-

logo
-
Homepage
-
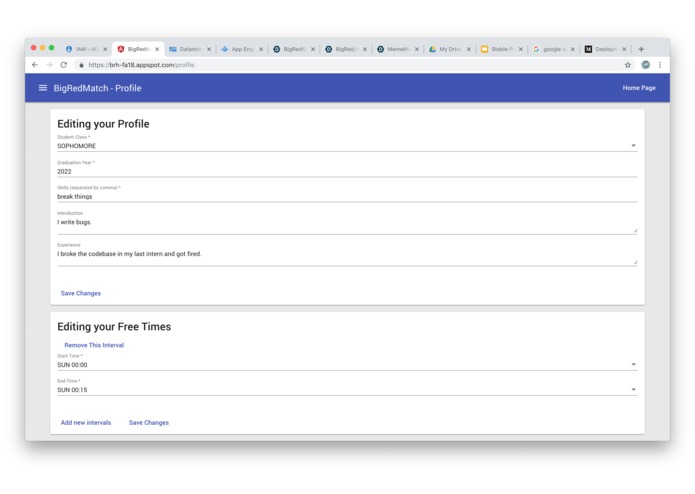
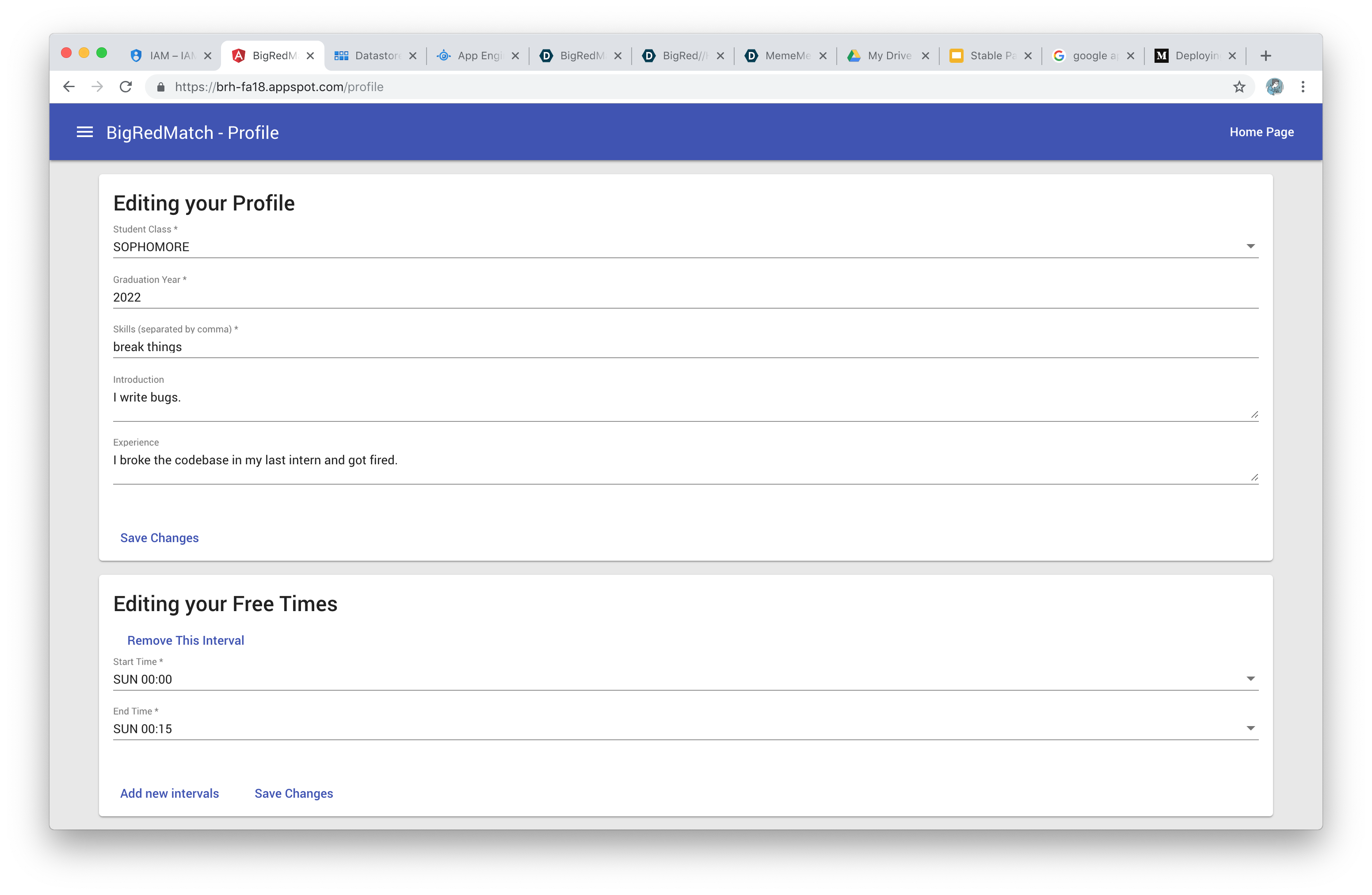
Profile
-
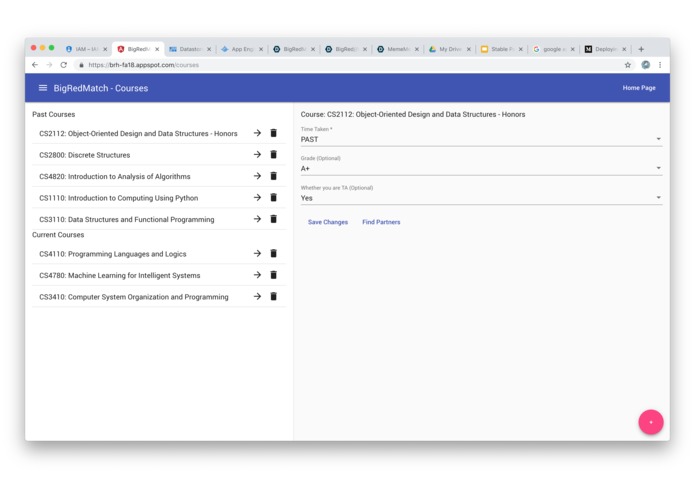
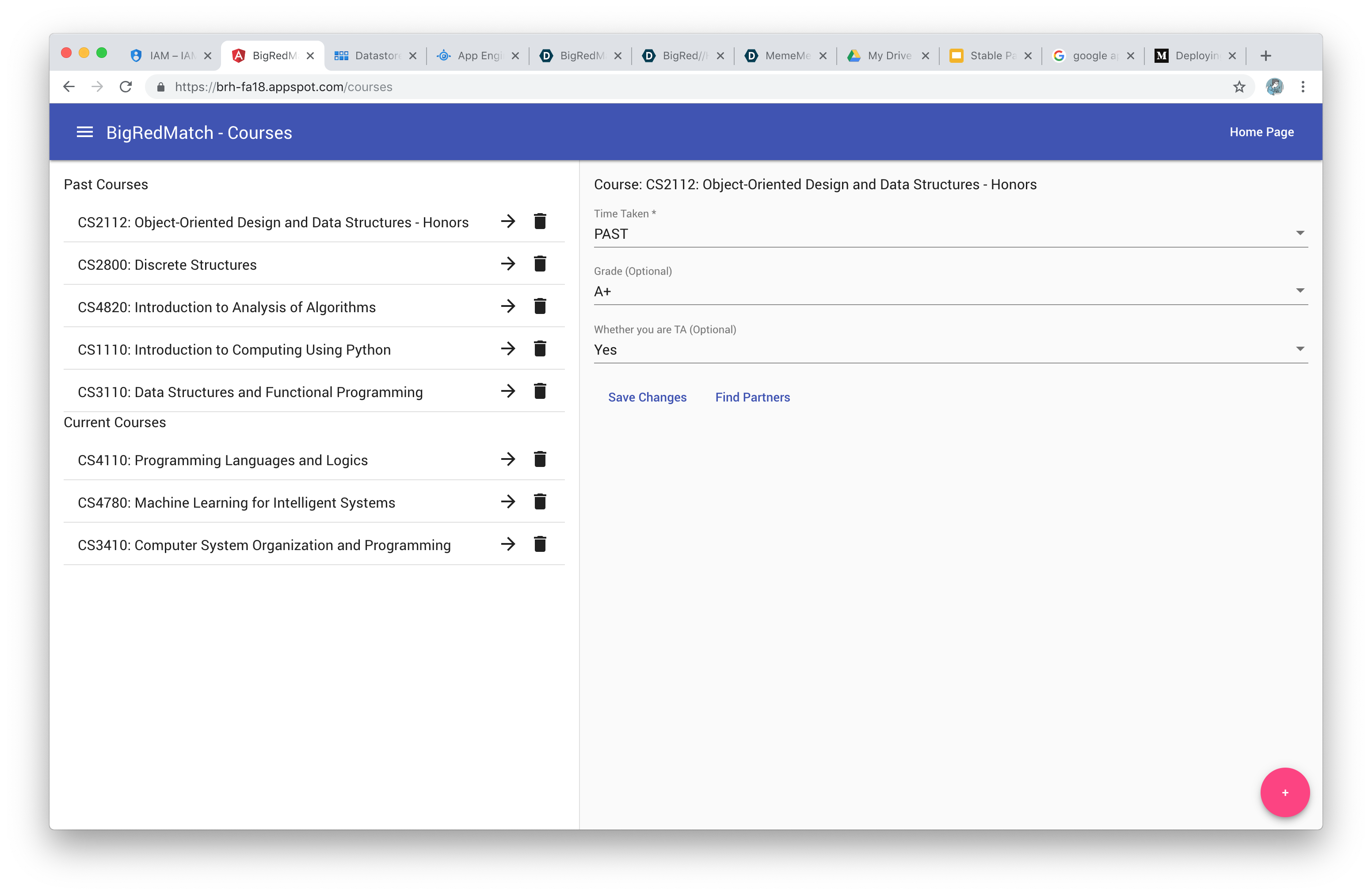
Courses
-
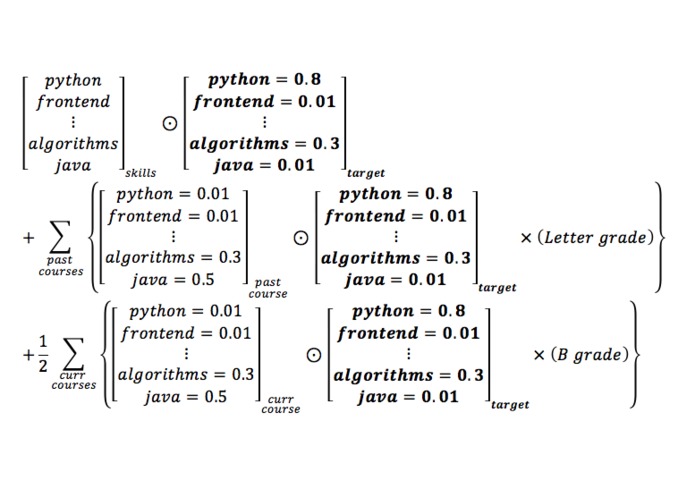
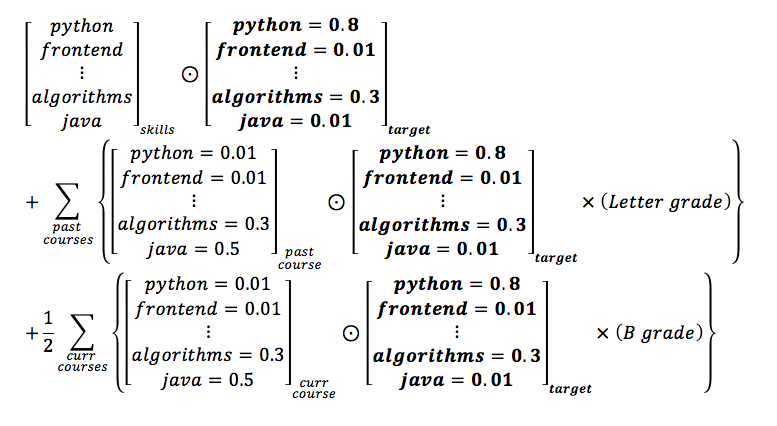
Course-weighted Competence Formula
-
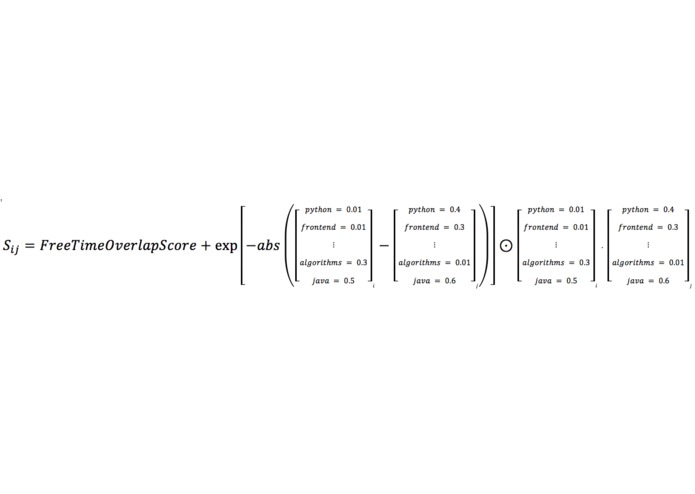
Partner-relative Scoring Formula
-
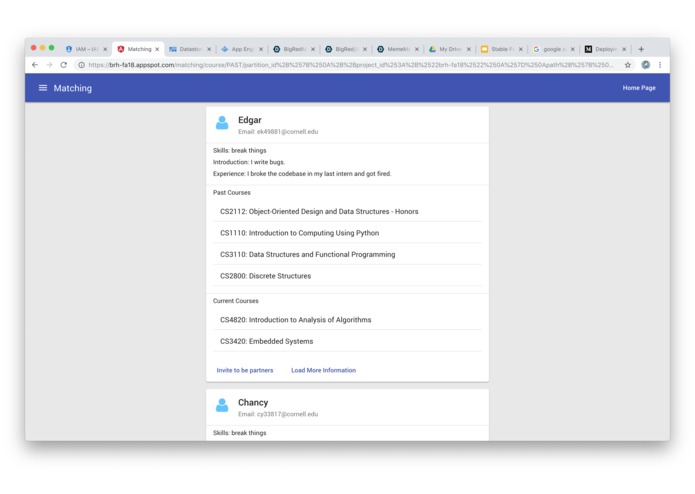
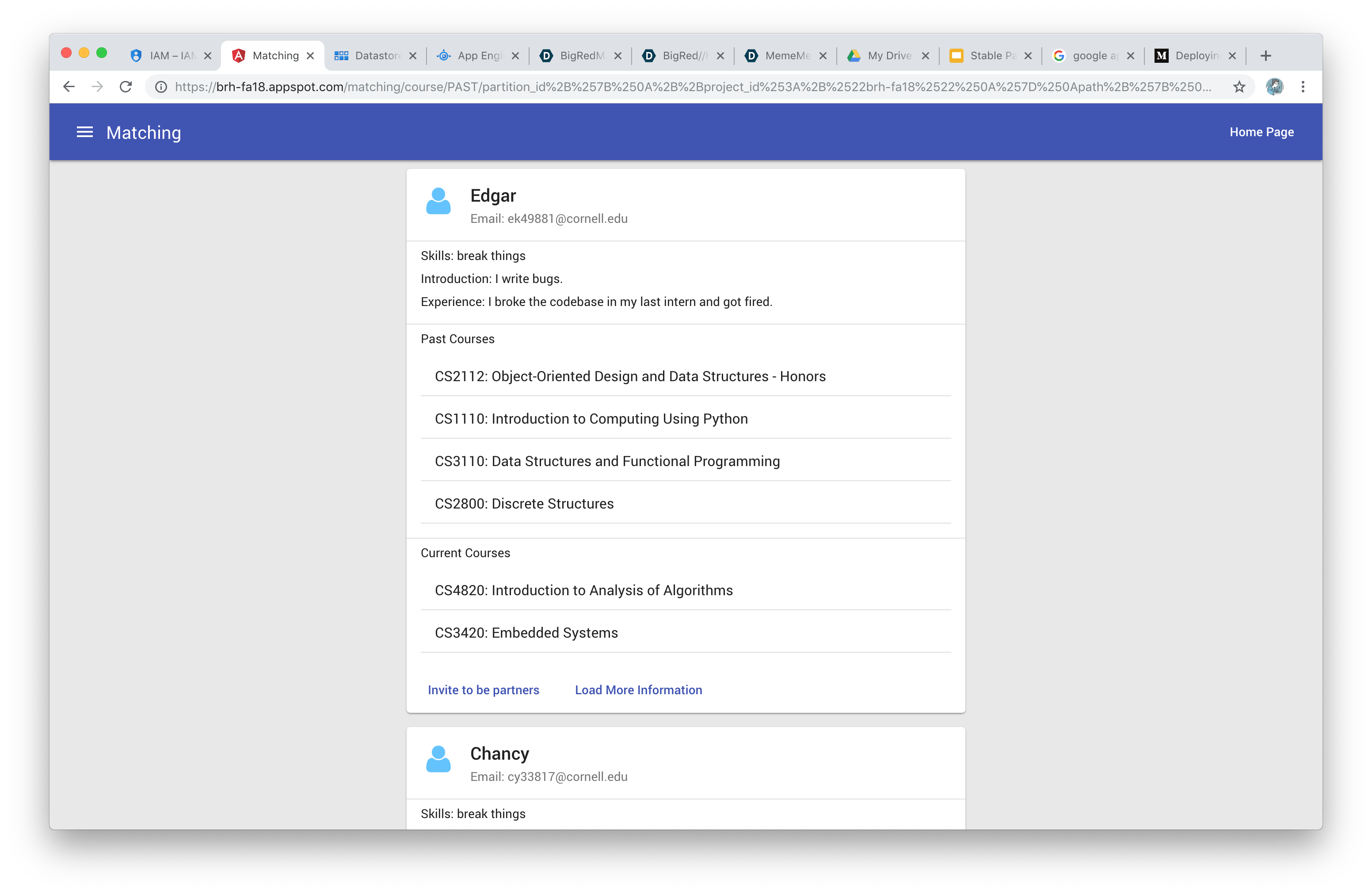
Matchings
-
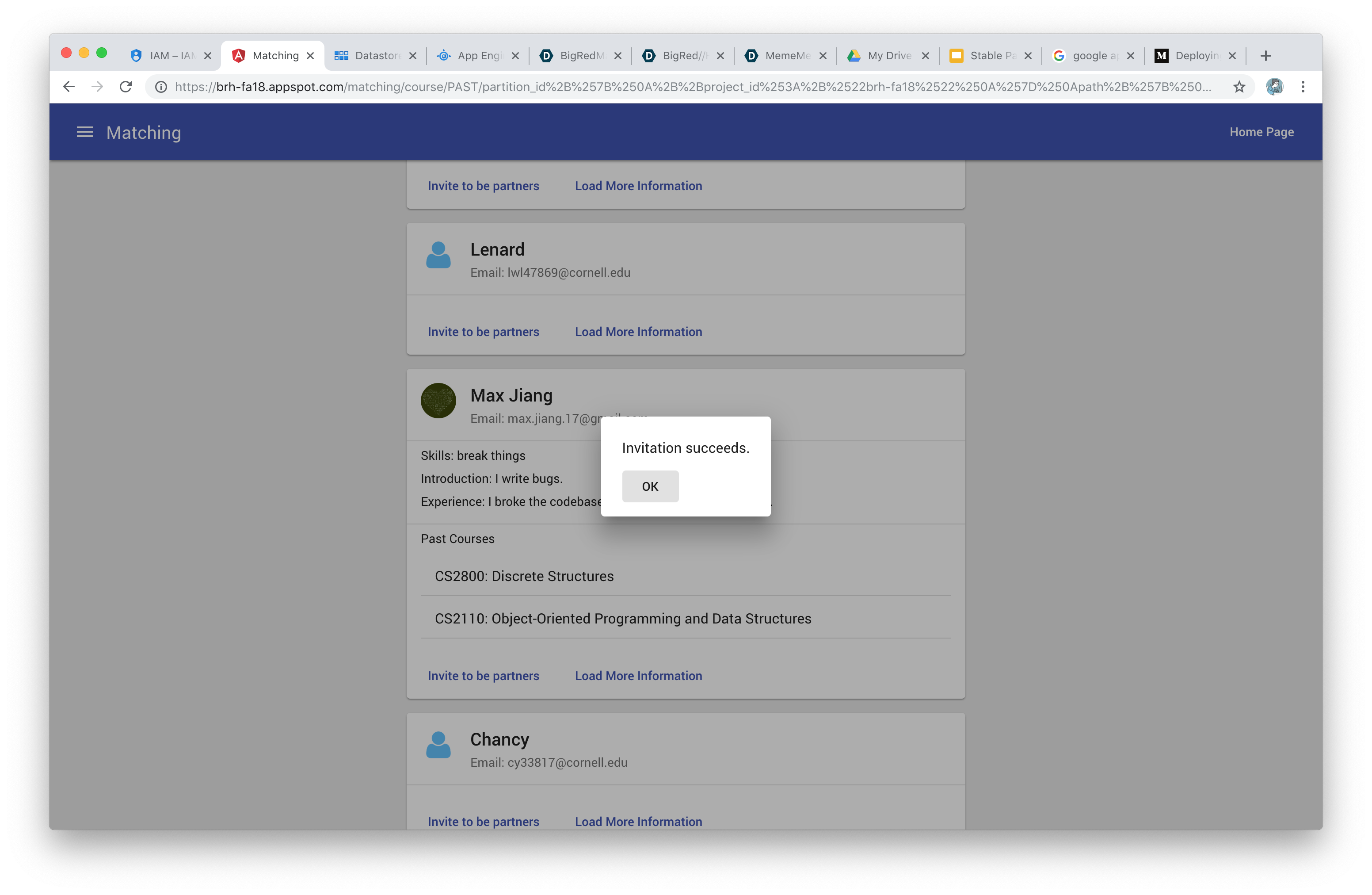
Invitation
-
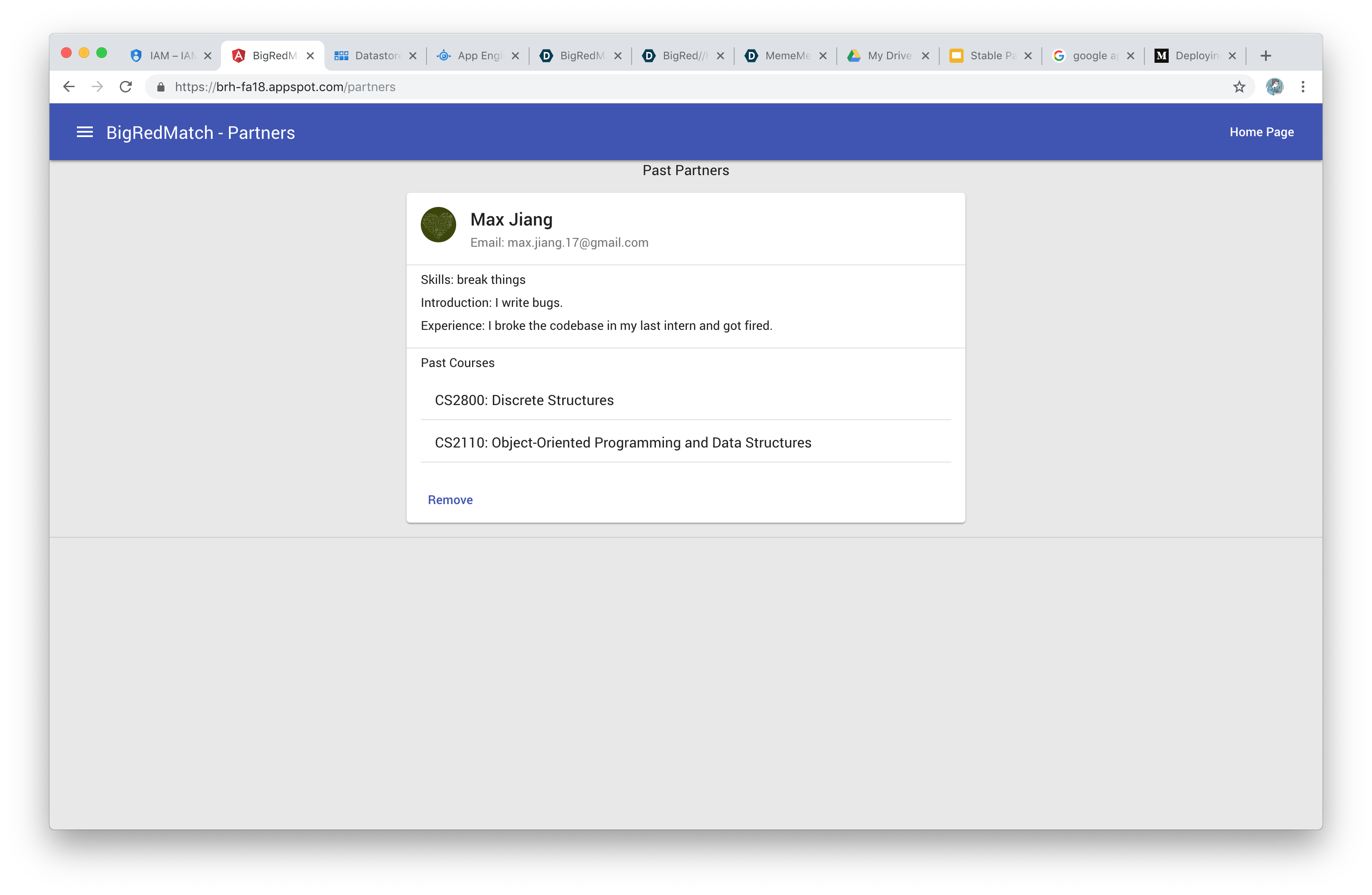
Partners


BigRedMatch
Inspiration
This semester, many CS courses introduced the randomized partner matching system. This was unexpected and chaotic, resulting in many bitter partnership experiences.
We believe randomization does not solve the problem. There should be a much better system than just living with unluckiness during randomization. We built such a system to demonstrate that there exists a better alternative and we welcome feedback on it.
What it Does
The user registers for our service, and provides the following details:
- Basic Profile Information
- Skills, introduction, experience
- Free time slots in schedule
- Past, current, and future courses. The user can also tell us their grade and whether they have TA'ed for those courses.
The user selects a course they are interested in, and our service generates a list of all potential partners sorted in decreasing quality. The user can send invites and form partnerships on our platform.
How We Built It
- Cornell Course API - Fetch Cornell CS course information
- Google NLP API - Extract keywords from course descriptions
- NLTK - Preprocessing the keywords for our weighting algorithm
- Kotlin / Google Cloud Platform - Backend (server application and data storage)
- Firebase Authentication - User identification
- Angular - Front-end User Interface
Challenges we ran into
The weighting of the various factors in the ranking algorithm can only be tested with trial and error, and some time is needed to figure out relatively good weights.
The initial server deployment is slow, and but we found that this was primarily due to expensive database operations involved in our ranking algorithm. We heavily optimized our code to reduce these database operations.
Accomplishments that we're proud of
We now have a fully functional and live system that generates accurate and reasonable rankings of students.
What We Learned
Our ranking algorithm is very complex and required us to change some parameters frequently to evaluate its performance. It would be ideal to have automated tools that conduct such repeated trials for us.
We learned how to build automated tools to pipe together different operations and eventually import the generated weights and class data into the database.
Our ranking system runs just a bit slower than we would like. We learned the hard way that database latency is a real and tricky problem.
What's Next for BigRedMatch
We want to work with the adminstration to improve the product. For example, we can potentially run a stable roommate matching algorithm (since we can algorithmically generate partner preference) to pair leftover students, and make everyone happy with their partners!
Also, if the adminstration can give our some API support, then we do not need to store students' grades, which is better privacy practice.
Build and Deploy the Project
Build and deployed by build.sh.
Built With
- css
- dockerfile
- html
- java
- javascript
- jupyter-notebook
- kotlin
- python
- shell
- typescript








Log in or sign up for Devpost to join the conversation.