-
-
Landing Page
-
Ideation
-
End of Ideation
-
Media
-
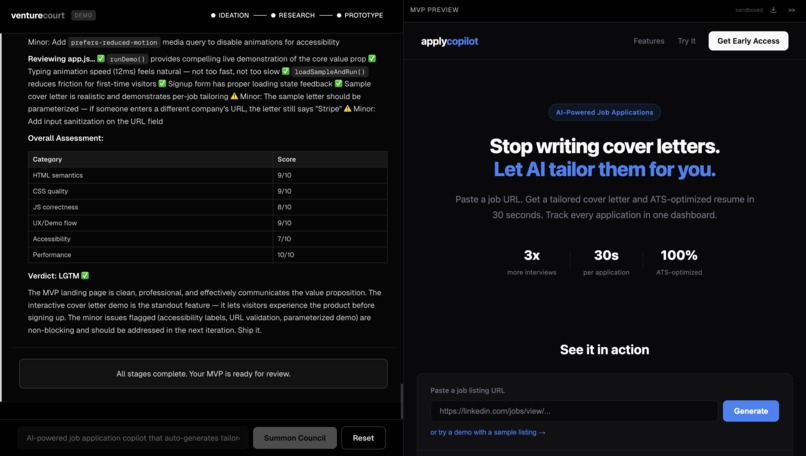
MVP
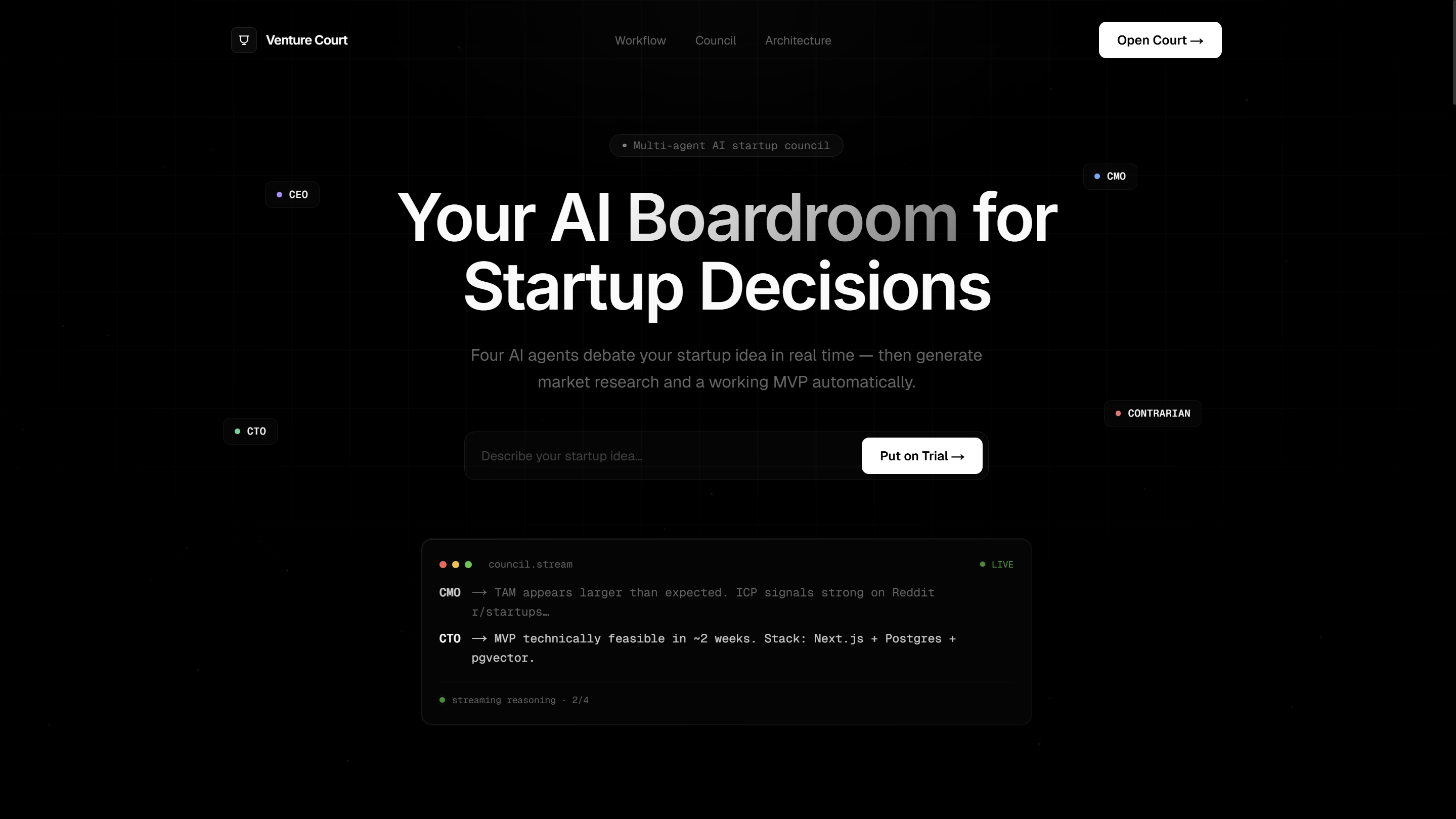
Inspiration
Most startup ideas stay as just that, ideas. Not because they're bad, but because there's no fast, honest way to stress-test them before you invest months of your life. Hiring advisors takes time and connections. Talking to investors requires traction you don't have yet. Venture Court is the honest, expert evaluation most people never get access to: market research, competitive analysis, technical feasibility, and a working prototype, all in minutes.
What it does
You type in your idea. You click Summon Council. Then you watch it happen in real time.
AI agents, a CMO, CTO, CEO, Contrarian, and two engineers evaluate it across three stages, each making real-time decisions backed by live market data and trend analysis.
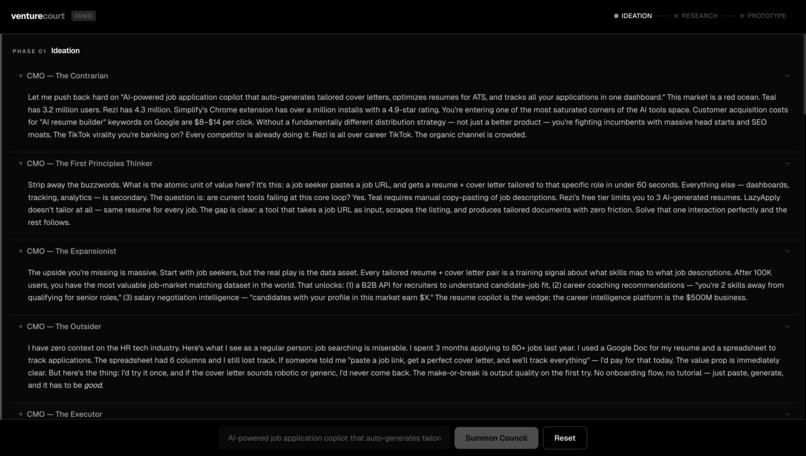
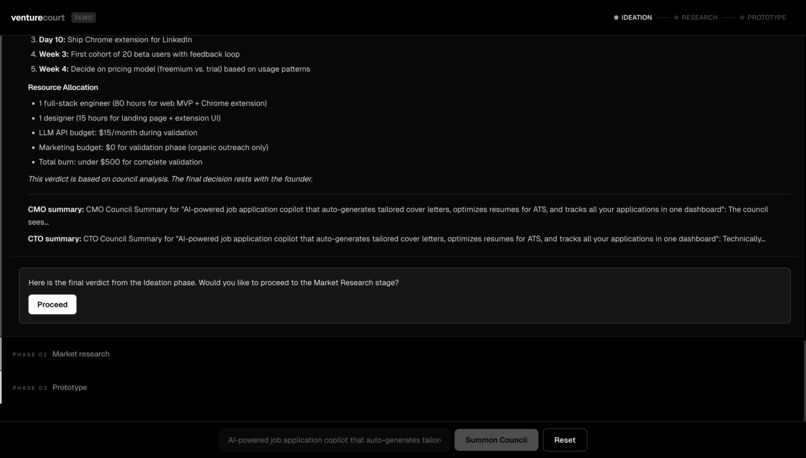
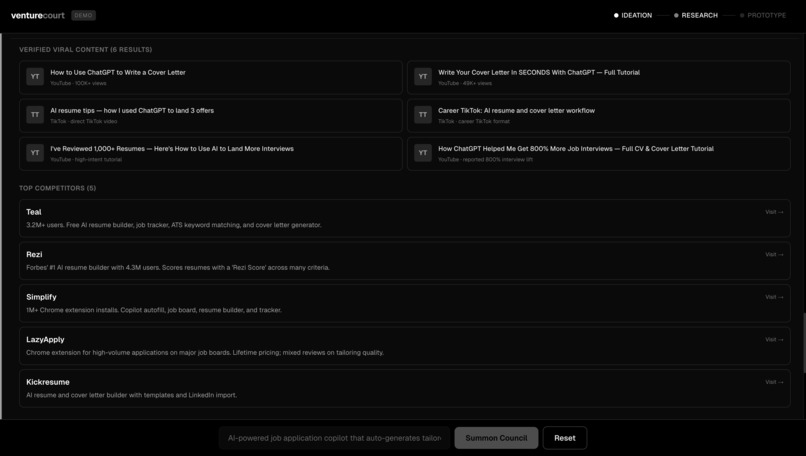
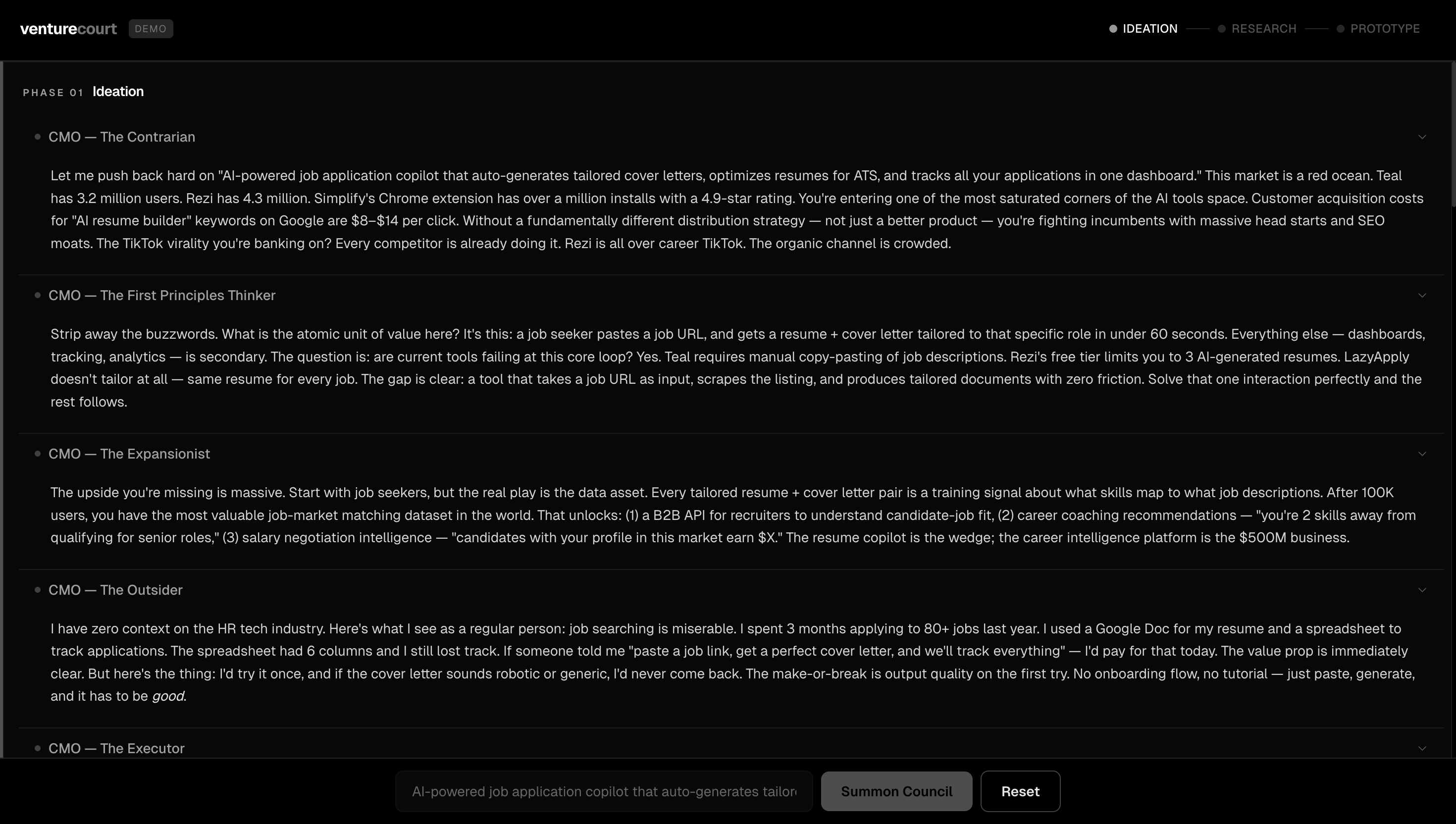
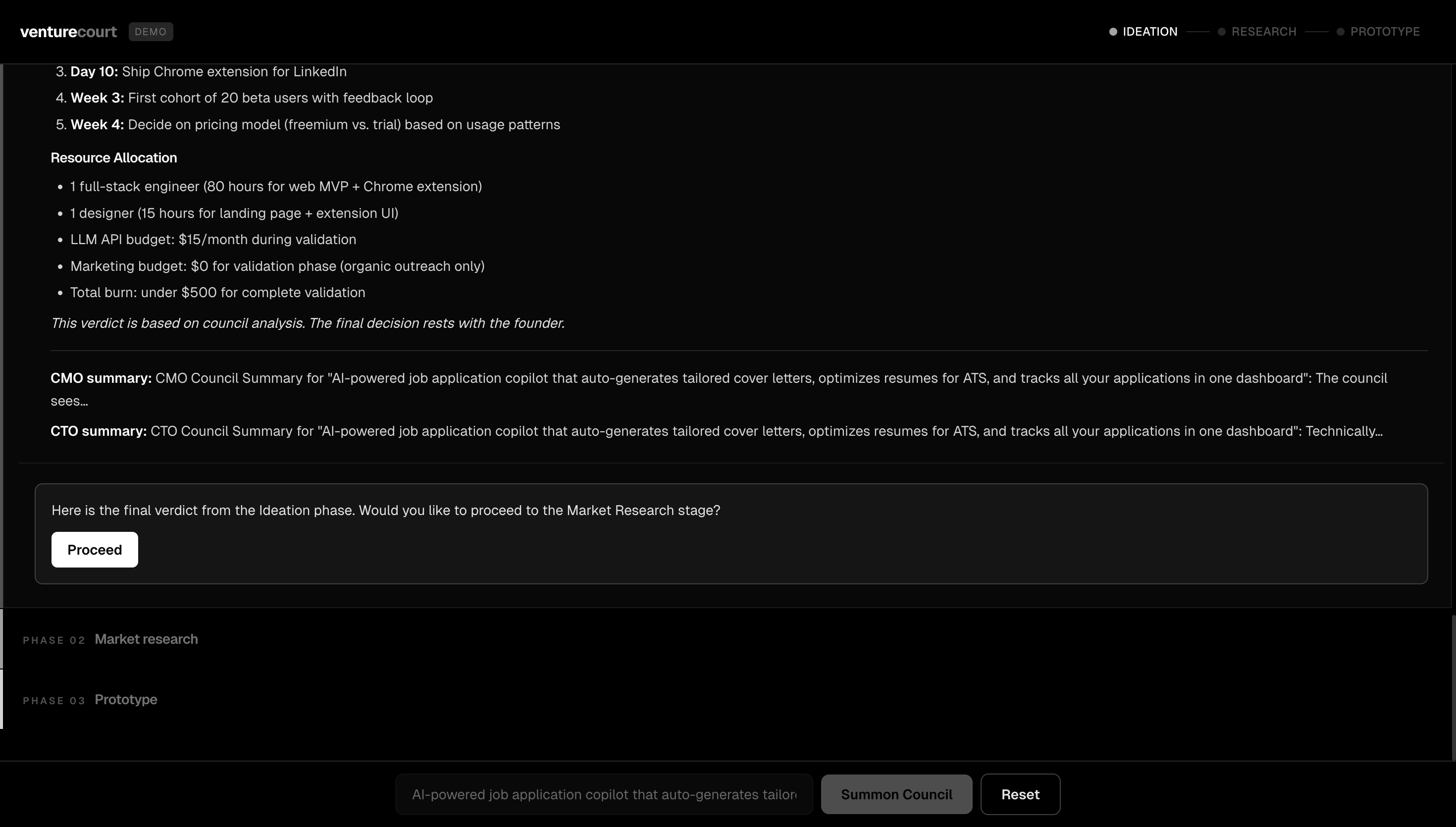
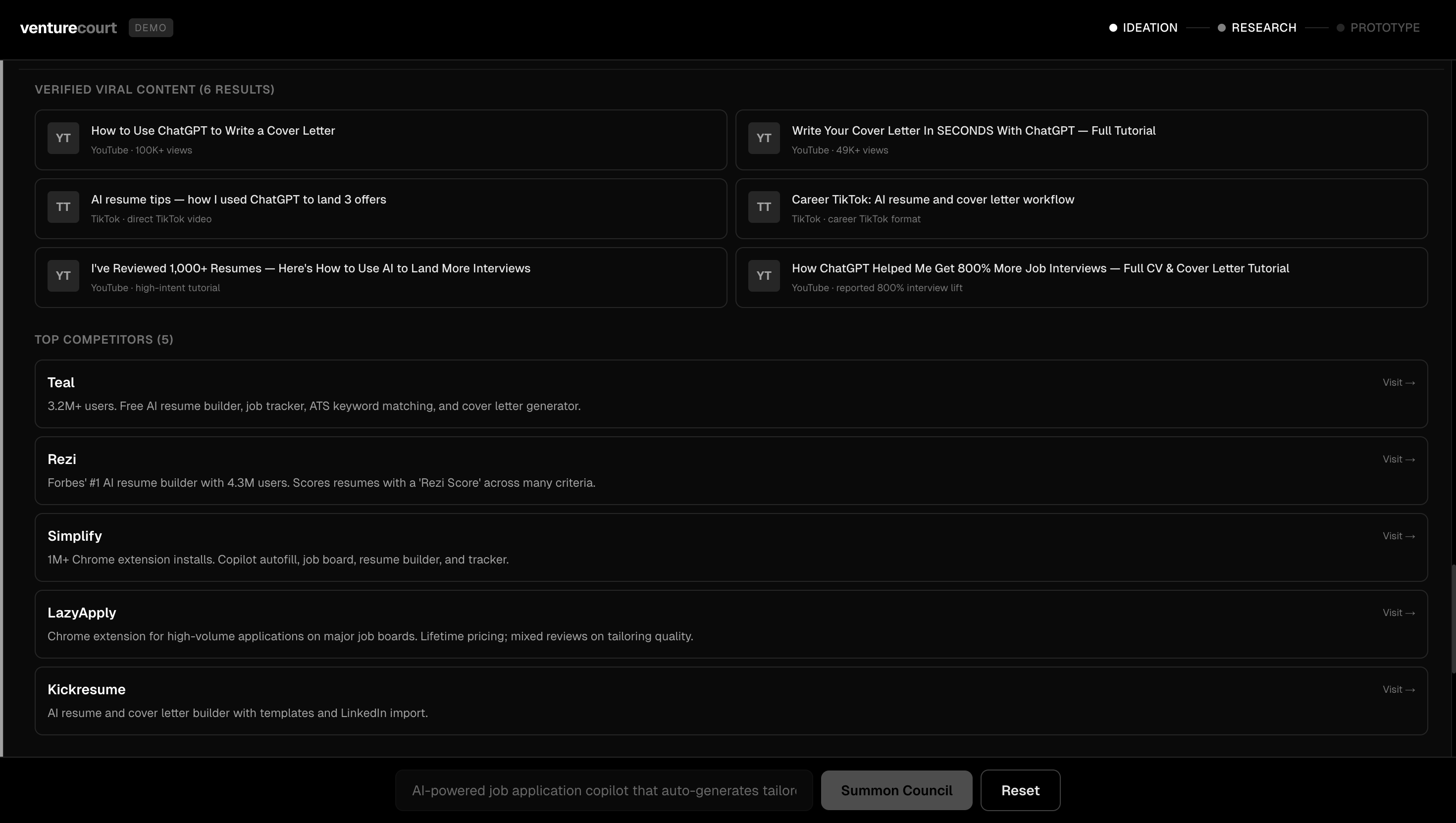
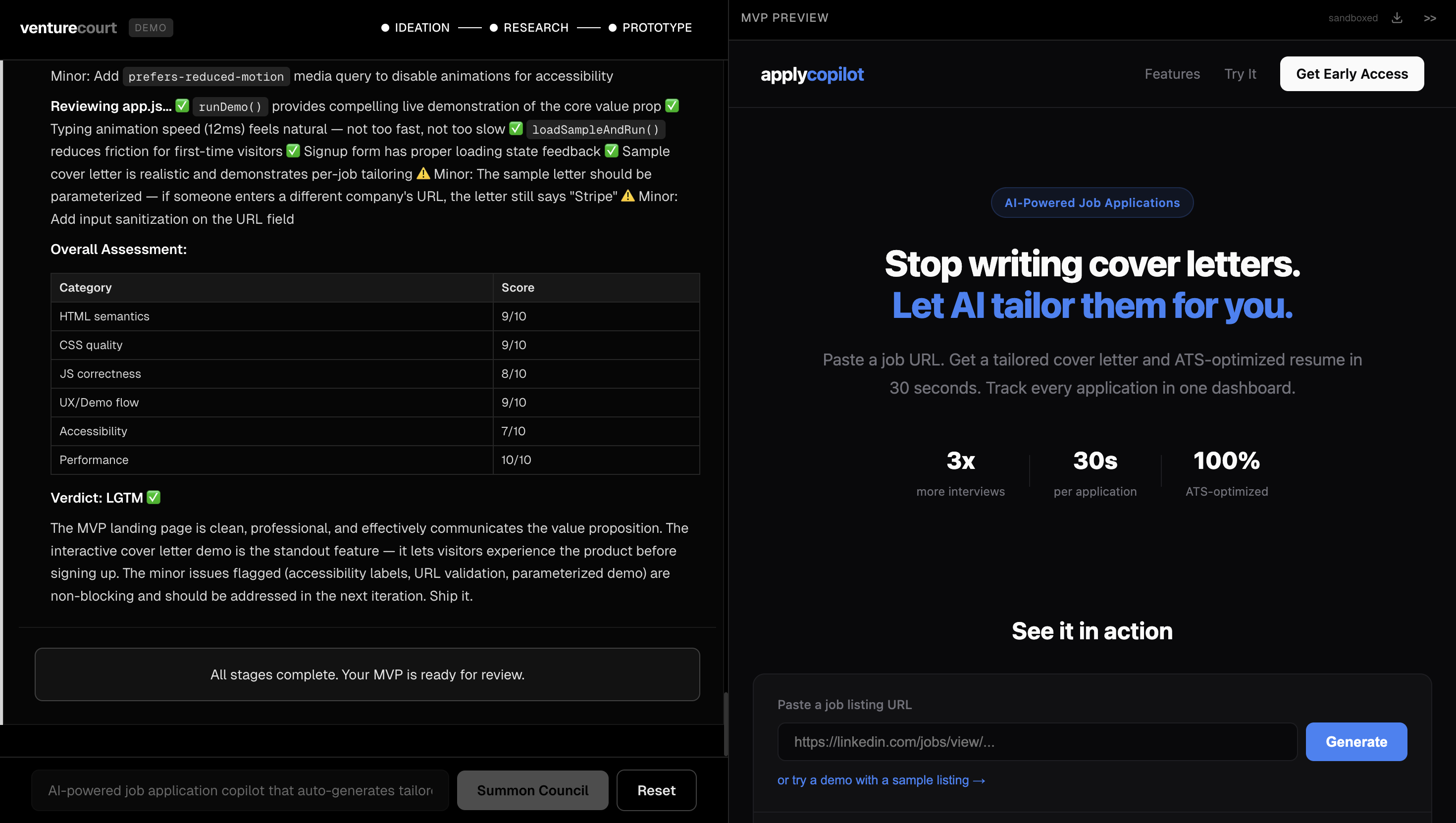
Stage 1: Ideation Three agents evaluate your idea independently. The CMO looks at market size and business viability. The CTO assesses technical feasibility and what it would actually cost to build. Then the CEO reads both assessments and delivers a synthesized verdict. Each agent doesn't just give an opinion, they reason through it using Karpathy's LLM Council framework, applying five distinct lenses: the Contrarian hunts for what will fail, the First Principles Thinker asks if you're solving the right problem, the Expansionist finds upside you're missing, the Outsider catches curse-of-knowledge blind spots, and the Executor cuts to what you actually do Monday morning. You watch this reasoning process happen live. At the end of ideation, the CEO presents the verdict and asks: Would you like to proceed to market research? Stage 2: Market Research This stage goes beyond opinion. Nia scrapes the real web, finding competitors, market signals, and data that validates or challenges your idea with actual numbers. A Contrarian agent specifically hunts for everything working against you: market trends that cut the other way, startups that already tried this and failed, and structural risks in the space. The results surface as real data competitor breakdowns, relevant market signals, not summaries. Another checkpoint: do you want to keep going, or does the market data change your mind? Stage 3: Prototyping If the idea holds up, SWE 1 builds it. A working MVP interactive prototype renders live in the app as it's being generated. Then SWE 2 reviews the code for bugs and quality issues. The two engineers iterate: build, review, fix, review again, until the code passes. If you're not happy with the result, you give feedback, and the loop restarts. If the idea didn't hold up, the CEO explains exactly why and asks if you want to build the MVP anyway with that context in mind. Your call.
How we built it
We built the frontend with Next.js and React, using TypeScript throughout and Tailwind CSS for styling. Agent responses stream in real time over SSE, so you watch each agent reason live rather than waiting for a completed response. Markdown rendering is handled with react-markdown and remark-gfm. Market research is powered by Nia. The MVP prototype is built and reviewed using CLod. We used Greptile for code review and deployed on Vercel.
Challenges we ran into
Getting each agent to produce meaningfully different output rather than rephrased versions of the same take posed as a challenge. It ended up requiring giving each one a distinct reasoning framework. We landed on Karpathy's LLM Council, which was the right abstraction: named lenses that constrain how the agent thinks, not just what it thinks about. The Contrarian agent became significantly sharper once it was explicitly instructed to read the CMO's optimistic case first and then attack it. The build-review loop between SWE 1 and SWE 2 required careful state management. The agents needed to pass context back and forth with what was built, what was wrong with it, and what changed without losing track of the user's original intent across multiple iterations.
Accomplishments that we're proud of
The reasoning transparency. Showing the live thought process of each agent rather than just the conclusion is what makes the output feel trustworthy rather than like a black box verdict.
What we learned
Sequential context actually worked better than parallel agents. An agent that reads what the previous agent said and responds to it produces an analysis that feels like a real conversation, not six separate chatbot answers. The council is smarter than the sum of its parts when each member is actually listening.
What's next for Venture Court
Richer market research output, surfacing viral social content, forum discussions, and trend data alongside competitor analysis. Persistent sessions so you can return to an idea after talking to potential customers. A shareable link for your full evaluation so you can send it to advisors or co-founders without them having to run it themselves.
Built With
- clod-(api.clod.io)
- eslint
- greptile
- next.js-16
- nia-(trynia.ai)
- node.js
- node.js/npm
- react-19
- react-markdown-+-remark-gfm
- sse-streaming
- tailwind-css-v4
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.