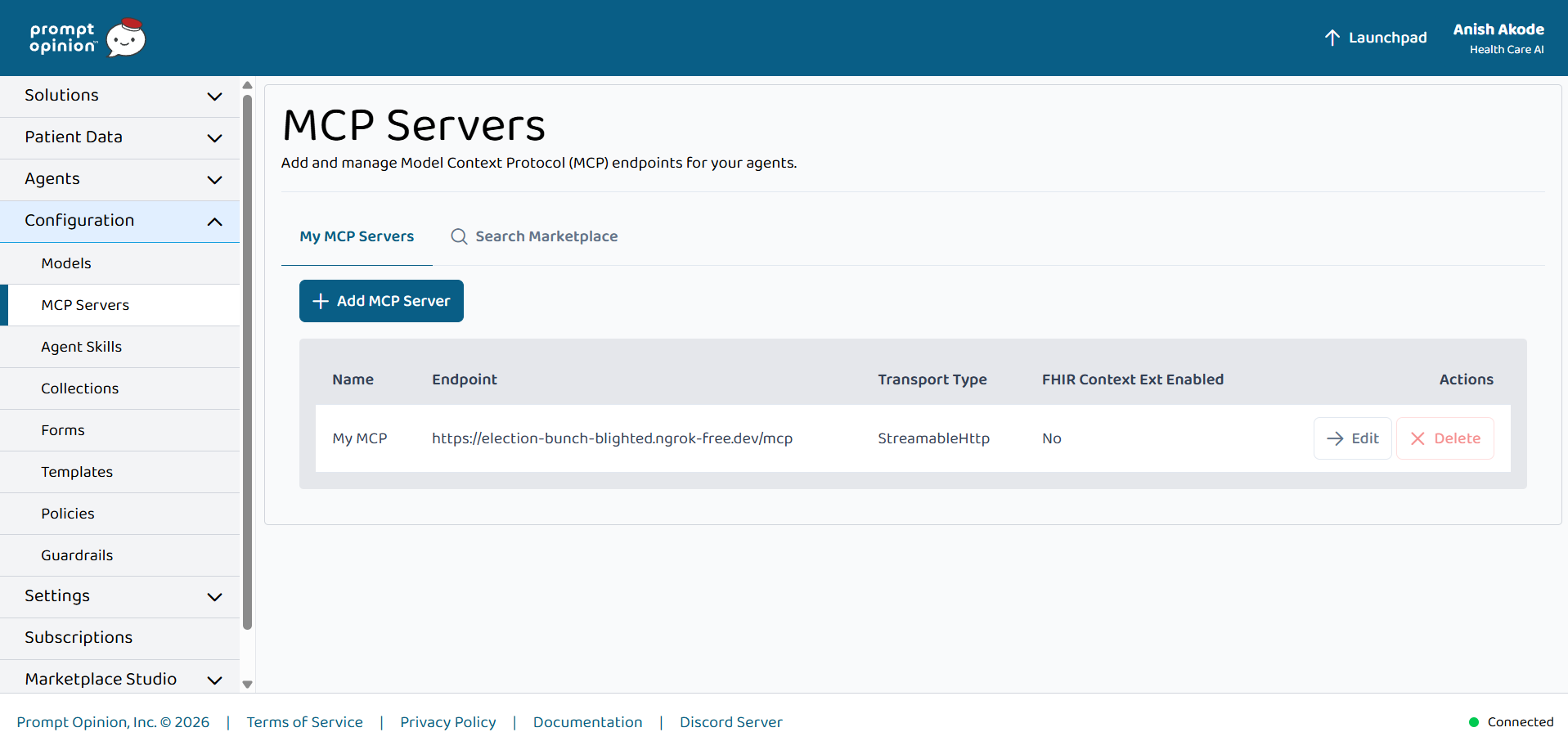
MCP server (streamable HTTP) registered in Prompt Opinion—stewardship tools exposed to agents for FHIR-backed recommendations.
-
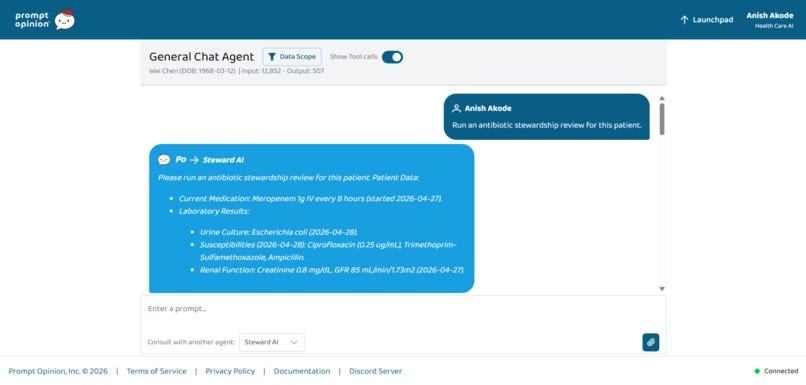
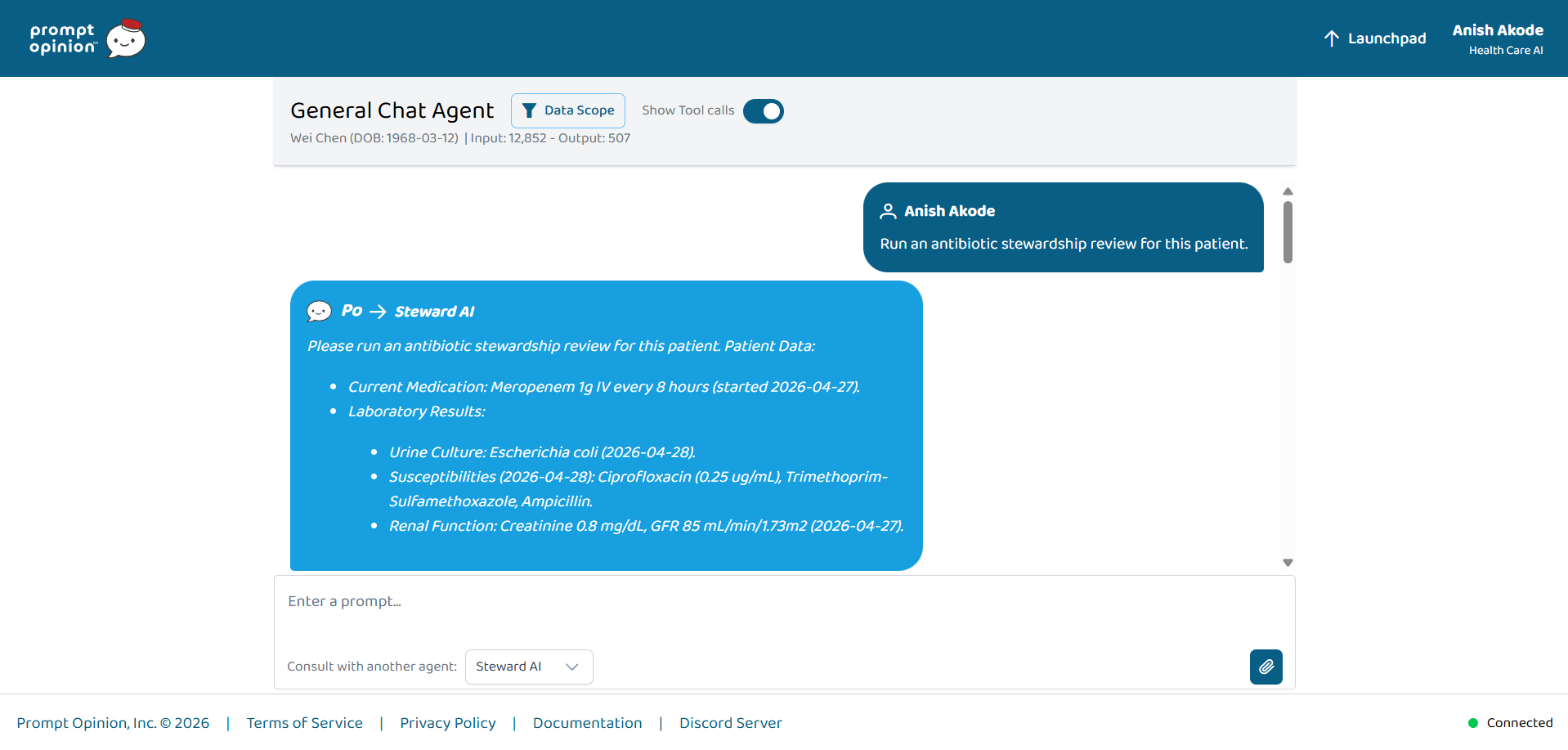
“Run stewardship review” pulls meds, culture, susceptibilities, renal labs—tool visibility shows how StewardAI builds the answer.
-
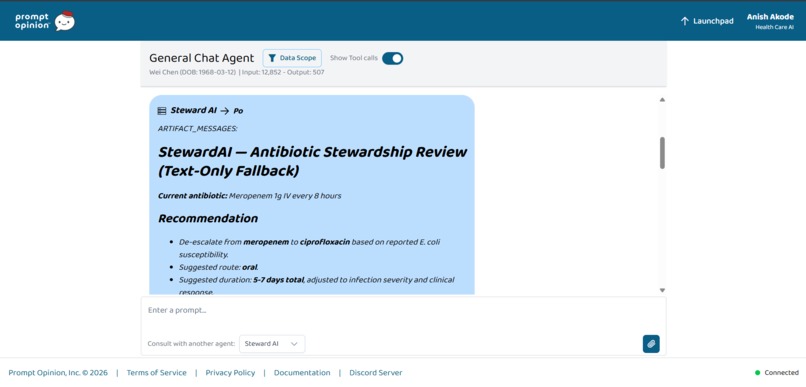
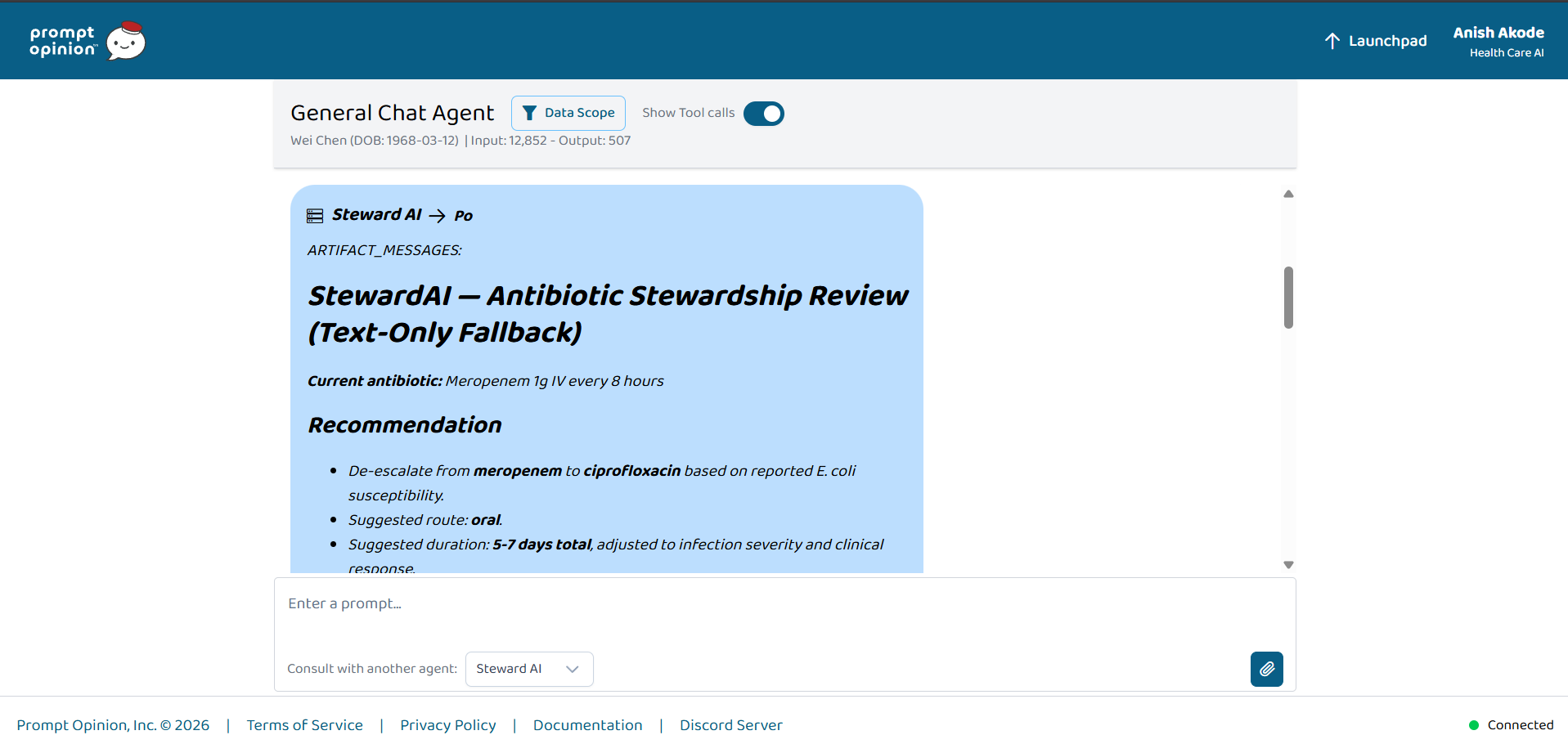
StewardAI antibiotic review in Prompt Opinion: meropenem → oral ciprofloxacin with duration—grounded in FHIR patient context.
Inspiration
Hospital antibiotic decisions rarely fail because nobody “knows the guidelines”—they fail because the full picture is fragmented: active meds, pending vs final cultures, susceptibilities, allergies, renal function, and the clinical indication rarely arrive in one place at one time. Generative AI can help synthesize, but only if the assistant can reliably access structured clinical context instead of guessing from a chat transcript alone.
This hackathon’s framing—MCP + A2A + FHIR—matched how I wanted to build: reusable tools (MCP), an invocable agent (A2A), and an interoperability backbone (FHIR) with SHARP-style session context on Prompt Opinion.
What it does
StewardAI supports antibiotic stewardship-style reviews grounded in FHIR data accessed through an MCP server, orchestrated via an A2A-compatible agent for Prompt Opinion workspaces.
MCP capabilities (examples)
- Pull active antibiotics from medication resources
- Retrieve microbiology / diagnostic reports and extract culture + susceptibility signal
- Check allergies, summarize renal labs, and infer broad infection context from conditions
- Generate a structured stewardship recommendation from consolidated patient context
- Optionally draft a FHIR Task-style artifact for workflow-oriented demos
In Prompt Opinion, the goal is simple for the user: attach patient context and ask for a stewardship review—while the system proves standards-based plumbing behind the scenes.
How I built it
FHIR-facing MCP server (FastMCP)
Tools acceptfhir_url,patient_id, and optionalfhir_token, then query FHIR resources and normalize outputs into stable JSON shapes for downstream reasoning.Recommendation orchestration
I consolidate FHIR-derived context and use Gemini to produce structured stewardship-style outputs (rationale-forward, uncertainty-aware), rather than only returning raw lab rows.A2A HTTP agent
I implemented JSON-RPC-style handling compatible with Prompt Opinion’s strict response parsing, iterating until task completion payloads deserialized reliably (including a minimal “artifacts + status state” response shape).End-to-end demo path
I tested locally, then exposed endpoints through tunnels when needed so Prompt Opinion could reach my services during integration testing.Marketplace
I published the MCP listing so the toolset is discoverable and invocable beyond a one-off demo.
Challenges I ran into
- Real-world FHIR variance: Microbiology can be encoded across
DiagnosticReport+ referencedObservationresources; “pending culture” vs “final” changes the safe recommendation posture. - Strict client parsing on the platform: Small schema mismatches surfaced as opaque deserialization errors; debugging required treating Prompt Opinion as the contract authority and simplifying responses until they parsed cleanly.
- Demo operations: Coordinating multiple public endpoints and keeping URLs/configuration aligned taught me how fragile “works on my laptop” is compared to a hosted integration.
Accomplishments that I'm proud of
- A working loop in Prompt Opinion: patient context in → tools/agent invoked → actionable stewardship-style output out.
- A reusable MCP tool layer that isn’t locked to a single chat UI—other agents can adopt the same capabilities.
- Persistence through interoperability debugging until A2A responses were actually usable, not “almost right.”
- Publishing to the Prompt Opinion Marketplace so the work is real ecosystem participation, not only a private prototype.
What I learned
- Interoperability is the product: The hardest engineering was not prompting—it was correct plumbing + schema discipline across MCP, FHIR, and A2A hosts.
- Portability beats monoliths: MCP separates “capabilities” from “UI,” which is exactly what healthcare AI needs as teams swap models and workflows.
- Safety is explicit: Stewardship assistance must highlight uncertainty (e.g., pending cultures) and avoid overstating certainty—especially in demo settings.
What's next for StewardAI: MCP + A2A Antibiotic Stewardship
- Hardening: Automated tests around FHIR parsing edge cases; clearer failure modes when data is incomplete.
- Governance-ready packaging: Secrets management, stable hosting, audit logs, and explicit “demo vs clinical evaluation” modes.
- Deeper workflow hooks: Expand FHIR write-back patterns cautiously (where permitted), and richer pharmacist/clinician review UX in-product.
- Evaluation: Side-by-side review with infectious diseases / pharmacy stakeholders on curated scenarios—not just qualitative demos.

Log in or sign up for Devpost to join the conversation.