-
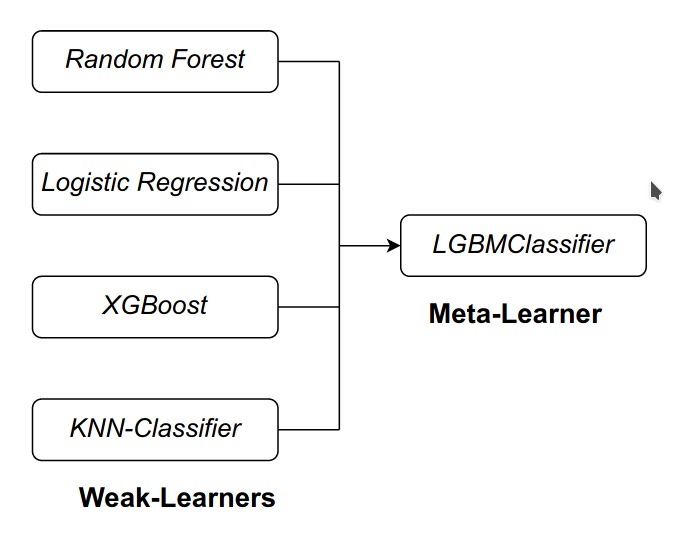
Final Model Architecture
-
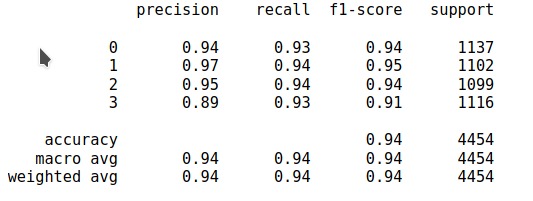
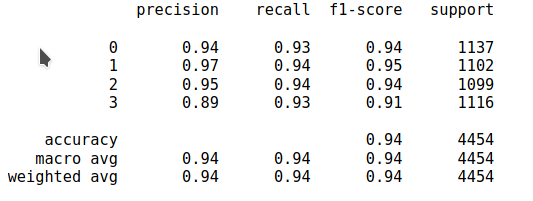
Final Scores
-
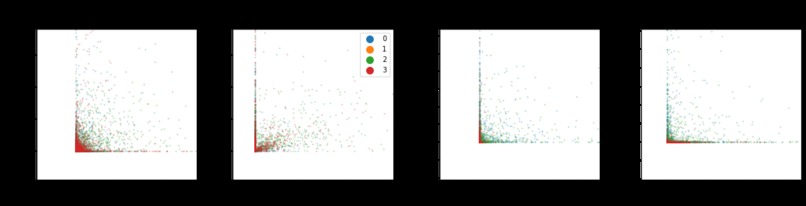
PCA Analysis
-
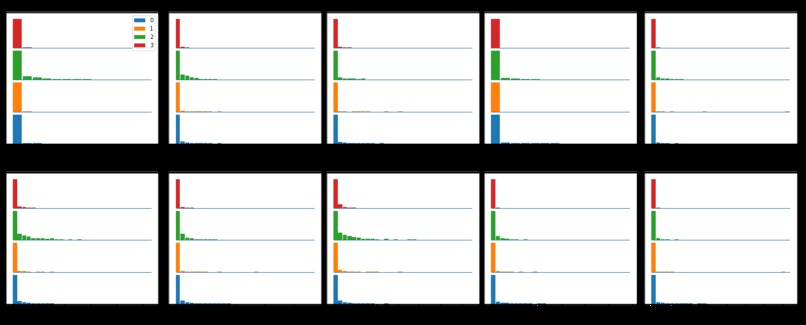
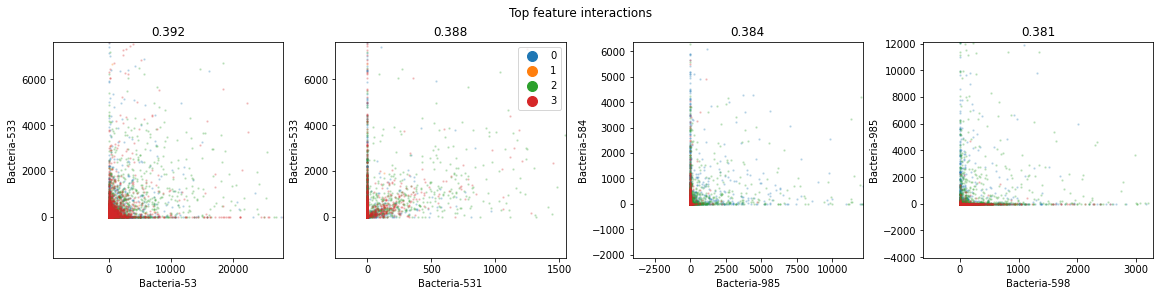
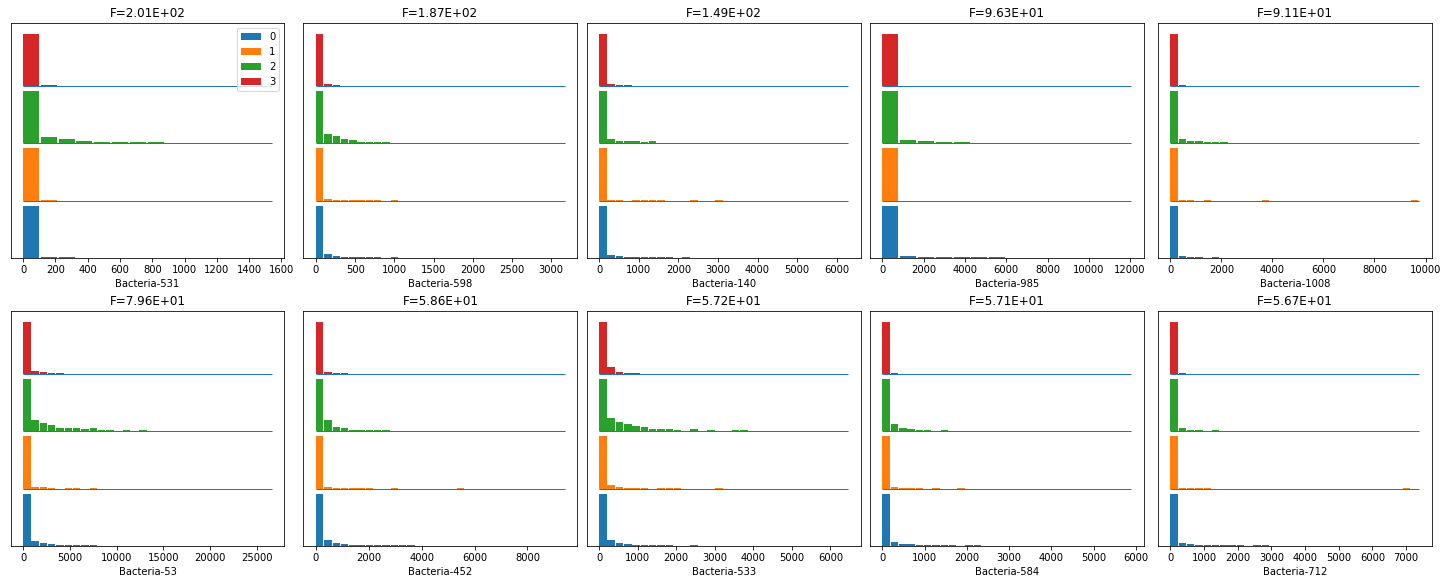
Feature Importance
-
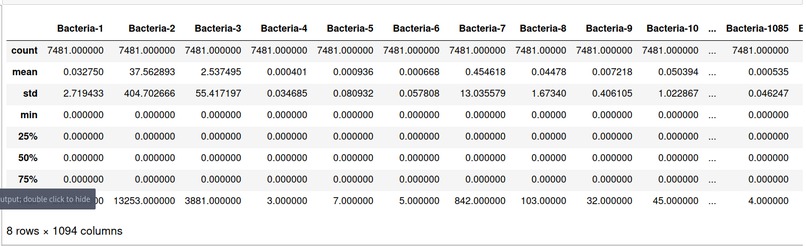
Numerical Features Description

Phyla Challenge -2:
Aim: Develop a multi-label classification model to classify different diseases based on the microorganisms in the gut microbiome.
Solution Abstract:
The data was found to contain high variance in several columns and imbalance amongst the labels{disease class}. Also, there were several features{columns} that had no{almost null} influence in the final prediction. After proper EDA{Exploratory Data Analysis}, several processing and normalization steps including scaling, resampling, encoding, etc, were undertaken to make data suitable for the final algorithms. Several features that had minimal impact on the prediction were carefully carved out from the training data. A huge variety of algorithms were tested from almost all possible categories of algorithms like clustering, linear and non-linear algorithms to solve the problem and their results were noted for the final experiment. Finally, a Stacking-ensemble model containing several weak learners like LogisticRegression, RandomForestClassifier, KNeighborsClassifier, etc were used to provide predictions to the powerful meta-learner{LGBMClassifier}. The final results include a F-1 score of 0.93556 and kappa score of 0.91407 on the given dataset without overfitting.
Exploratory Data Analysis:
After successfully separating the numerical features of the dataset, statistical information like mean, percentiles(25,50,75), mode, maximum value, standard deviation, etc were calculated for each feature. This information helps us to find the kind of scaling and normalization required in further steps. Furthermore, the presence of nulls, NaN’s and unique values in features were also checked. Also the distribution of our labels on the top extracted features was plotted on a histogram to analyze any evident distinction. PCA plots were drawn to see the impact of different levels of PCA(Principal component analysis) on the variance of the dataset. Finally, The Pearson's correlation matrix and some scatter plots(incl. Pairplots, scatter-plots, box-plots) were analyzed to gain insights of the data.
Data Cleaning and Processing:
1) A double check on NaN’s, nulls or anomalous looking data was done and any findings were corrected. The presence of any duplicate rows was also analyzed and removed. 2) Numerical and Categorical Features were separated. 3) LabelEncoder was used on the ‘disease’ feature to convert it into a numerical feature. 4) The range and mean of each feature was calculated and analyzed.
Feature Extraction:
Balanced Random Forest, XGBClassifier and Pearson’s correlation were used to find the most important features. Results of all these methods were carefully compared to find the most important features and their impact on the variance. {Finally XGClassifiers results were used} Using the top 896 features found by the XGBClassifier, we were able to reduce data by over 20% while reducing variability of data by just 1.3%. Reducing more features would have reduced variability by more than 1.5%, thus even hampering our useful data.
Feature Sampling and Scaling:
The dataset was imbalanced and had inequalities in the count of each label given in the dataset, thus resampling and balancing of the dataset was necessary. Several features were found to have a huge range, thus using scalers like Min-Max scaler would have dampened several of our important readings(feature value’s). Also, it is highly advisable to use RobustScaler in high range feature data as it works on 25 and 75 percentile points rather than maximum or minimum readings.
For feature resampling, we used SMOTE-Tomek Links, which is an mixture of oversampling and undersampling techniques, which firstly oversamples/generate new synthetic samples to balance dataset and then automatically treats the anomalous and un-trustworthy synthetically generated points by removing them. This technique helps us to reduce the amount of False-Positives(Type-II error) that usually increases on usage of oversampling.
Finally, the training and testing set were split in a 70:30 ratio, wherein the 30% test set would be used to find final metrics. All the scaling procedures were fit just on the training set, thus taking proper care that no information leakage happens during the training. {a situation where training set learns some information from test set}
Final Prediction Model:
The implemented solution is an ensemble of several algorithms, where several weak learners are used to form the basis for the prediction of the meta{powerful} learner. The weak learners used were: Random Forest, Logistic Regression, XGboost and the K Nearest Neighbours. The power or meta learner used in the stacking algorithm was the LGBMClassifier, which is a gradient boosting non-linear classifier. => All the weak learners were firstly individually trained on the dataset to find the best hyper-parameters for them. => Stacking several weak learners helps us to gain their leanings while neglecting their drawbacks. => Several combinations of weak learners and meta-learners were tried before finalizing our model. => Overfitting was checked at each step of training
F1 Score: 0.93556 Kappa Score: 0.91407
Other Approaches Tried
One-Vs-Rest: This is the second best performing technique testing during our analysis and testing phase, wherein, we split a multi-class classification problem into several binary-classification problems. {reducing complexity for the algorithm}
Bagging Classifier: Bagging is another ensemble technique, wherein several meta-estimator algorithms are trained on the dataset and a cumulative prediction is formulated through mutual voting.{Soft or hard voting}
Deep Learning: A small neural network with just 2 layers was trained using the dataset by keeping the activation function of the last neuron as softmax. This technique failed miserably as the data wasn’t sufficient for the deep learning algorithms.
Different Gradient Boosting Algorithms: Some state-of-the-art gradient boosting algorithms like AdaBoost were also tried on the cleaned data.
Best Use of Google Cloud:
I used google-collab to train the AI algorithms and a linked google drive to store the dataset and results. Also, the AI based algorithms pre-processed products like cleaned tensors, data frames, etc were also stored on google cloud, so that they can be referenced later
Built With
- imblearn
- python
- scikit-learn
- theano


Log in or sign up for Devpost to join the conversation.