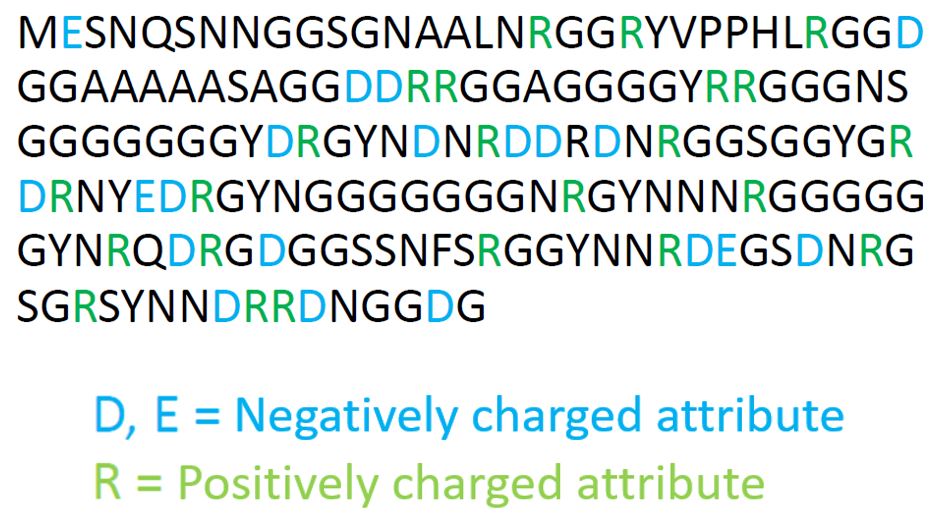
Inspiration
The knowledge of protein structures helps in the development of new drugs to treat various diseases. However, it is extremely difficult and time consuming to exhaustively study each protein sequence manually in a laboratory. We believe that automating the analysis of such sequences will make the process of developing new drugs for rare diseases faster, easier and more reliable.
What it does
We generate custom word embeddings or vector representations for protein sequences to capture their intrinsic properties instead of explicit properties. We used these representations to classify the sequences as ordered or disordered.
How we built it
Feature engineering- Word embeddings for the protein sequences Input array- size of data x length of sequence x embedding dimension Sum along the length of sequence to generate vector embeddings Model that worked best- Random forest Random search hyperparameter optimization Result- F1 score – 0.835; MCC – 0.671
Challenges we ran into
Representing protein sequences in a form that can be learnt by the machine learning model
Accomplishments that we're proud of
Fairly good results
What we learned
Moving from explicit to implicit features learnt by the model itself improved the result by a large margin. So, we learnt that feature engineering is a major step in a machine learning project.
What's next for Statistical machine learning for protein classification
Use deep learning models like CNN to further automate the process of feature engineering.
Built With
- allennlp
- python
- scikit-learn
- seqvec

Log in or sign up for Devpost to join the conversation.