-
-
MCP server
-
A sample UI
-
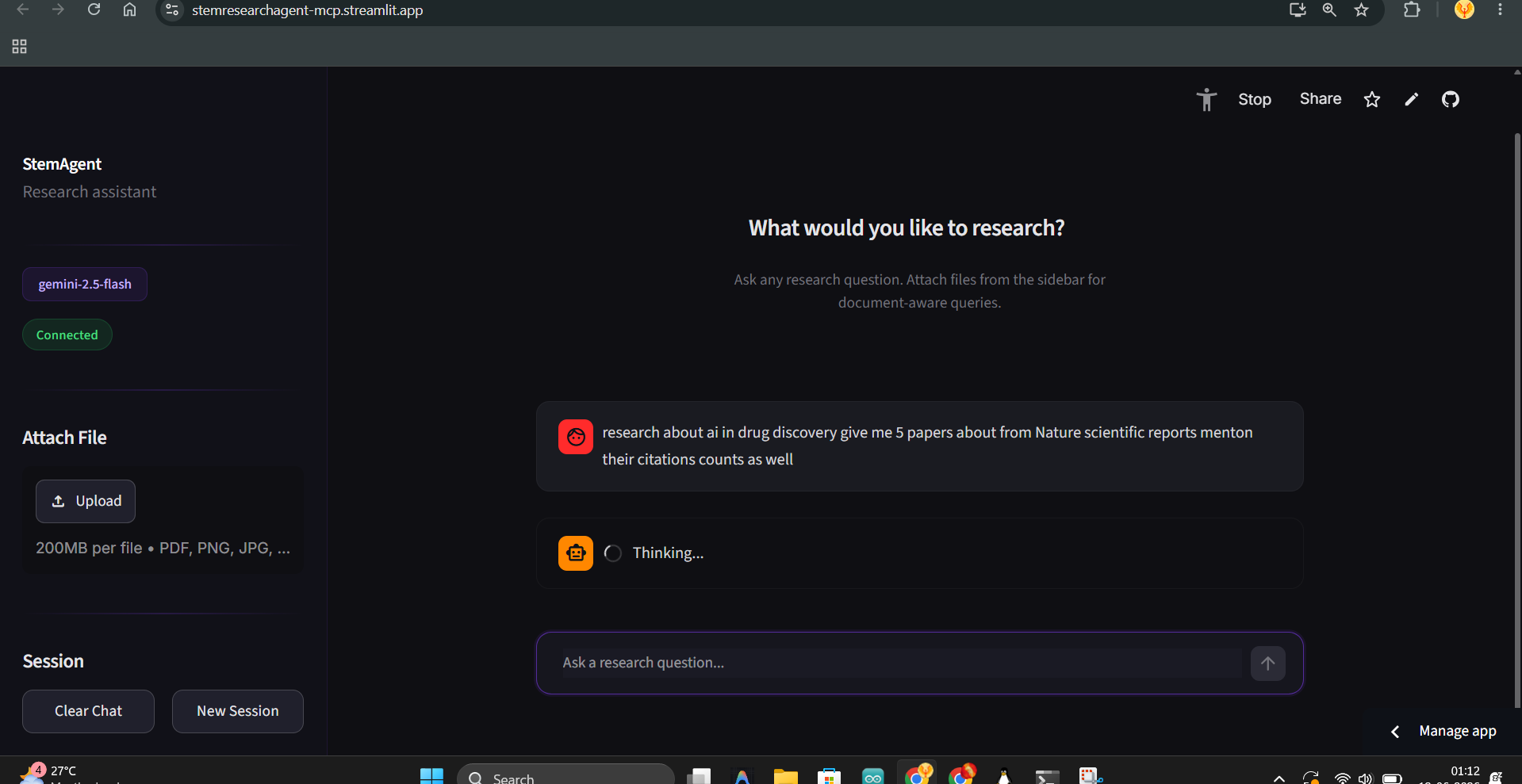
In action
-
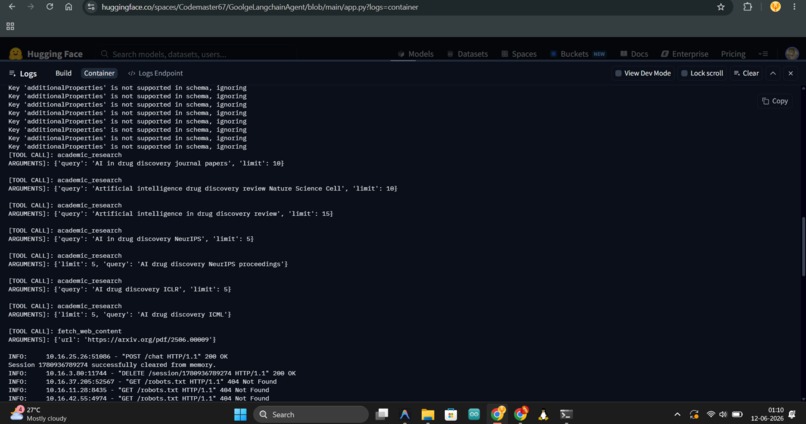
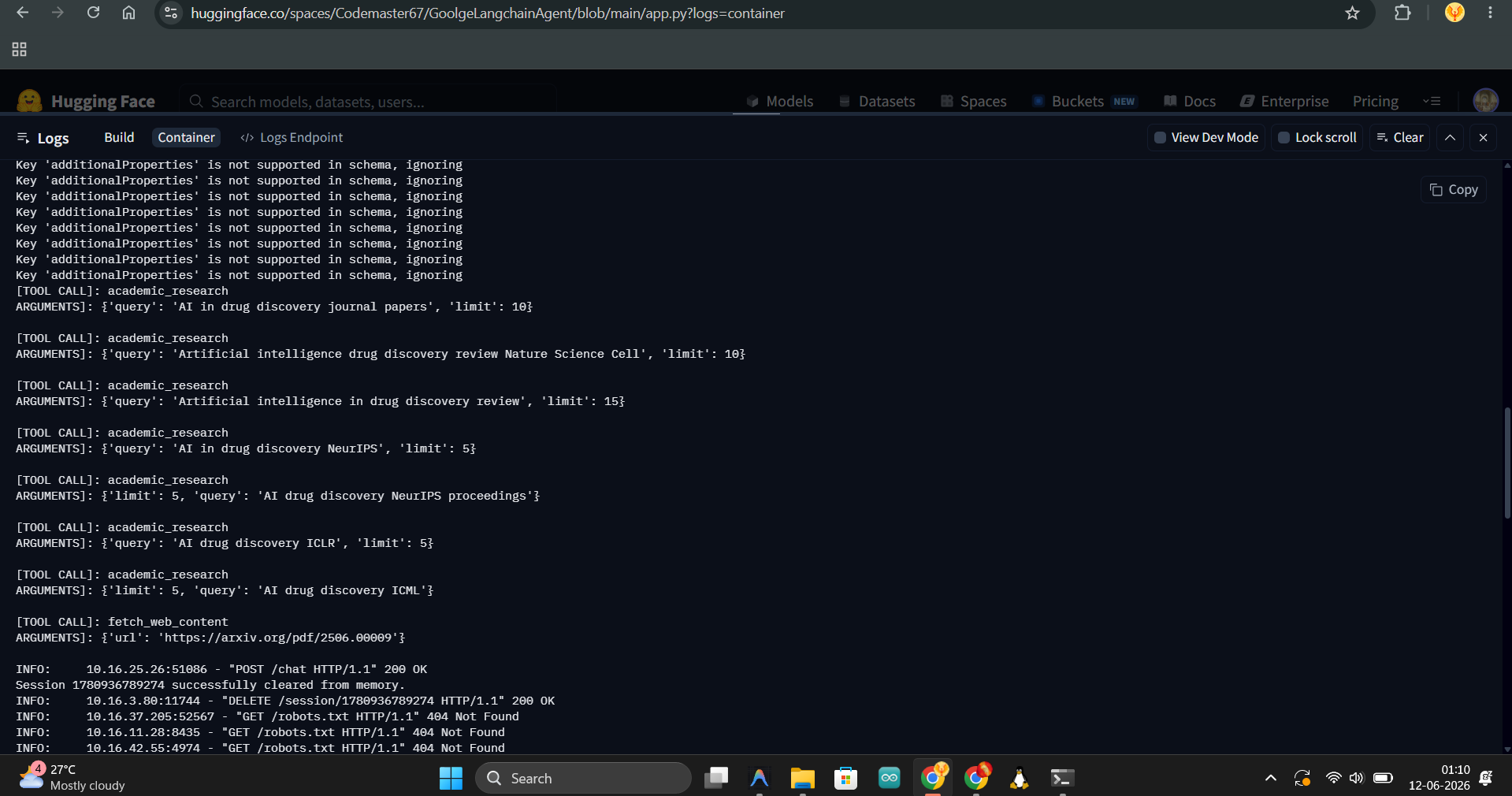
Logs for langchain api (you can see which tool is being called)
-
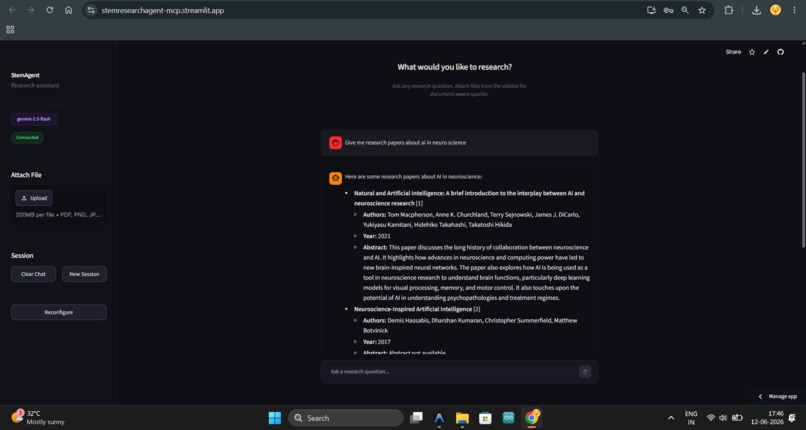
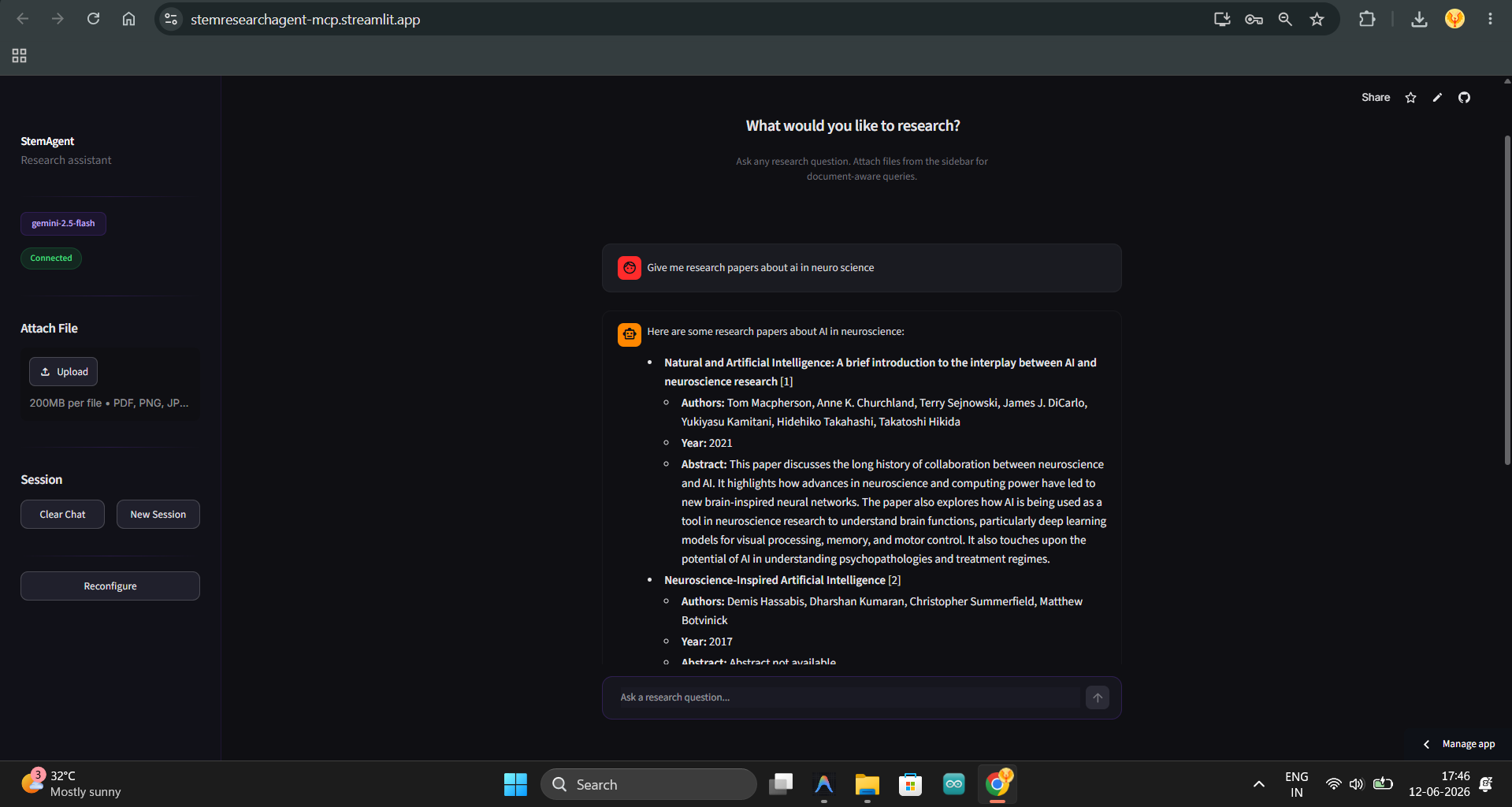
Langchain agent in action
-
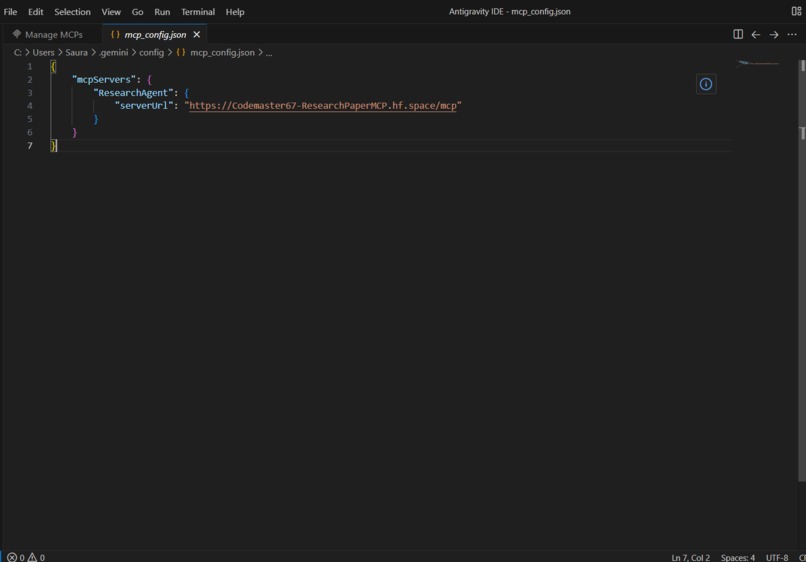
MCP server plugged in Google antigravity
-
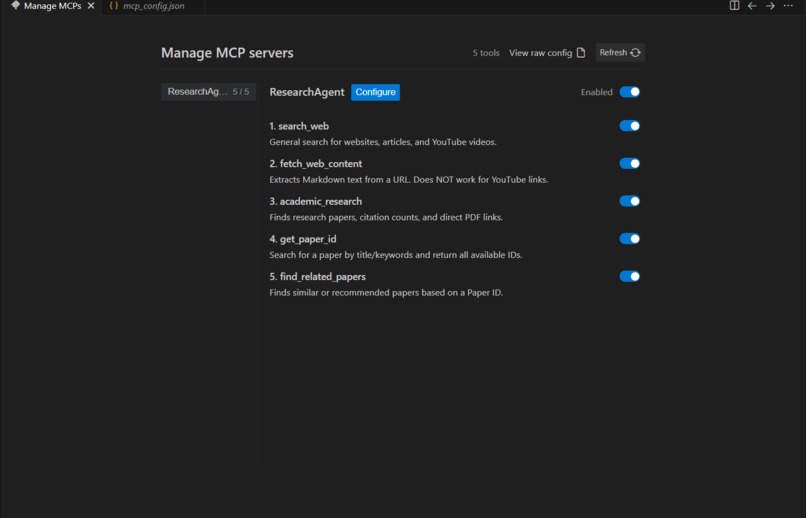
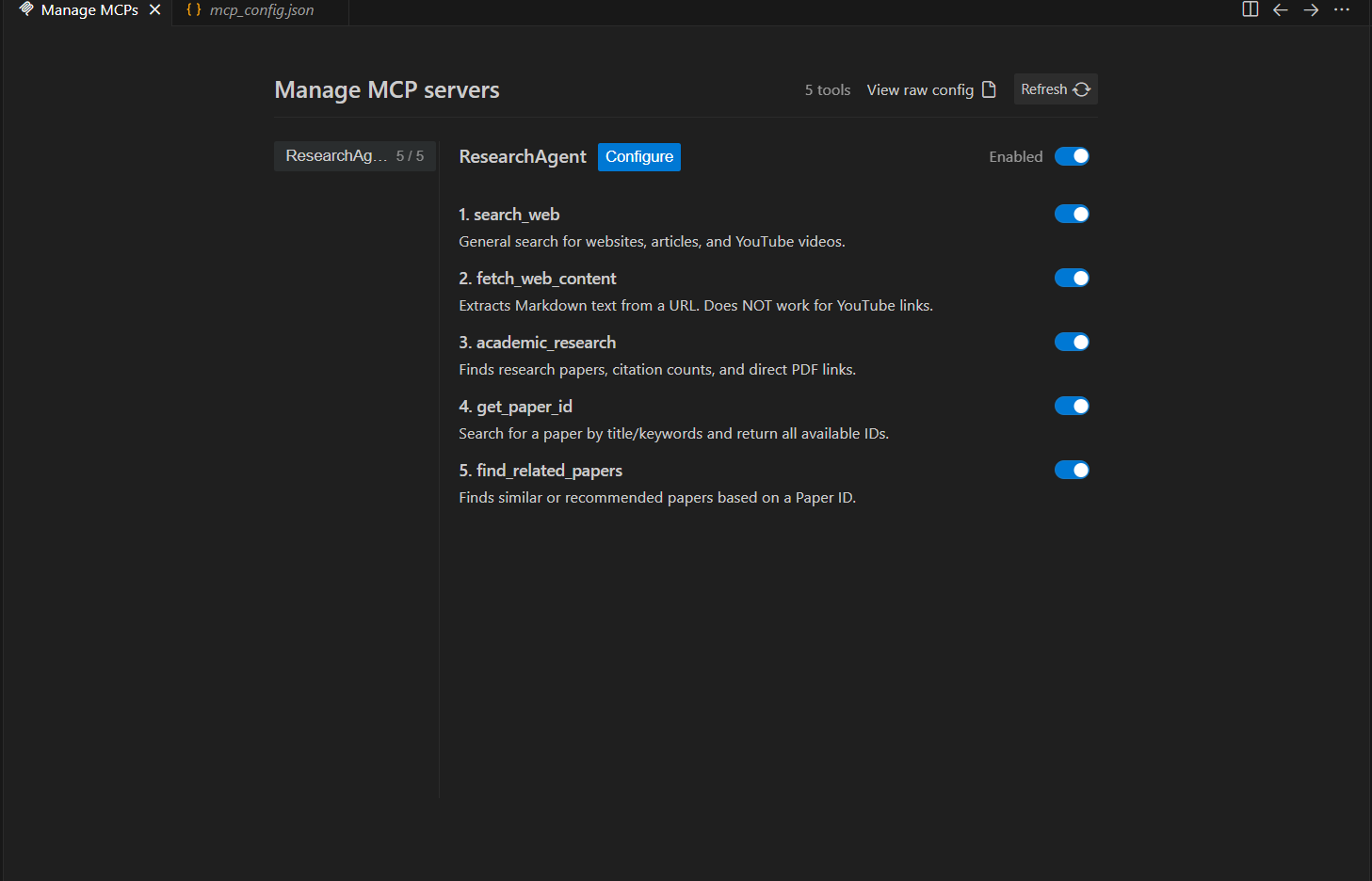
List of available tools
Inspiration
If you've ever done a literature review you know the pain you search for a paper, check its citation count, look up the journal's impact factor, skim the abstract, realize it's not what you need, and start all over again. Rinse and repeat for hours. It's honestly the most time-consuming part of any STEM research workflow.
I kept thinking what if I could just describe what I'm looking for in plain English and have an agent go fetch the papers, pull citation counts, grab PDFs, and summarize everything in one shot? That's exactly what this project does. One prompt, and you're reviewing papers instead of hunting for them.
What it does
STEM Research Agent is an MCP server that gives any LLM the ability to: 1) Search Google - for general web results and articles.
2) Read full webpages - and extract their content as clean markdown.
3) Query academic databases - (Semantic Scholar + OpenAlex) for papers, citation counts, abstracts, and open-access PDF links.
4) Resolve paper IDs - across different databases (DOI, ArXiv, OpenAlex, Semantic Scholar).
5) Find related papers - given any paper ID — great for snowball searching.
On top of the MCP server, I built a LangChain ReAct agent powered by Google Gemini and wrapped it in a FastAPI backend. The whole thing follows a plug-and-play architecture the MCP server is one independent service, the agent backend is another. You can swap out the frontend, use a different LLM, or connect the MCP server directly to Claude Desktop or Antigravity. It's modular by design.
I also put together a Streamlit frontend so anyone can try it out without any setup.
How we built it
1) MCP Server: Built with the FastMCP package. It exposes 5 tools over SSE. For academic search it hits Semantic Scholar first and automatically falls back to OpenAlex if that's down. Web search goes through SerpAPI, and webpage reading uses Jina Reader to pull clean markdown from any URL.
2) Agent Backend : A LangGraph ReAct agent using langchain-google-genai for Gemini models, mounted on FastAPI with Uvicorn. Users bring their own Gemini API key at runtime — nothing is stored server-side. The agent has memory via LangGraph's MemorySaver, so it can handle follow-up questions within a session.
3) Frontend : A Streamlit app that talks to the FastAPI backend. Dark theme, file upload support, session management — nothing fancy, but it gets the job done.
Challenges we ran into
One of the biggest challenge was to host the MCP server so it is accessible easily and after a lot of trial and error with different platforms, I landed on Hugging Face Spaces it supports Docker deployments, and stays alive long enough for demo purposes. Getting the two services (MCP server and agent backend) to talk to each other reliably across two separate Spaces took some debugging, especially around timeouts and CORS.
Another tricky bit was normalizing the response formats between Semantic Scholar and OpenAlex — they structure their data quite differently (OpenAlex uses an inverted index for abstracts, for example), so I had to write a normalization layer to make the fallback seamless.
Accomplishments that we're proud of
1) It's completely free to host and use. No paid APIs on the server side (SerpAPI has a free tier, Jina Reader is free, Semantic Scholar and OpenAlex are open). Users only need their own Gemini API key.
2) Genuinely plug-and-play : You can point Claude Desktop, Google Antigravity, or any MCP-compatible client at the SSE endpoint and it just works:
MCP Server: https://Codemaster67-ResearchPaperMCP.hf.space/mcp
3) The agent backend is also independently usable — if someone wants to build their own frontend or integrate it into a different workflow:
Agent API: https://Codemaster67-GoolgeLangchainAgent.hf.space
(Check the GitHub repo for full API endpoint docs) 4) A fallback system is used (Semantic Scholar → OpenAlex) means searches almost never fail, even when one service is rate-limited or down.
What we learned
This was my first time building and deploying an MCP server end-to-end. I learned a ton about the MCP protocol itself — how tool definitions get advertised over SSE, how clients discover and invoke them. Hosting a persistent SSE service on free infrastructure was a real exercise in working within constraints.
On the agent side, I got much more comfortable with LangGraph's ReAct loop and how to structure tool descriptions so the LLM actually picks the right tool at the right time (tool docstrings matter way more than I expected). Also learned the hard way that CORS configuration needs to be thought about early, not bolted on after everything else is built.
What's next for STEM Research Agent
1) Multi-agent architecture (A2A): Instead of a single agent doing everything, I want to spin up specialized sub-agents one for literature search, one for methodology comparison, one for citation analysis and have them collaborate. 2) AI Debates / Brainstorming mode : Two agents take opposing positions on a research question and argue it out, with a third agent summarizing the consensus. Could be genuinely useful for exploring a new research area from multiple angles.


Log in or sign up for Devpost to join the conversation.