-
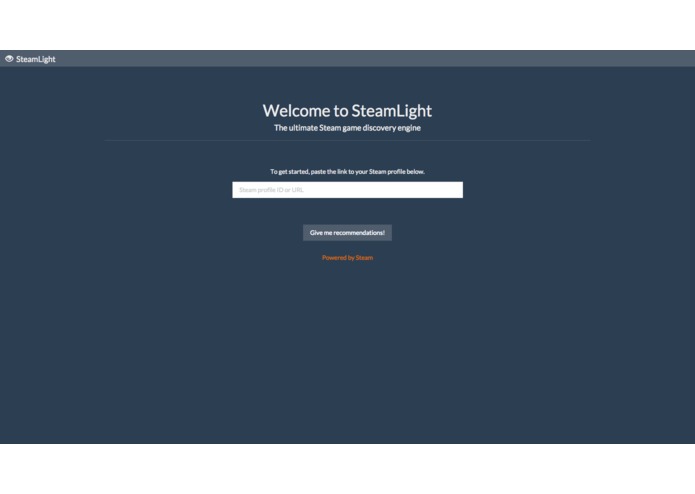
Home Screen
-
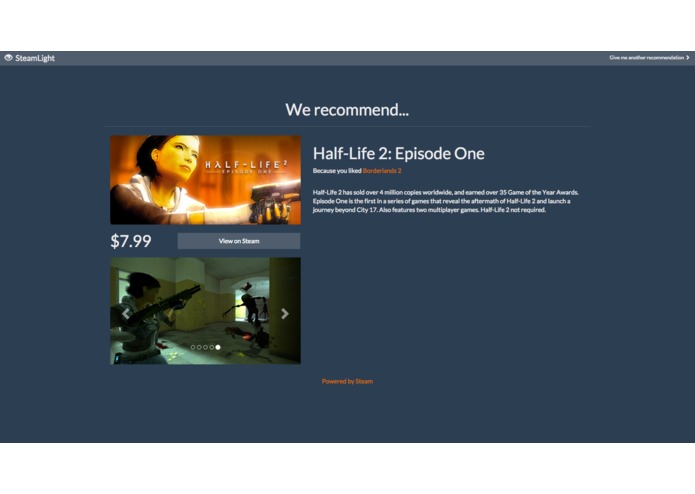
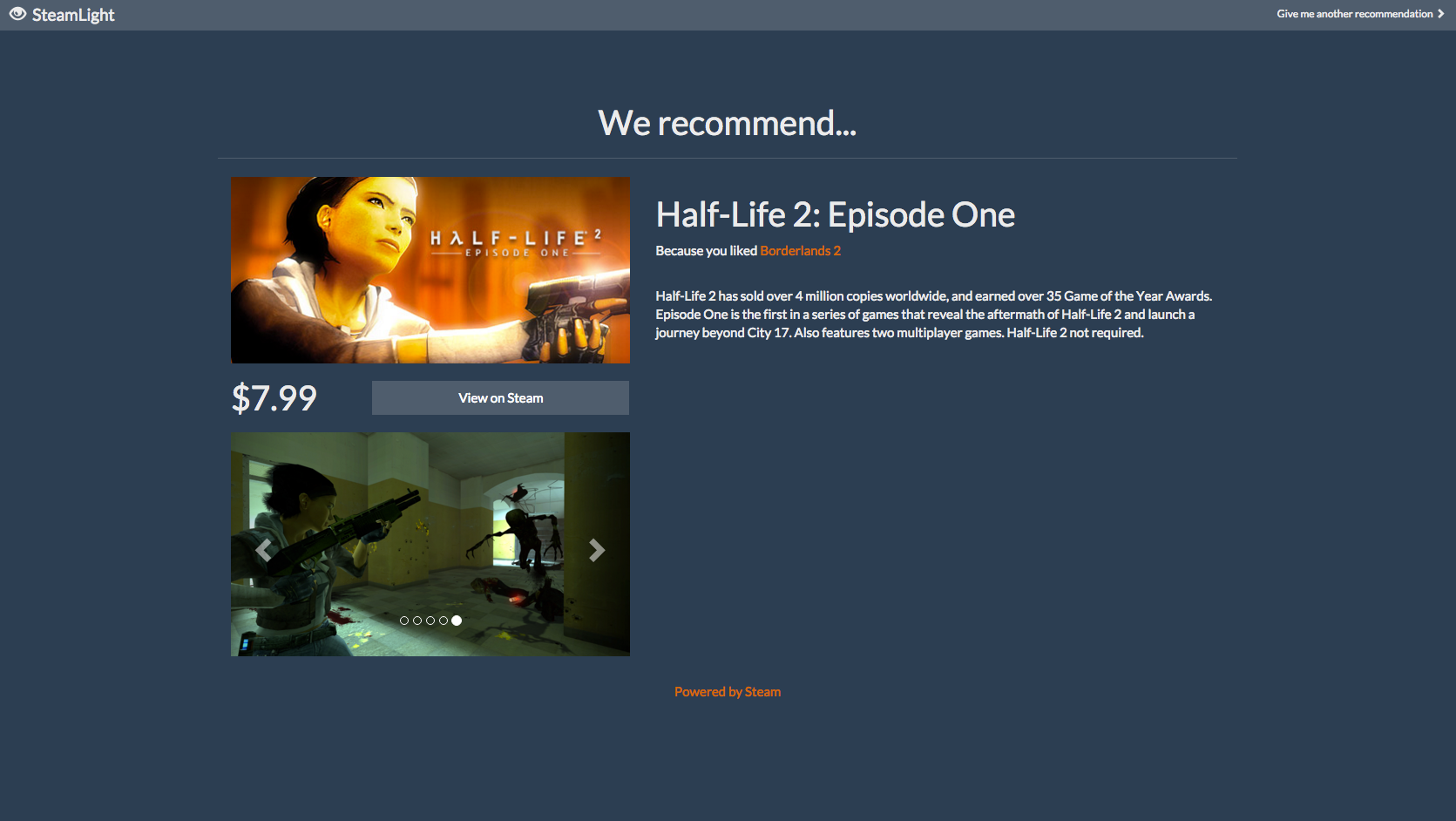
Recommendation: FPS
-

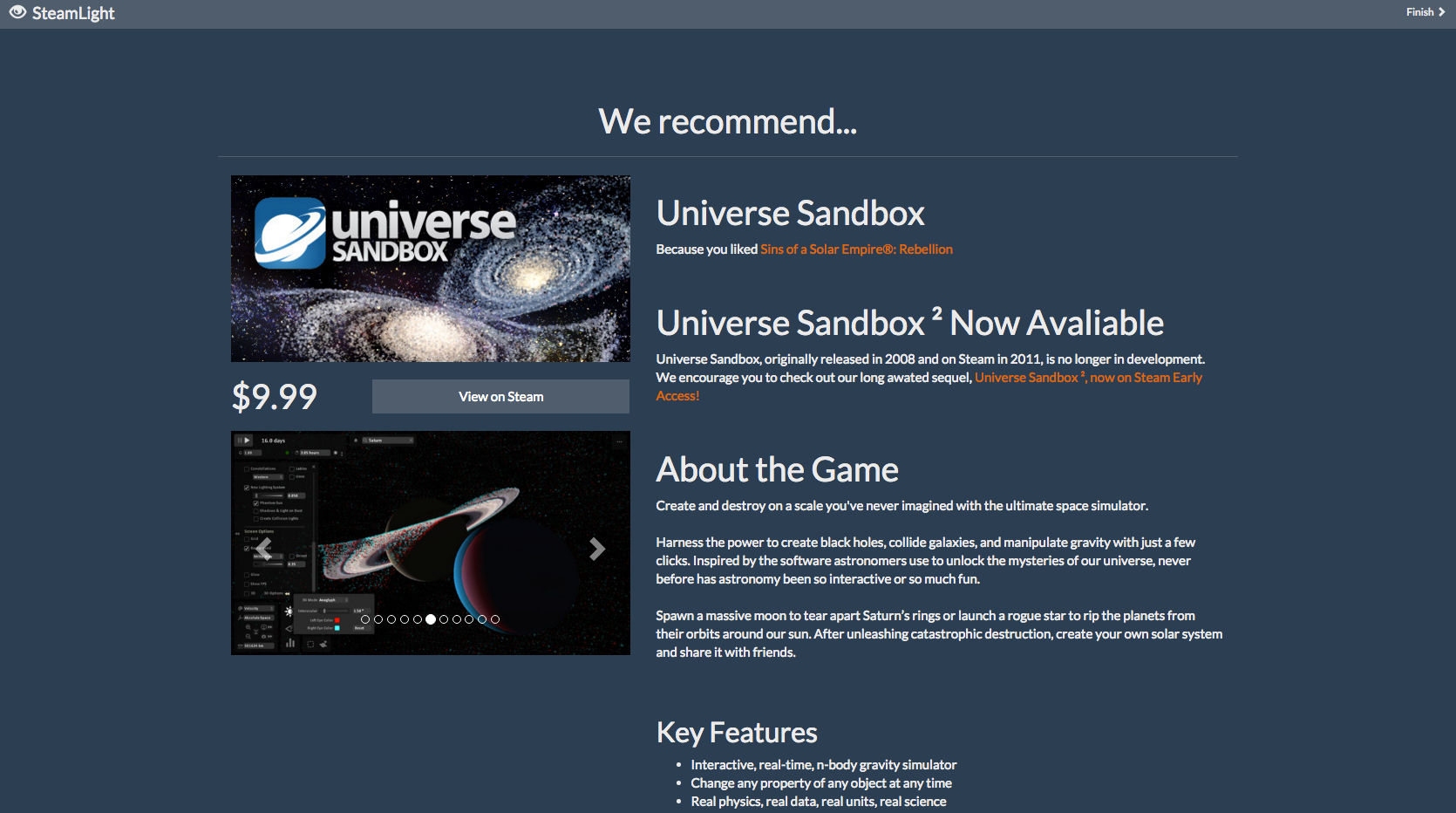
Recommendation: Simulation
-

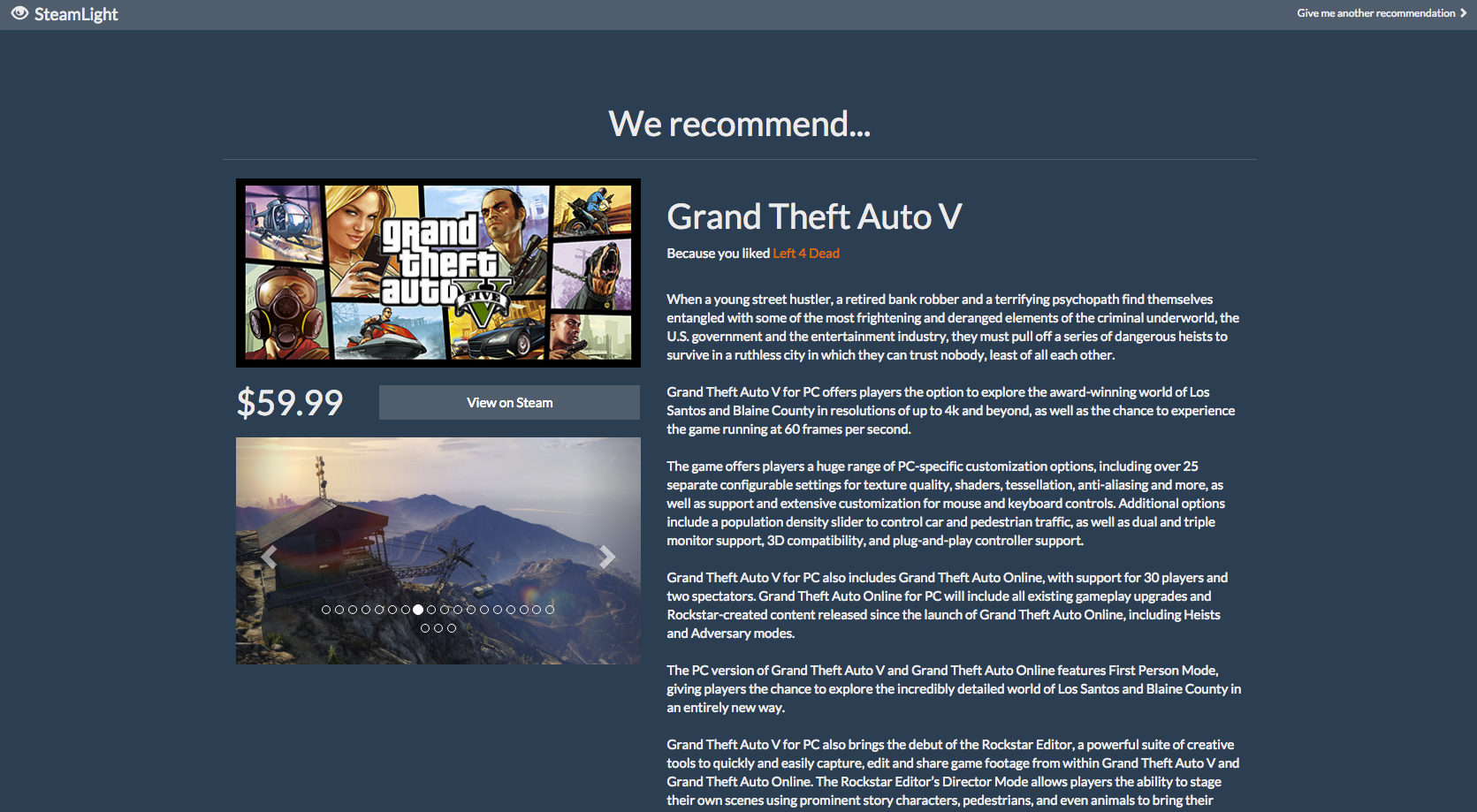
Recommendation: Action
-
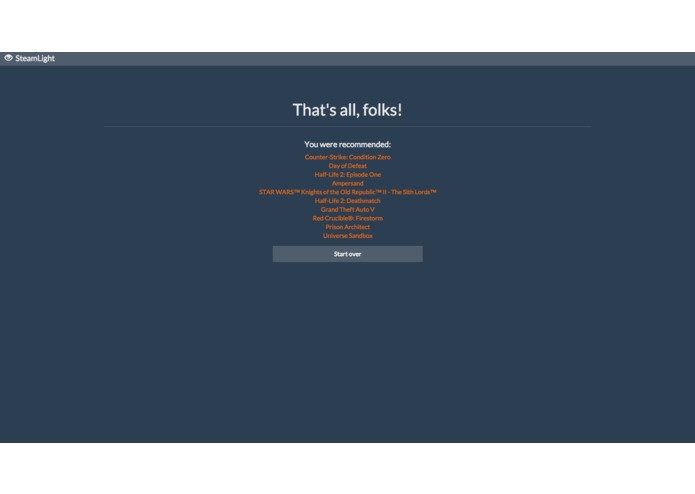
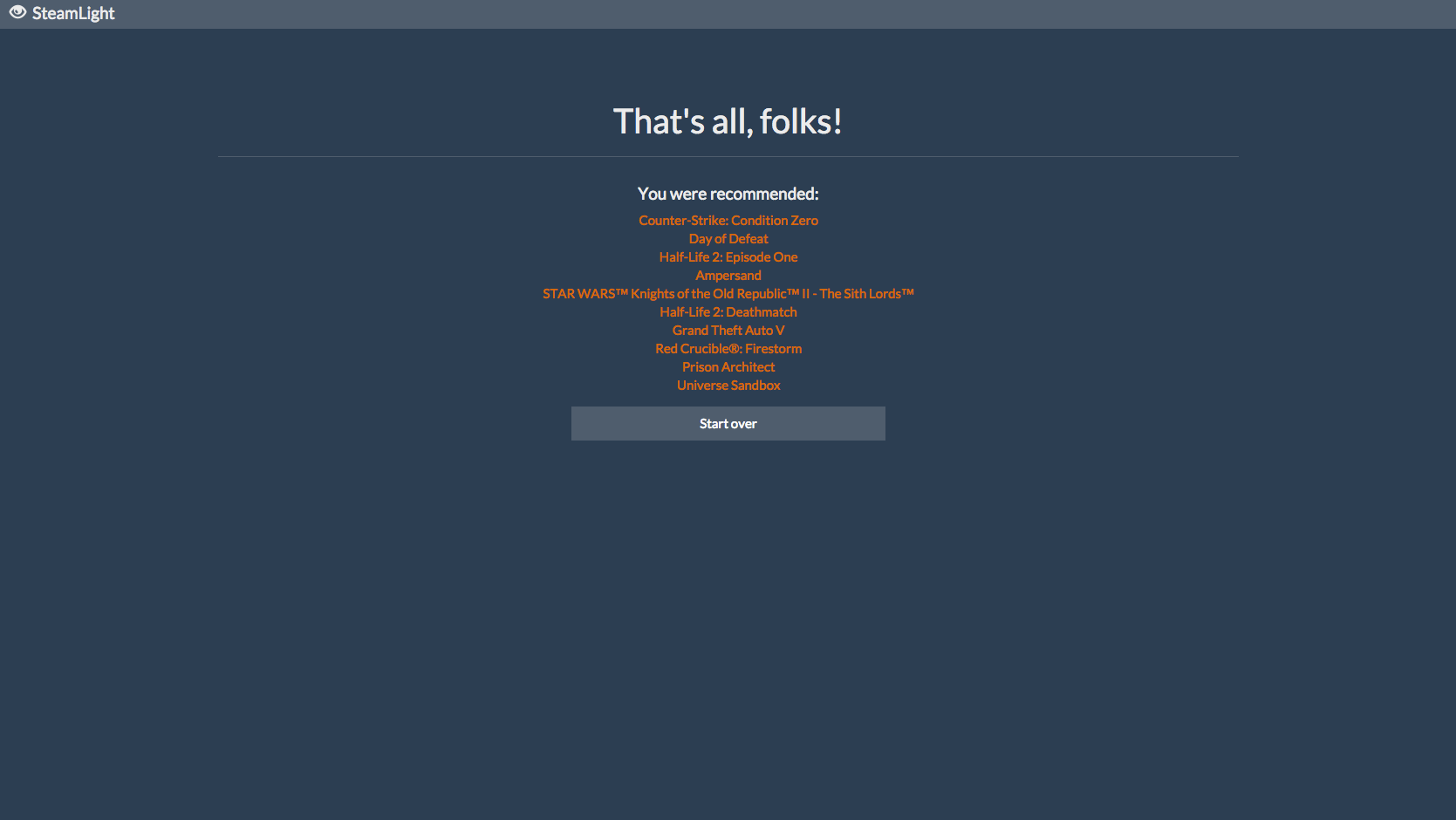
A full set of recommendations
Inspiration
Steam, a storefront for PC games, offers a "discovery queue" feature which is intended to allow users to discover new games that they might be interested in. However, the queue generally only recommends games based on how popular they are and not based on the user's personal preferences. We want to improve this.
What it does
Users paste the URL of their Steam profile into our website, which analyzes their profile and determines what games they enjoy and what they enjoy about them. Then, it scans our database of about 800 Steam games to find games that are similar to them.
How we built it
SteamLight is separated into two main components: a website and a recommendation engine. The website is built using Meteor on top of Node.js and communicates with the Steam servers to grab profile information, passing it on to the recommendation engine (written using Python/Flask) for processing. The recommendation engine then assigns "weight" values to the games in the user's profile based on playtime both recently and over the life of the purchase. The games with the highest weight values are compared to other games in our database using several different metrics in order to find similarities. Some of the values taken into account include game genre, popularity, user-assigned tags, and the developer and publisher.
In order to efficiently find similar games on Steam, we pulled game data from several different sources (both official and unofficial) and aggregated them into a Microsoft SQL Server database. We then queried this database to collect data for recommendations. Due to time constraints, we were only able to dump around 800 of the most popular games from the store. (However, this is more than enough for our purposes.)
Our databases and our servers are all hosted on Microsoft Azure.
Challenges we ran into
The biggest challenge that we faced was designing a suitable algorithm for finding games similar to the ones in a user's library. We went through many iterations to arrive at the algorithm we currently use, but there is still a great amount of room for improvement.
Accomplishments that we're proud of
We believe that we have succeeded in providing more interesting recommendations than Steam's official discovery queue. We found that many of the games recommended to us with our system do indeed match our interests. We wrote a logarithmic scaled two-variable weight function that was very successful in classifying the most interesting or currently captivating of the user's owned games.
What we learned
We learned applying algorithms to real world applications involves not only understanding how to plug data into an API (ie. sci-kit learn) but also understanding how the algorithm fundamentally works, which allows you to expand in different ways. In particular, we wrote our own weight-rank function that provides the basis for our content filtering algorithm.
We also used an MSSQL database since we chose to use Microsoft Azure. While we had experience with relational databases, none of us had directly used MSSQL and we pretty quickly picked up on its minor differences in comparison to other relational databases like MySQL.
What's next for SteamLight
Our immediate next step would be to process the entire Steam library. We could not reasonably do this for the hackathon due to API rate limitations.
In addition we would like to improve our recommendation algorithm by employing a hybrid content-based/collaborative filtering recommender, which would classify recommendations using not only the game metadata but also the metadata of connected/friended users. We would also like to implement more speed-optimized structures such as sparse matrices so that we could effectively use more powerful ML techniques such as Bag-of-Words or TF-IDF to process larger textual descriptions without sacrificing response speed. One possible route would be to instead use the built in and optimized Azure ML functionalities.
We would like to better utilize the database so that more information is cached on our servers. This would greatly reduce our long-term dependency on the Steam API.
Finally, we would love to eventually be able to expand SteamLight to include support for other platforms. Adding support for Xbox One and PS4 games, for example, would greatly expand the system's userbase and would provide a much more diverse selection of games.




Log in or sign up for Devpost to join the conversation.