-
-
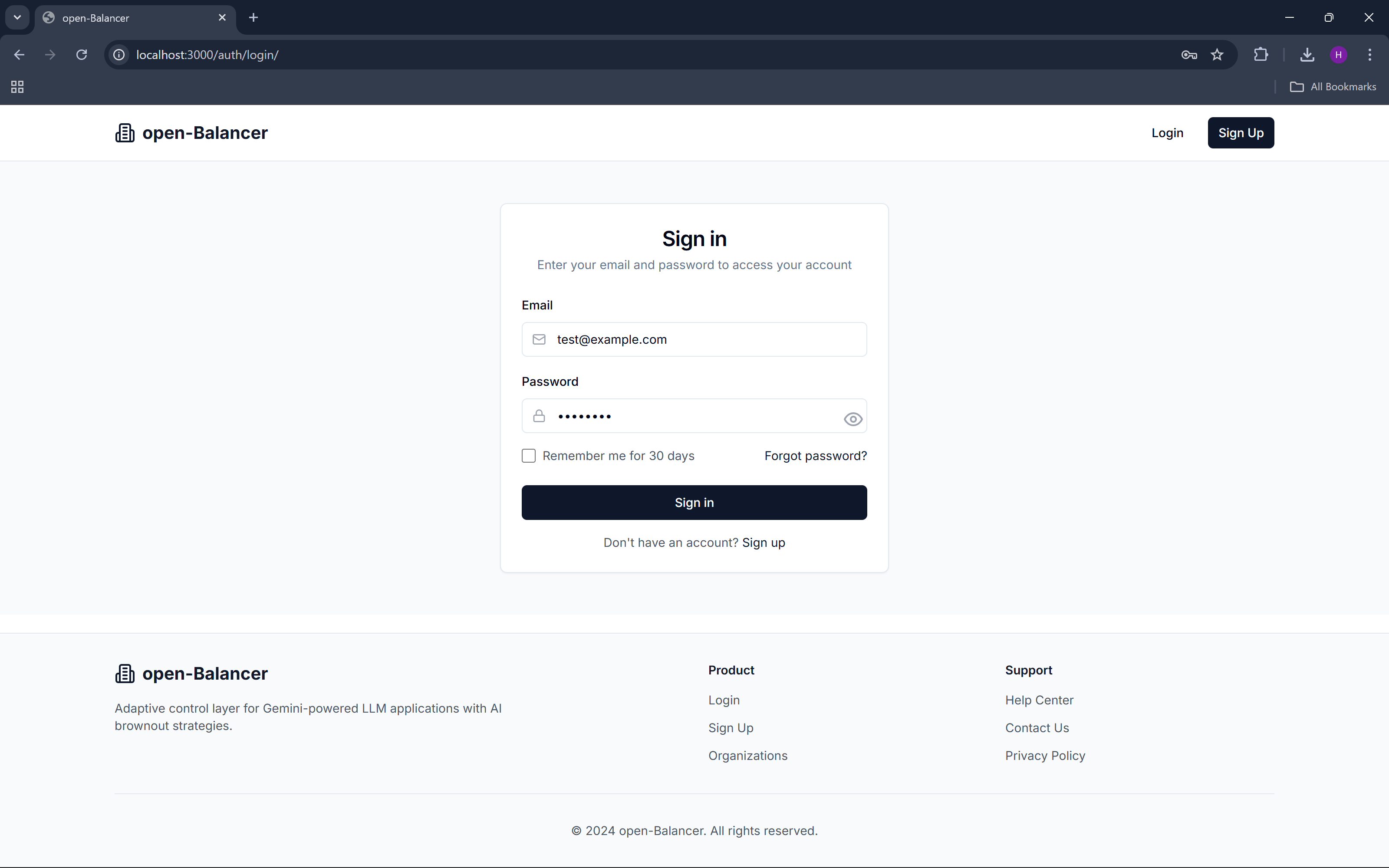
login
-
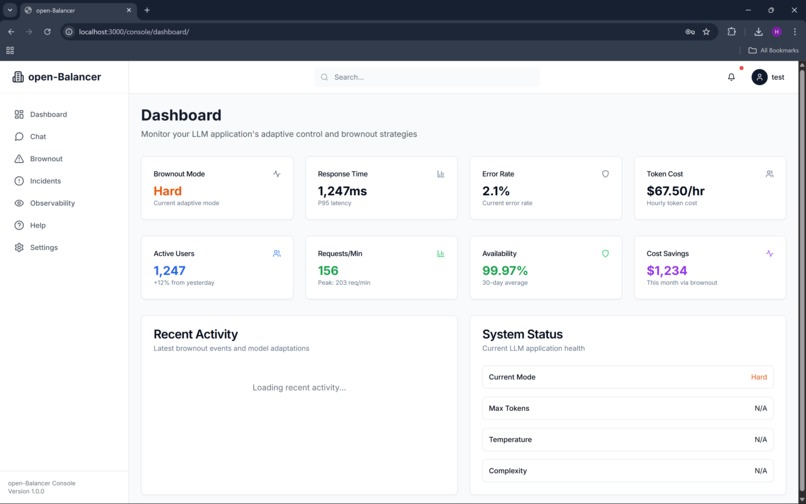
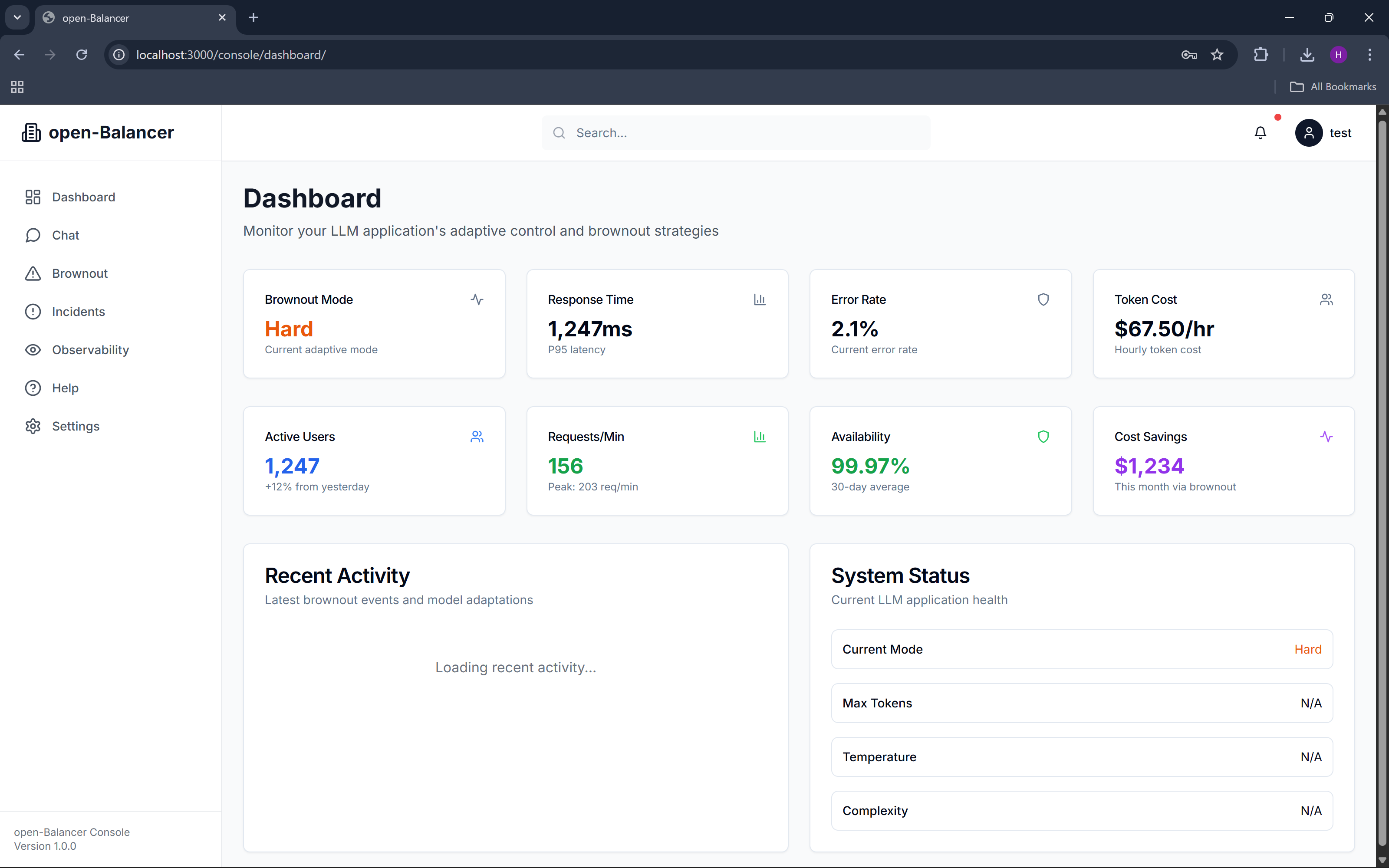
dashboard
-
settings
-
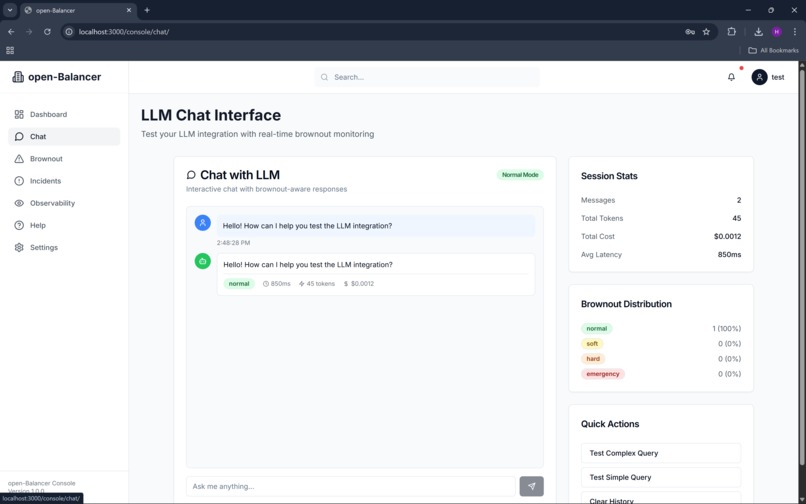
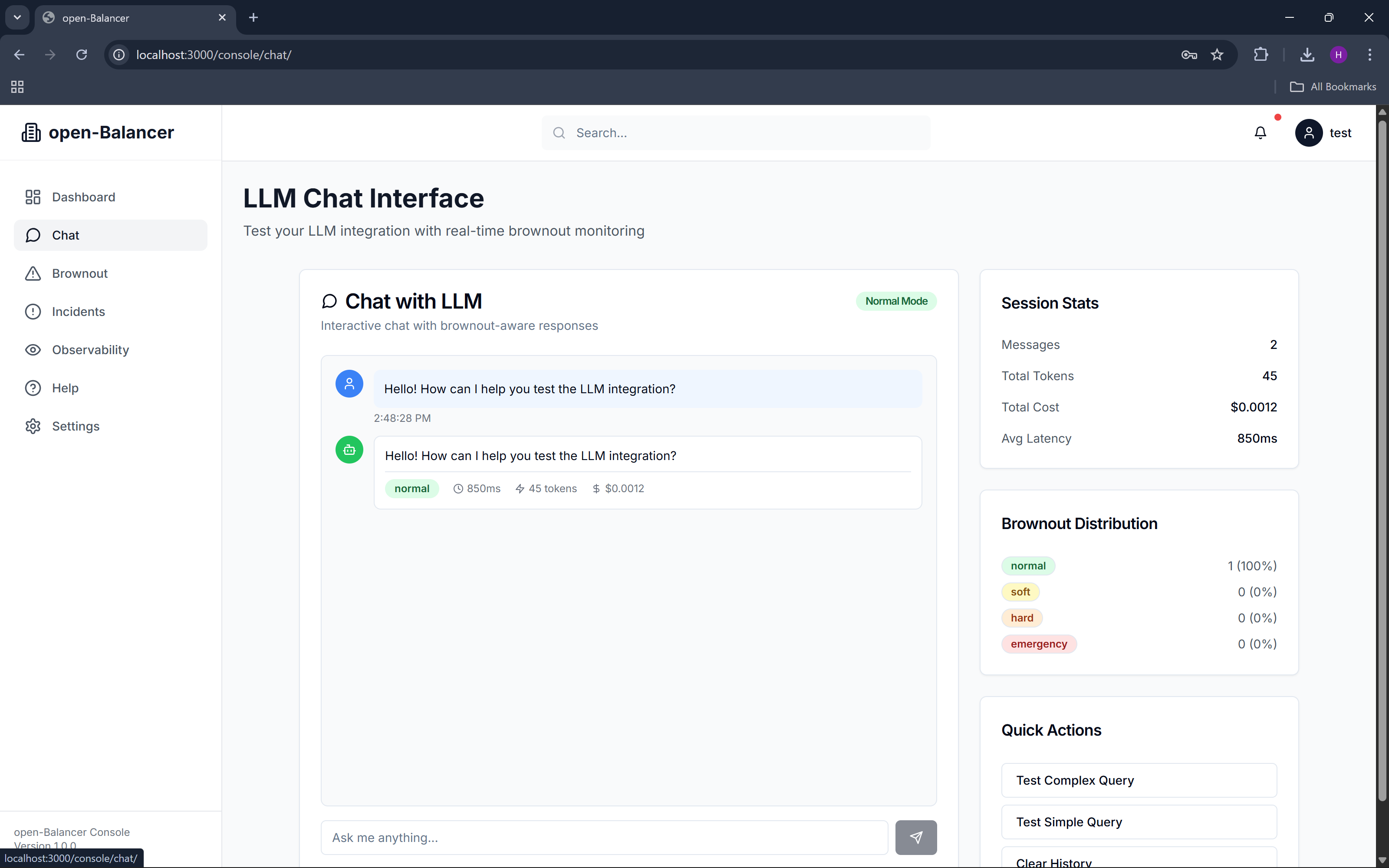
chat
-
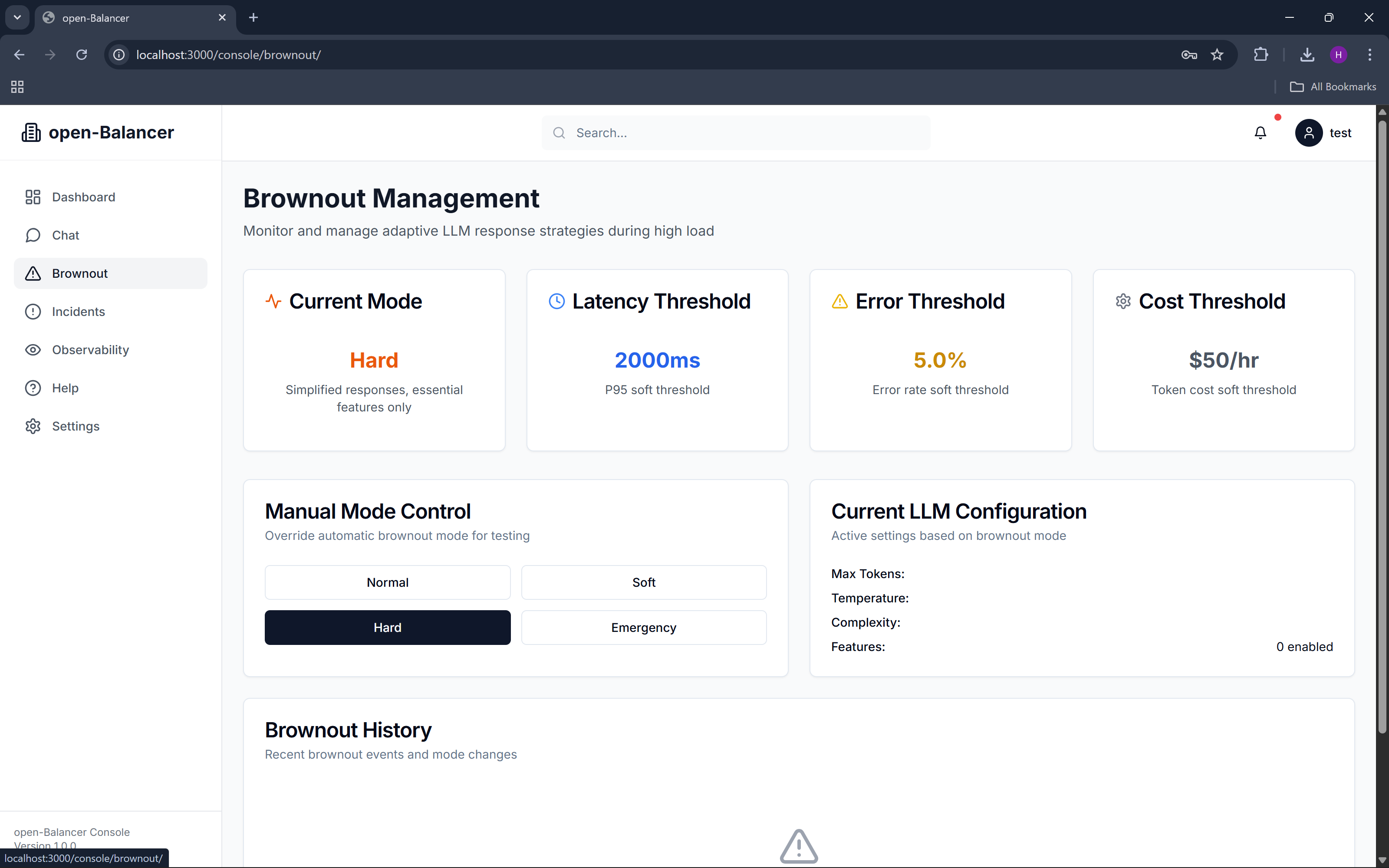
brownout
-
help
-
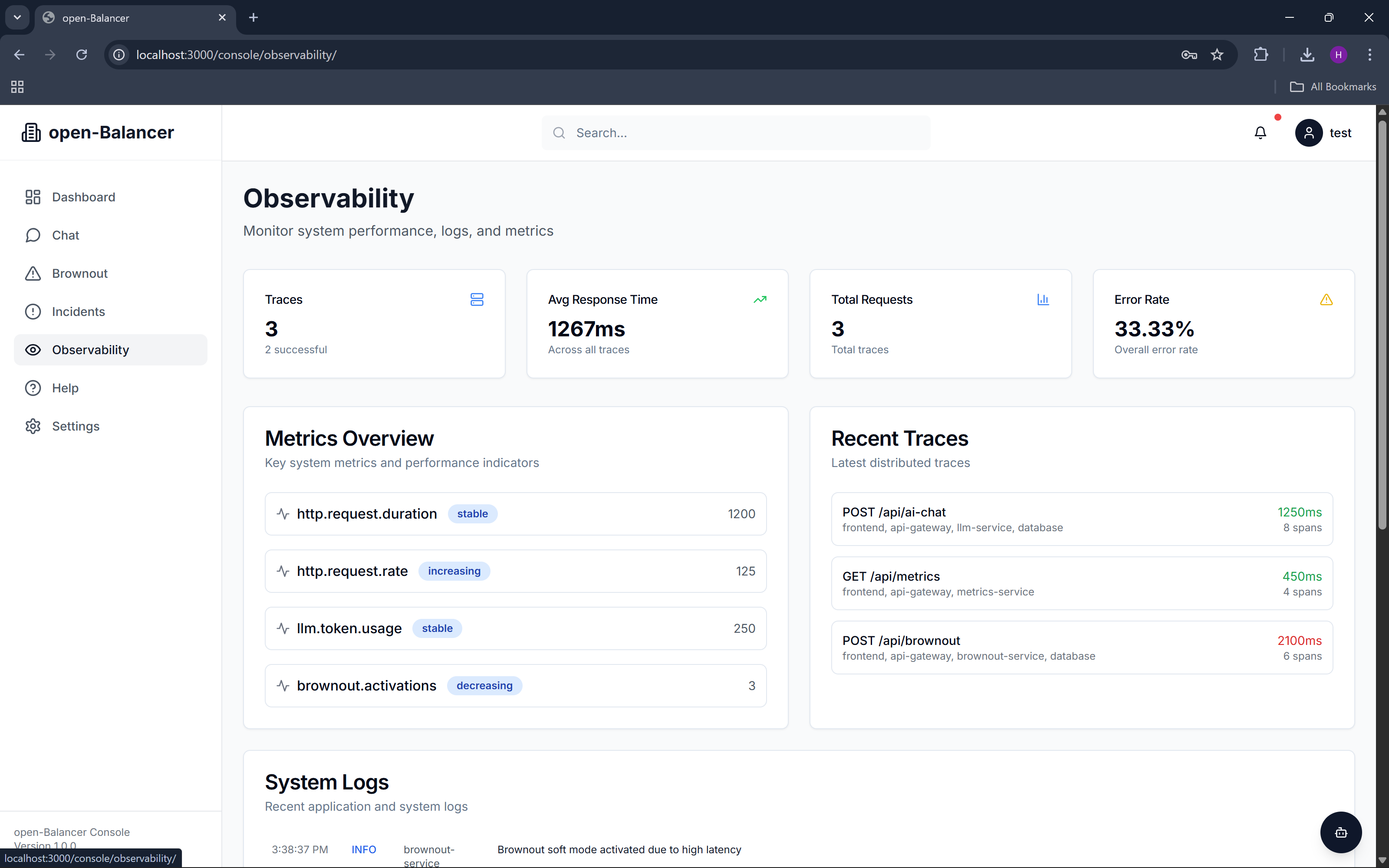
observability
-
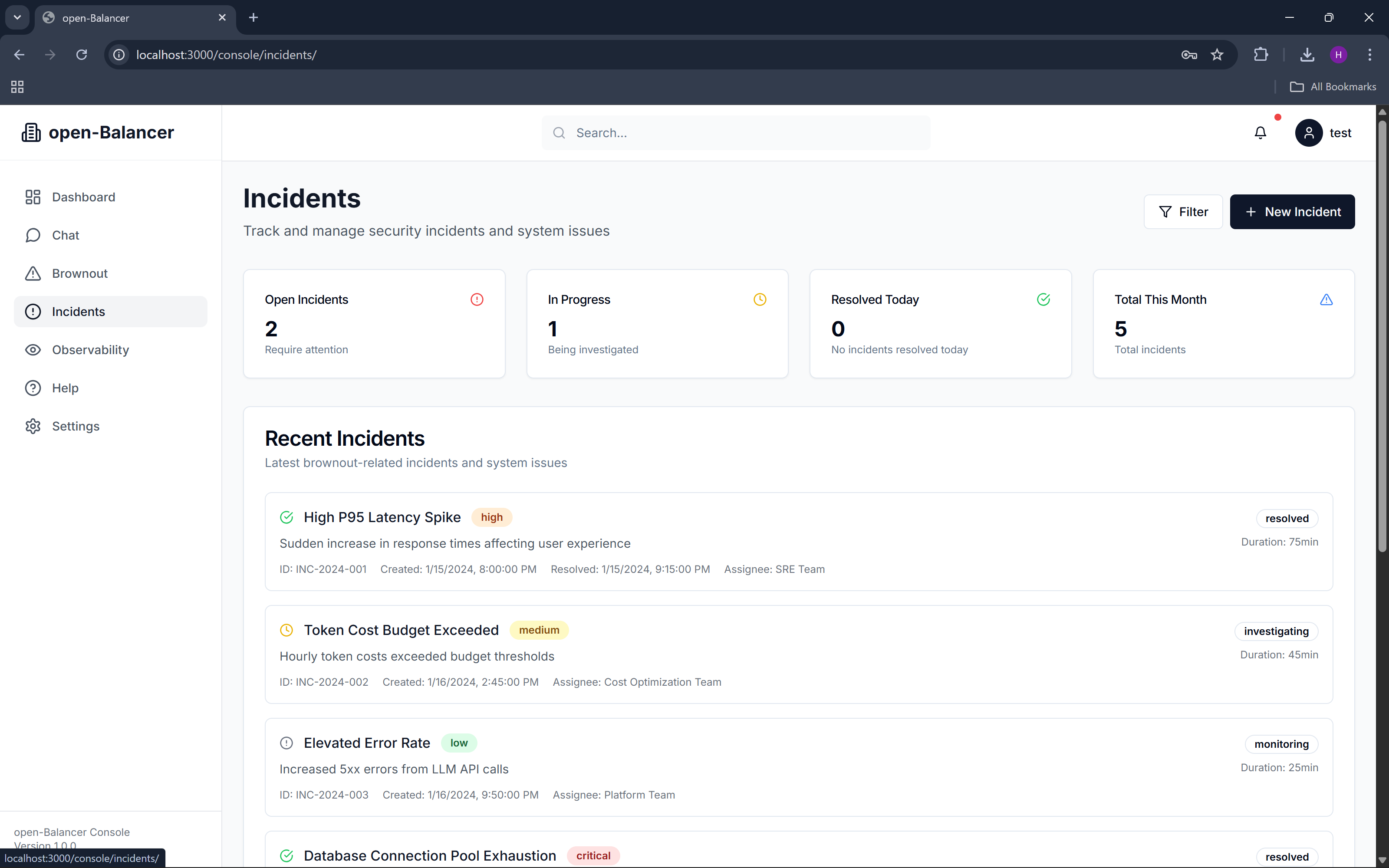
incidents
Inspiration
As large language models move from experiments into production systems, we noticed a recurring failure pattern: when LLM applications are stressed by high traffic, latency spikes, or unexpected cost growth, they tend to fail abruptly. Traditional SRE systems rarely shut down completely under load—instead, they degrade gracefully using brownouts.
The inspiration for open-Balancer came from applying these proven SRE principles to AI systems. Rather than treating LLMs as all-or-nothing components, we wanted to explore how real-time observability could actively control AI behavior, keeping applications usable, predictable, and cost-aware even under stress.
What it does
open-Balancer is an open-source adaptive control layer for Gemini-powered LLM applications. It continuously observes application health using Datadog signals—such as latency, error rate, and token cost—and automatically adjusts LLM behavior through predefined brownout modes.
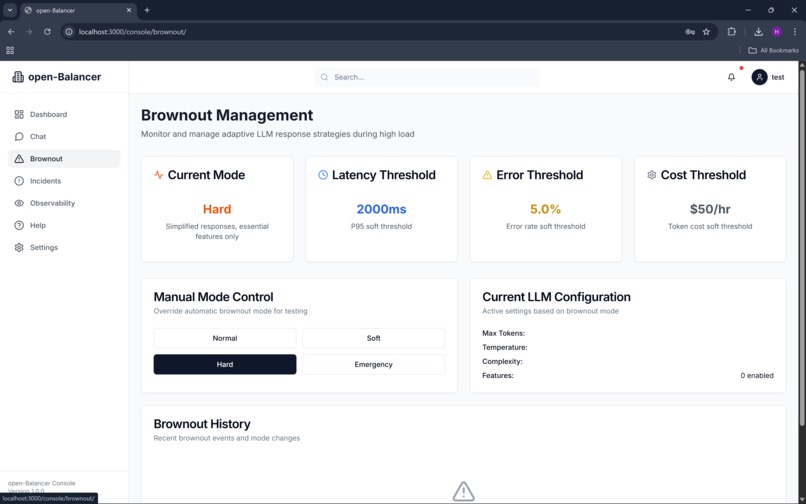
When conditions are healthy, the application operates normally. As stress increases, open-Balancer progressively reduces response complexity, limits token usage, and prioritizes reliability over richness. Instead of crashing or timing out, the application stays responsive and transparent about its degraded state.
In short, open-Balancer turns observability into action.
How we built it
The system is built on Google Cloud Run with Gemini via Vertex AI as the LLM backend. A FastAPI service handles request routing, brownout decision logic, and LLM invocation.
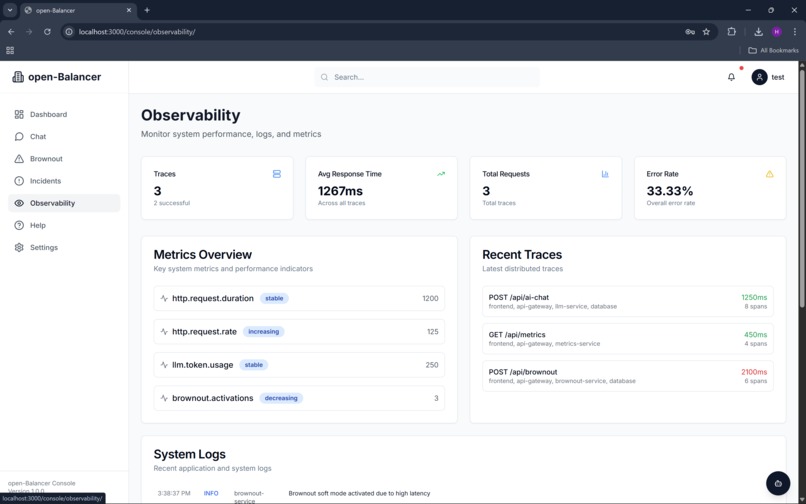
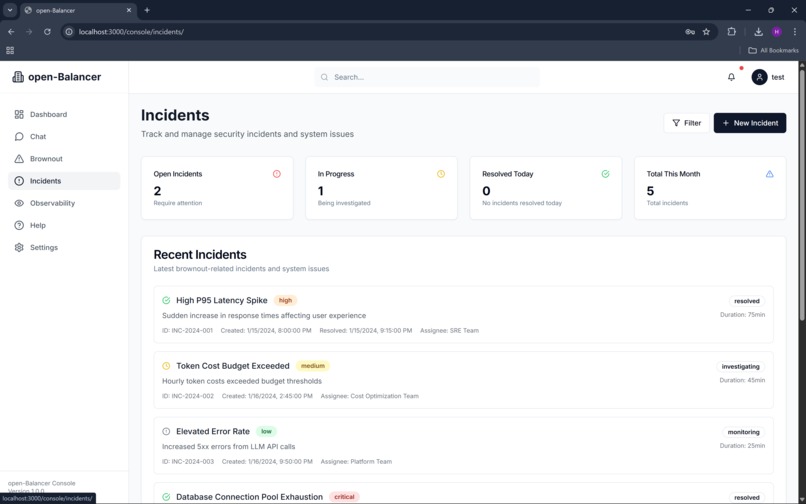
We instrumented the backend using OpenTelemetry, exporting traces, logs, and custom metrics directly to Datadog using Datadog’s OTLP ingest endpoint. Datadog monitors evaluate real runtime signals and automatically create incidents when thresholds are crossed. These incidents feed back into open-Balancer, triggering transitions between brownout modes.
A lightweight Next.js console provides visibility into system health, current brownout state, incidents, and test interactions, while Datadog remains the single source of truth for observability, alerts, and dashboards.
Challenges we ran into
One of the main challenges was deciding what to measure and when to act. Too many metrics create noise; too few reduce confidence. Finding the right balance between latency, error rate, and cost signals required iteration and experimentation.
Another challenge was keeping the system simple while still production-realistic. It was tempting to add complex configuration, multi-model support, or heavy UI analytics, but we intentionally avoided these to stay aligned with hackathon rules and focus on observability-driven control.
Finally, designing brownout behavior that felt useful—not arbitrary—required careful tuning so that degraded responses were still helpful rather than confusing.
Accomplishments that we're proud of
- Successfully applied SRE brownout principles to LLM applications
- Built a real feedback loop where Datadog incidents directly influence application behavior
- Implemented custom LLM cost and brownout metrics instead of relying on placeholders
- Delivered a clean, production-style architecture that is easy to reason about
- Kept the system minimal, open-source, and fully compliant with hackathon rules
What we learned
We learned that observability is far more powerful when it drives action, not just dashboards. By treating LLM behavior as something that can be dynamically controlled, reliability and cost management become first-class features instead of afterthoughts.
We also learned that simplicity is a strength in hackathon projects. Clear intent, realistic architecture, and honest trade-offs resonate more with judges than overengineered solutions.
Most importantly, this project reinforced that AI systems benefit greatly from established SRE practices—AI reliability is still reliability engineering.
What's next for open-Balancer
Future work could explore more advanced brownout strategies, such as user-aware degradation, workload prioritization, or policy-based controls. Additional integrations—like notification workflows or richer incident context—could further tighten the loop between detection and response.
Beyond this hackathon, open-Balancer represents a direction for building safer, more predictable AI systems by design, where failure is managed gracefully rather than avoided at all costs.
Built With
- cloudrun
- datadog
- docker
- fastapi
- gemini
- github
- google-cloud
- javascript
- lucide-react
- next.js
- opentelemetry
- python
- react
- shadcn/ui
- tailwindcss
- vertexai


Log in or sign up for Devpost to join the conversation.