-
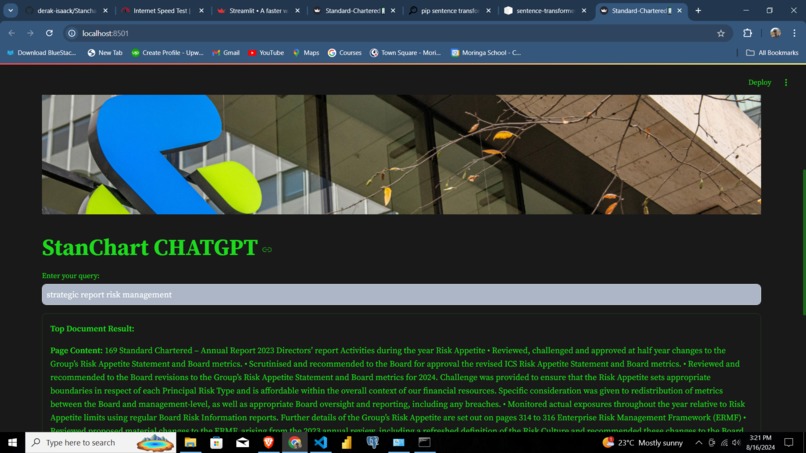
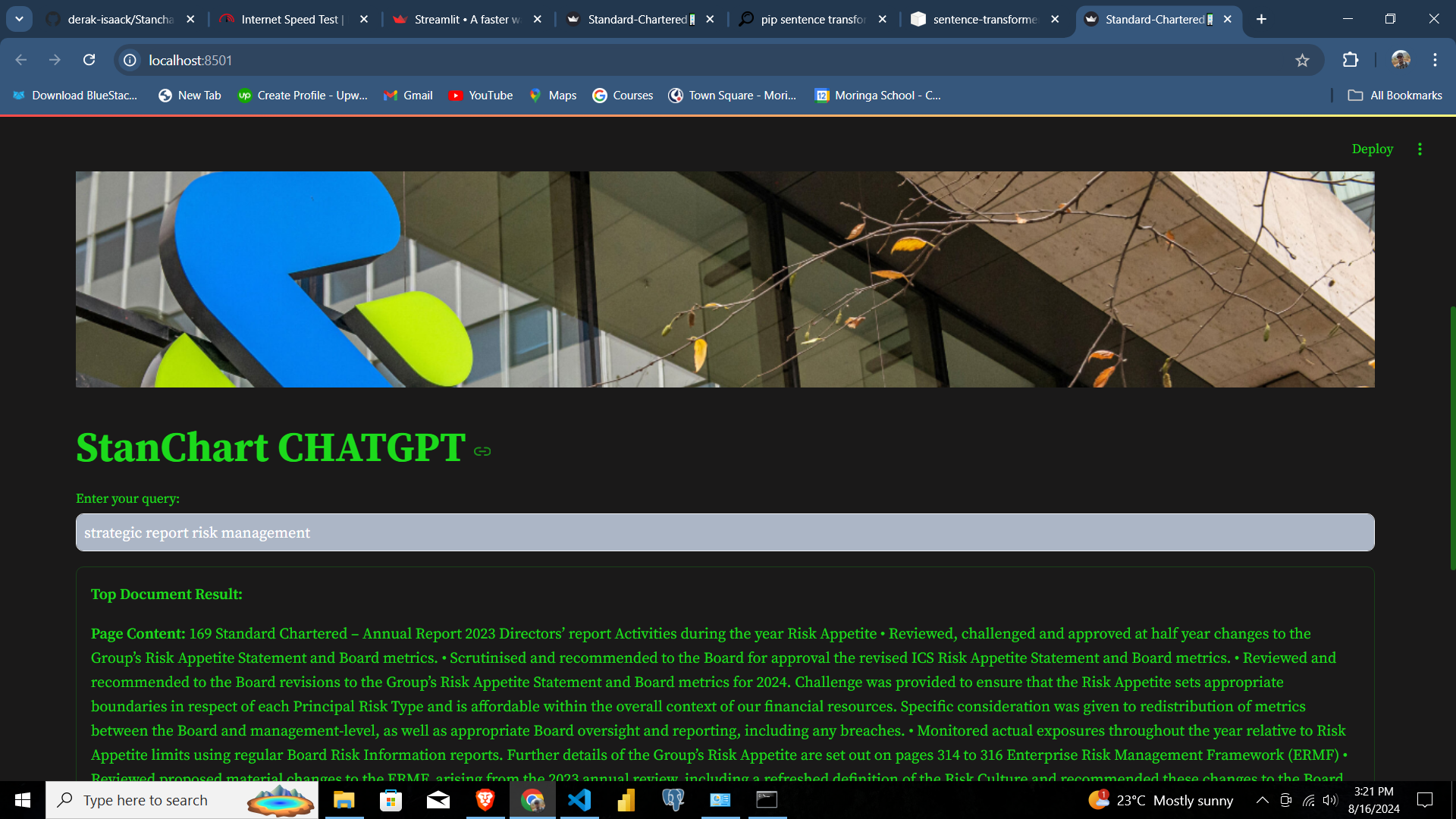
Streamlit RAG demo
Inspiration
Over time, there has been growing concern over data privacy when using OPENAI keys to train on your documents and even databases. It is for this reason that I developed a retrieval application that does not use APIs but wholly relies on document-based databases for efficient document management and information retrieval.
What it does
It is a retrieval application where a user can query for any information in the data specifically the 2023 standard chartered bank report which may not have some company information and recent resolutions on the internet.
How we built it
I used Langchain to convert the PDF into document format for easy ingestion by the LLM. I then ingested the data using a haystack pipeline to perform a similarity search on the query given by the user. The document-based database I used is AWS OpenSearch because of its super capabilities of scalability.
Challenges we ran into
Haystack does not offer efficient support when converting files in other formats into document format for ingestion with LLMs. I had to use Langchain for file conversion. Incompatibility of OpenSearch with Streamlit especially in terms of deployment.
Accomplishments that we're proud of
Managed to convert the pdf file into a document format, integrate it with OpenSearch for document search, and run efficiently in a haystack pipeline.
What we learned
Haystack pipelines. OpenSearch capabilities.
What's next for Standard Chartered 2023 report RAG
I am looking at increasing the number of reports so as to increase the knowledge base of the RAG application and it can also be used for retrieval of sensitive information without using OPENAI thereby solving the data privacy issue efficiently.
Built With
- langchain
- opensearch
- python
- streamlit

Log in or sign up for Devpost to join the conversation.