Inspiration
The world has now experienced a full year of virtual everything. A main component of this new digital experience is voice. We now use our computers to listen to lectures, business meetings, music, interviews, and our teammates in virtual hackathons.
This presents a serious challenge to those with difficulty hearing, or simply those who need help keeping up with the constant stream of information coming out of our headphones.
What it does
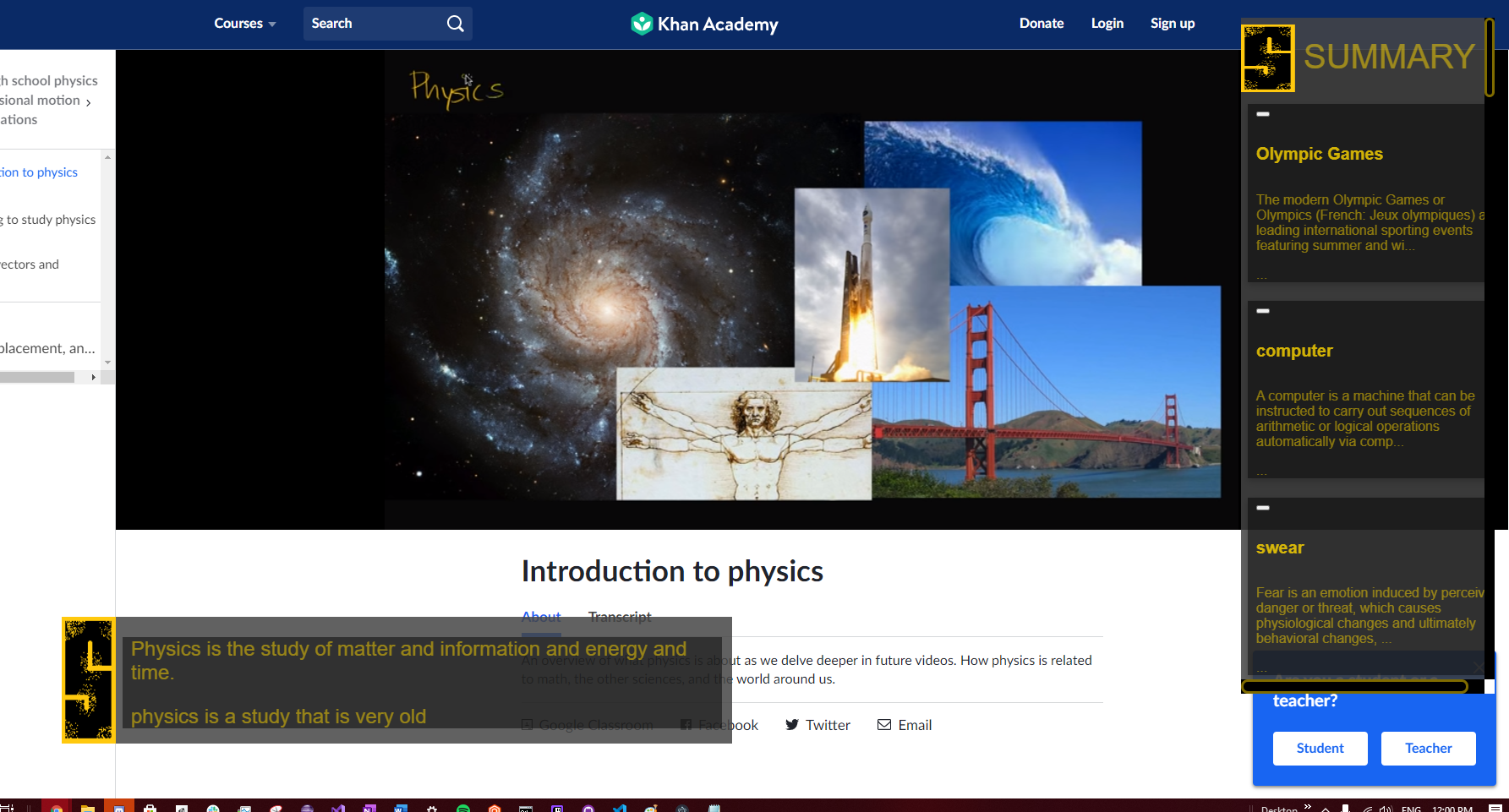
To help tackle this issue, we created Stenotes - an overlay application designed to run on the user's desktop. It captures audio output from everything on the computer, transcribes the detected speech into text, and displays it in the overlay as captions. It automatically saves the transcript as a file that the user can review later. Stenotes also features a Summary window which detects keywords from the audio and presents the user with small summaries about the topics mentioned in the audio. The cards can also be clicked, leading the user to a Wikipedia page about the topic.
How we built it
The front-end of Stenotes is built using Electron (Javascript, HTML, CSS) and uses a SocketIO Client to receive data from the back-end. The back-end is built using a Python Flask SocketIO server that periodically sends data to the front-end. The desktop audio is collected by configuring a SoundDevice Python library. The audio is then transcribed to text using a Vosk ML Model that runs speech recognition and outputs detected text as partial or complete sentences. The completes sentences are also stored in a buffer and passed to a BERT Keyword Identification ML Model to detect important words and topics from the text. Keywords are then passed to a Wikipedia API to scrape a summary from a Wikipedia page about the topic. All the metadata (partial sentences, complete sentences, and keywords + summaries) are threaded to run simultaneously and be passed through the socket upon availability.
Challenges we ran into
It was difficult to establish the communication between the Electron front-end and the Python back-end using SocketIO. It was also difficult to maintain multi-threading functionality while sending socket messages from the back-end. It was also difficult to find a suitable method of collecting desktop audio. We also had many setbacks where some technology could not be easily integrated (such as Javascript based MediaRecorders and certain speech-to-text frameworks) and had to be removed, costing time and requiring us to plan again.
Accomplishments that we're proud of
We are proud of the mistakes the ML model makes when transcribing text. We are proud of the mistakes the Wikipedia API makes when it returns the wrong web page. We are proud of being able to collect desktop audio and configure it to our uses. We are proud of being able to maintain front-end back-end communication using SocketIO. We are proud of being able to generate keywords and pass them to the front-end.
What we learned
We learned how to combine Javascript and Python tools more effectively. We learned to laugh at AI.
What's next for Stenotes
Improved UI/UX and better speech-to-text recognition


Log in or sign up for Devpost to join the conversation.