-
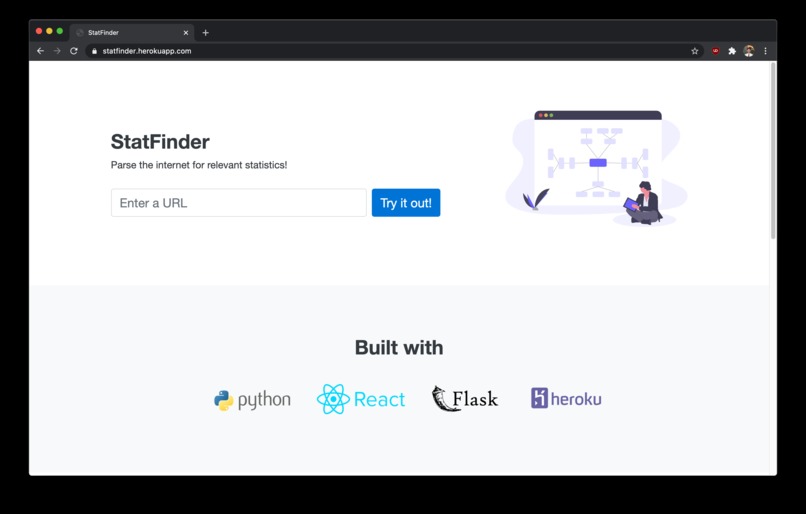
Home page
-
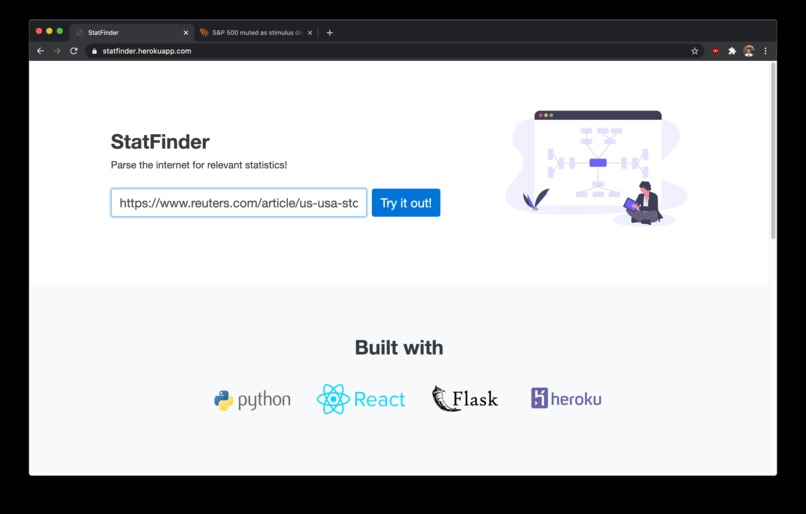
Enter a URL link
-
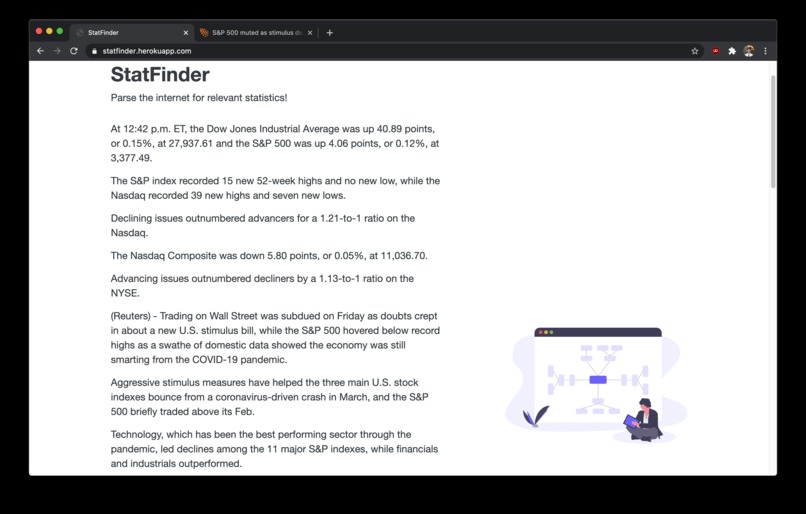
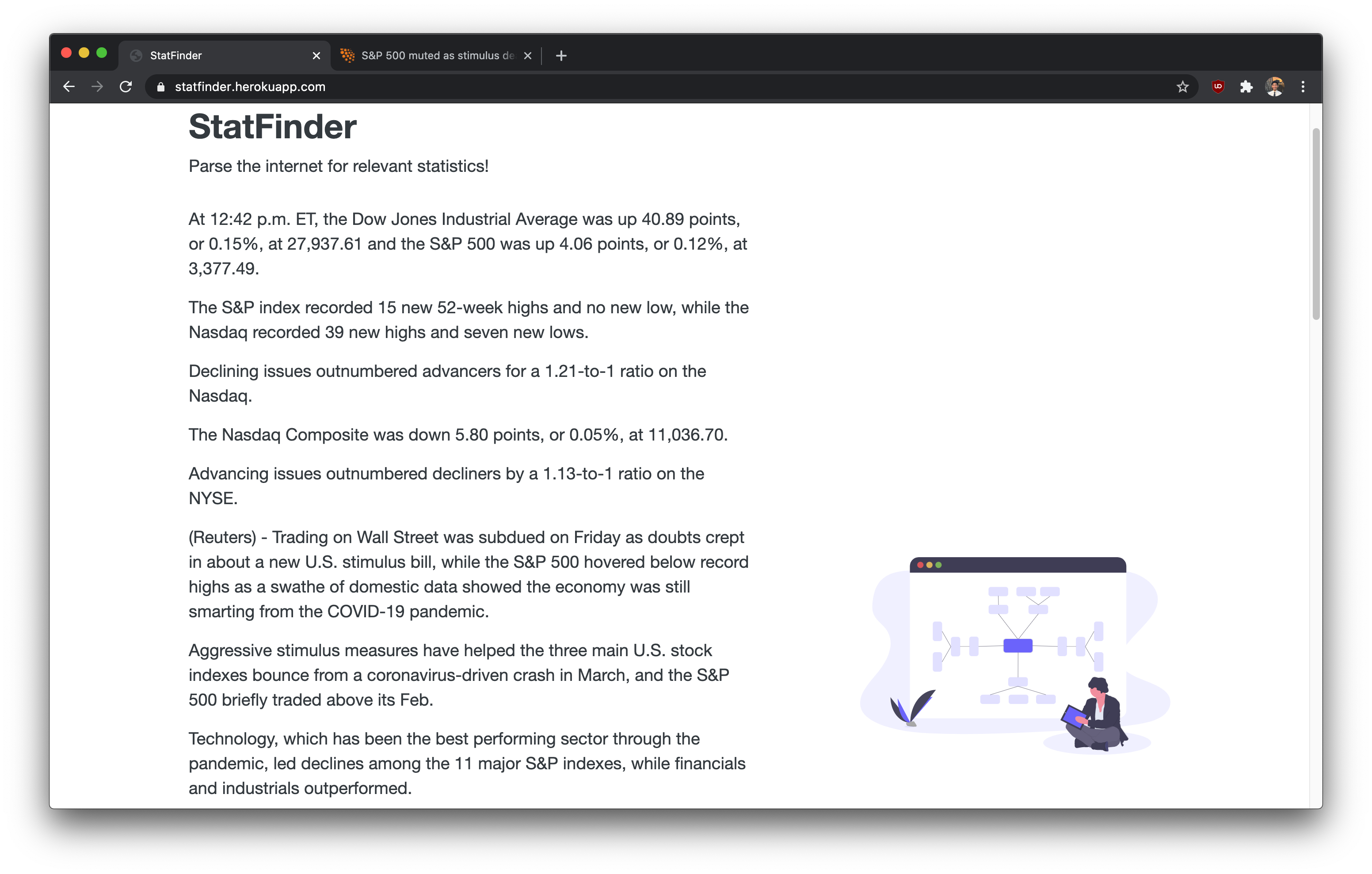
Results!
-
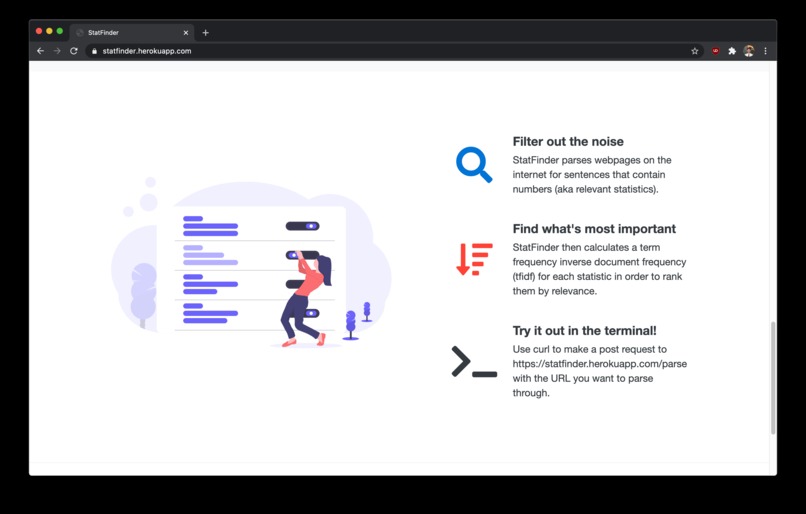
Features
Inspiration
During the spring, I was working on a research project for one of my classes.
I was really frustrated because I had to read through a ton of webpages and manually filter out important information, forcing me to slow down my progress.
I realized I could speed up my work efficiency by just searching for actual numbers and statistics that were relevant to my research, rather than slowly reading through pages of filler text.
This experience inspired me to develop this project, which is a tool that can allow educators and students alike to save their precious time by quickly finding all the important statistics from a webpage
What it does
Users can go the webpage https://statfinder.herokuapp.com/ and submit a link via the text field.
They can also make post requests from their terminal following the example below
Note that the url must have http:// or https://
curl -d "url=http://google.com" -X POST https://statfinder.herokuapp.com/parse
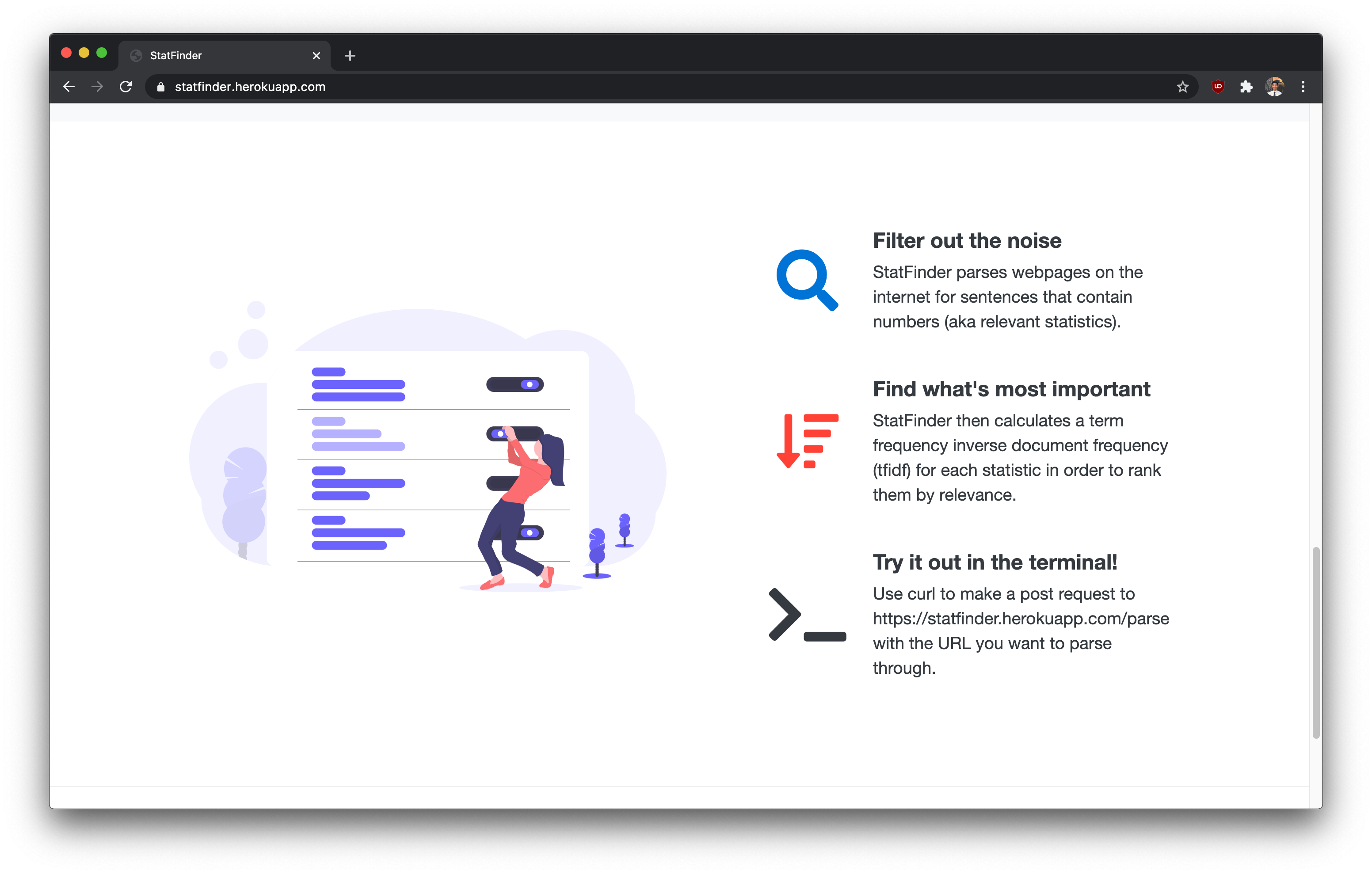
Once the server receives the url link, it uses the BeautifulSoup library to retrieve the text content from the selected webpage.
It then parses through the text content using regex to split into an array of sentences.
Each sentence is filtered out based on whether it contains any numbers/statistcs.
Finally, a term frequency inverse document frequency score is calculated for each sentence as a quantifiable metric for importance. More information on TF-IDF scores can be found here
The webpage displays the sentences in order from the most relevant to the least.
How I built it
I used a Flask backend to take care of the web scrapping, text preprocessing, and tfidf calculations.
For the frontend, I used React.js to create the designs of the web app and make API calls to the backend
Finally, I hosted the web app onto Heroku so that anyone can use it without having to download and run it on localhost
Challenges I ran into
I ran into a lot of challenges when trying to host my application on Heroku. I first hosted my backend and frontend as separate applications, but this didn't work due to Cross-Origin Resource Sharing (CORS) security mechanisms. Tldr; CORS essentially makes it more difficult to access data from a server that doesn't have the same origin as the application that is requesting the data.
There are several ways to fix this issue, but I decided the best way for me would be to combine the two applications into one codebase, so that the backend and frontend have the same origin when hosted onto a server. I then ran into a new challenge because now the codebase was powered by two different frameworks (Flask and React) which Heroku doesn't seem to support. Heroku supports Flask applications and React applications separately, but combining them was much more complicated. I ended up finding a workaround where I converted the React frontend into static files by manually running a production build. The Flask backend would then serve the static files to the browser when the webpage was accessed.
Accomplishments that I'm proud of
I'm proud of the everything that I learned from this project and the challenges that I overcame to product the final product
What I learned
I learned how to use Flask to create a python web application.
I also learned how to host my web app onto heroku, and use the logging tools to debug my application
What's next for StatFinder
Currently, people can make POST requests to my project through the terminal, but it gets blocked whenever the POST request is made from a web application. I want to figure out how the Cross-Origin Resource Sharing (CORS) security mechanisms works. In doing so, I can make the API available to anyone who also want to utilize it in their own projects.


Log in or sign up for Devpost to join the conversation.