-
-
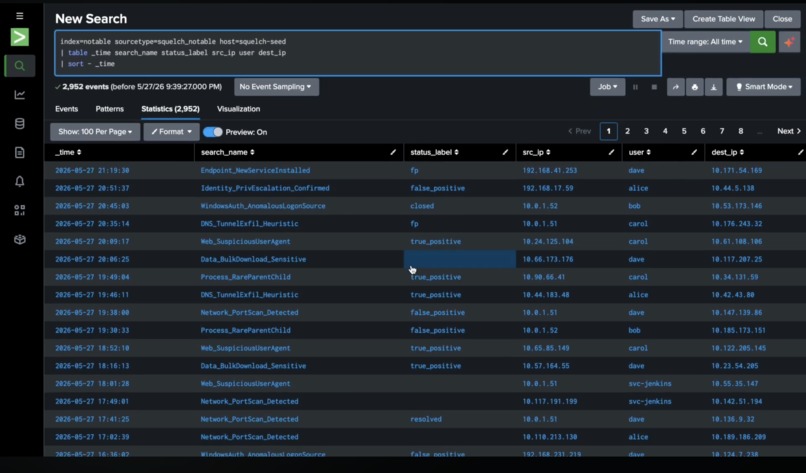
SOC data: six label formats, 20% unlabeled — the conditions Squelch was designed for.
-
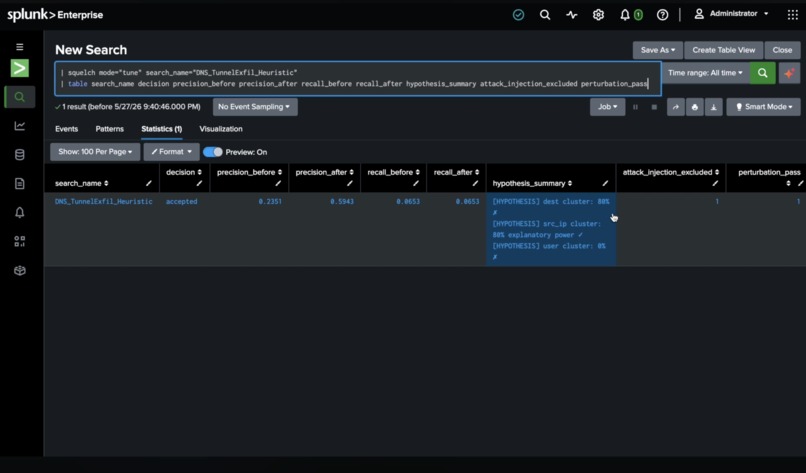
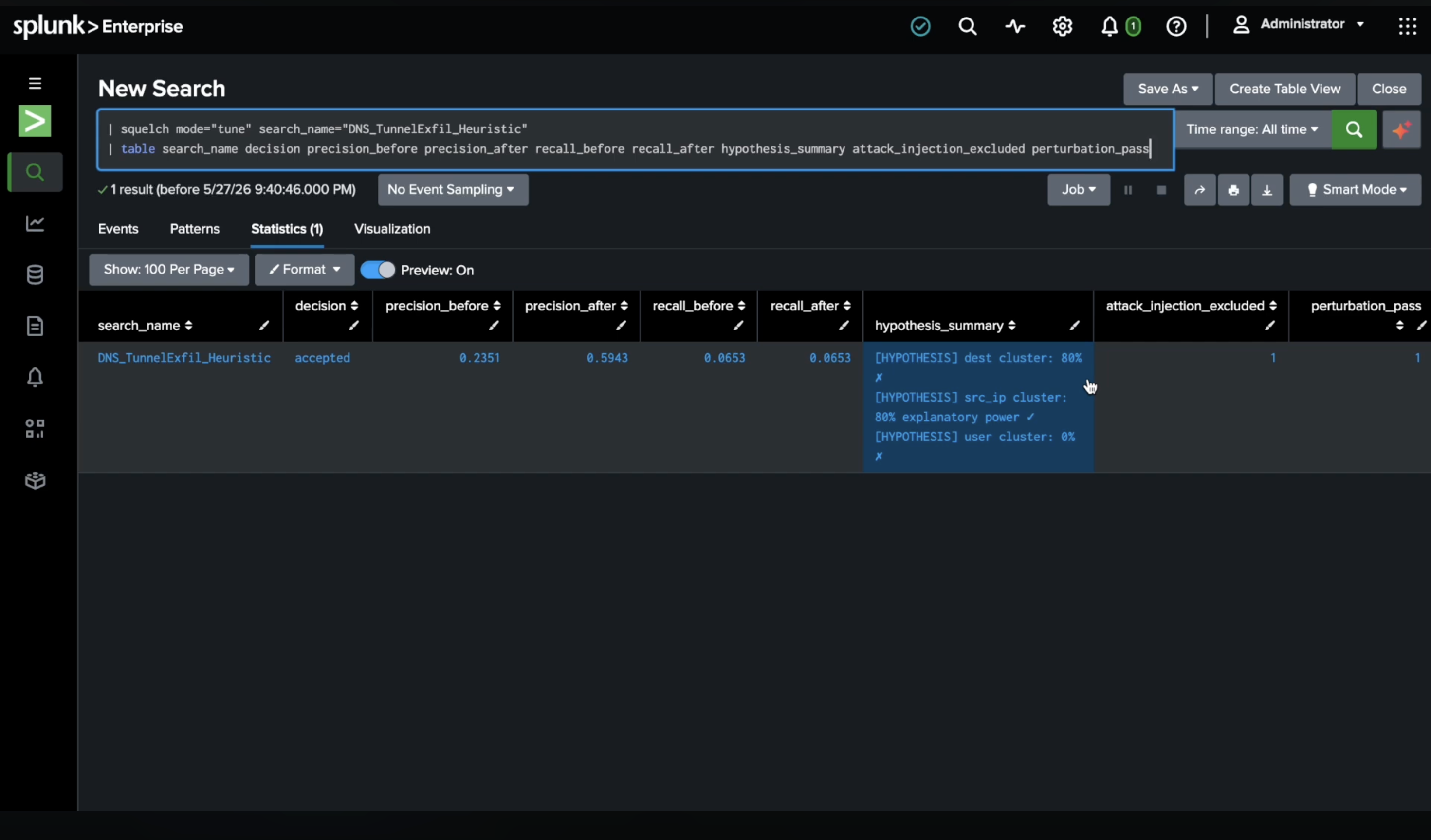
hree hypotheses tested, one wins. Attack injection excluded an unsafe IP. Precision: 24% → 59%
-
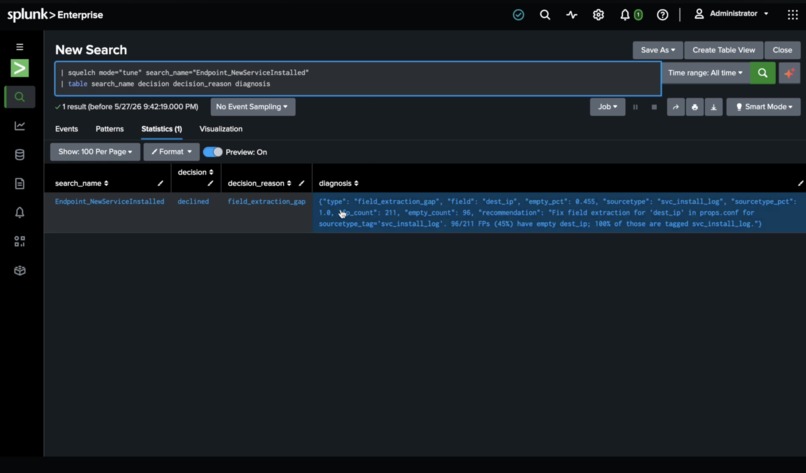
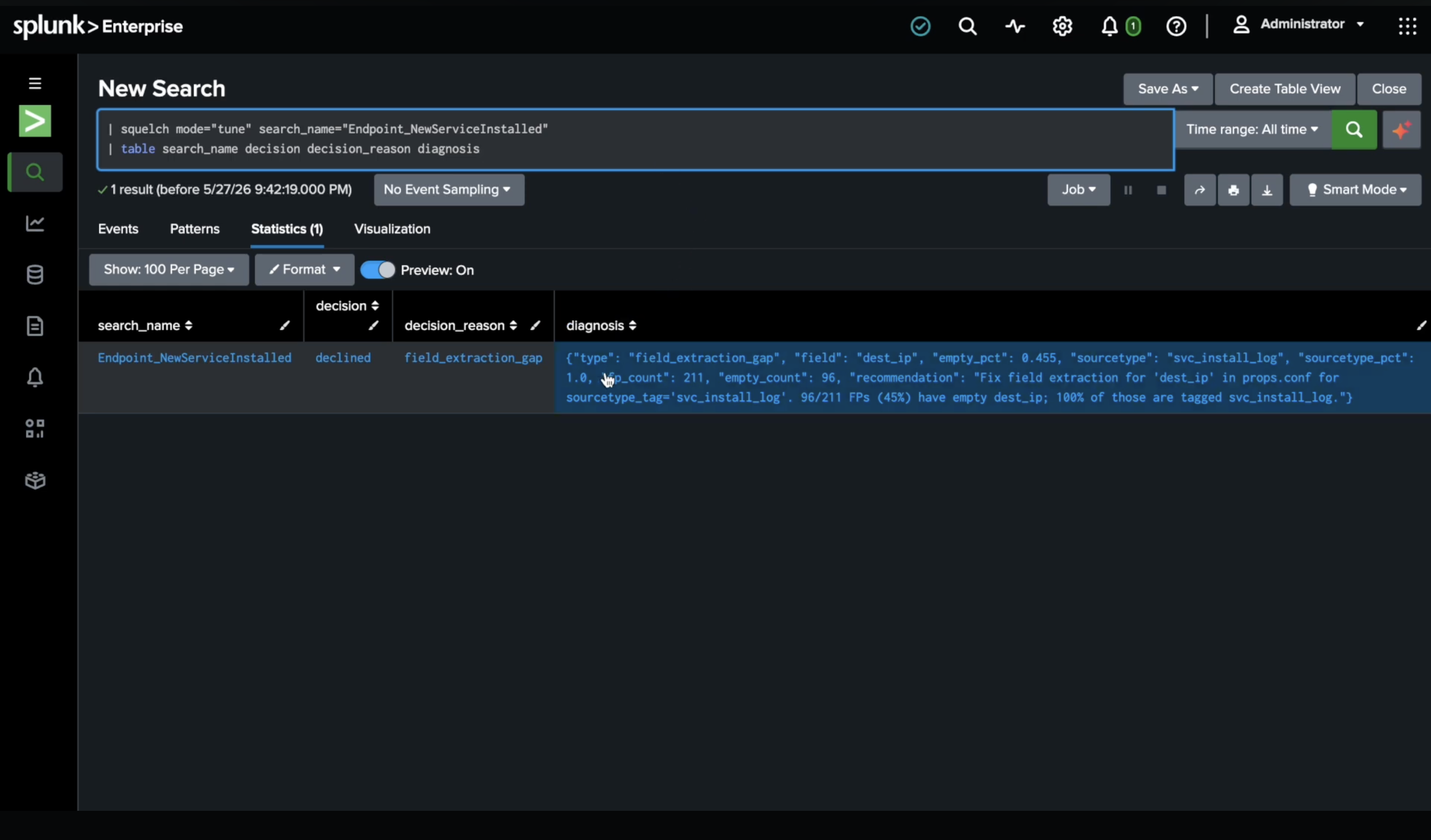
Squelch declined to tune — 45.5% empty dest_ip from one sourcetype. Filed a diagnosis, not a filter
-
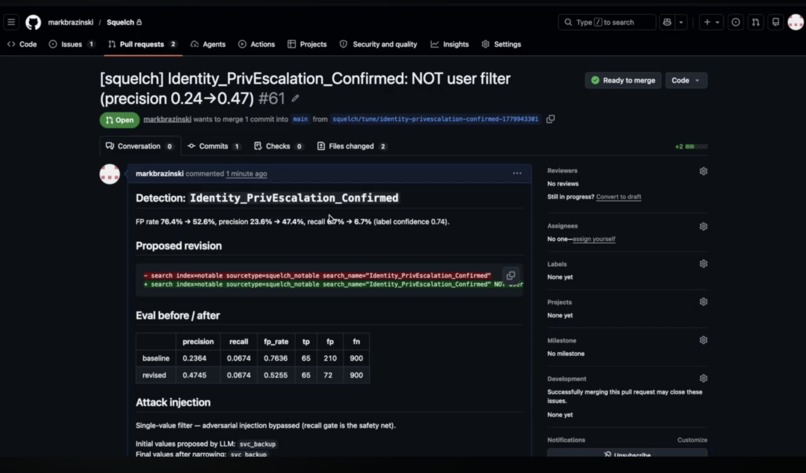
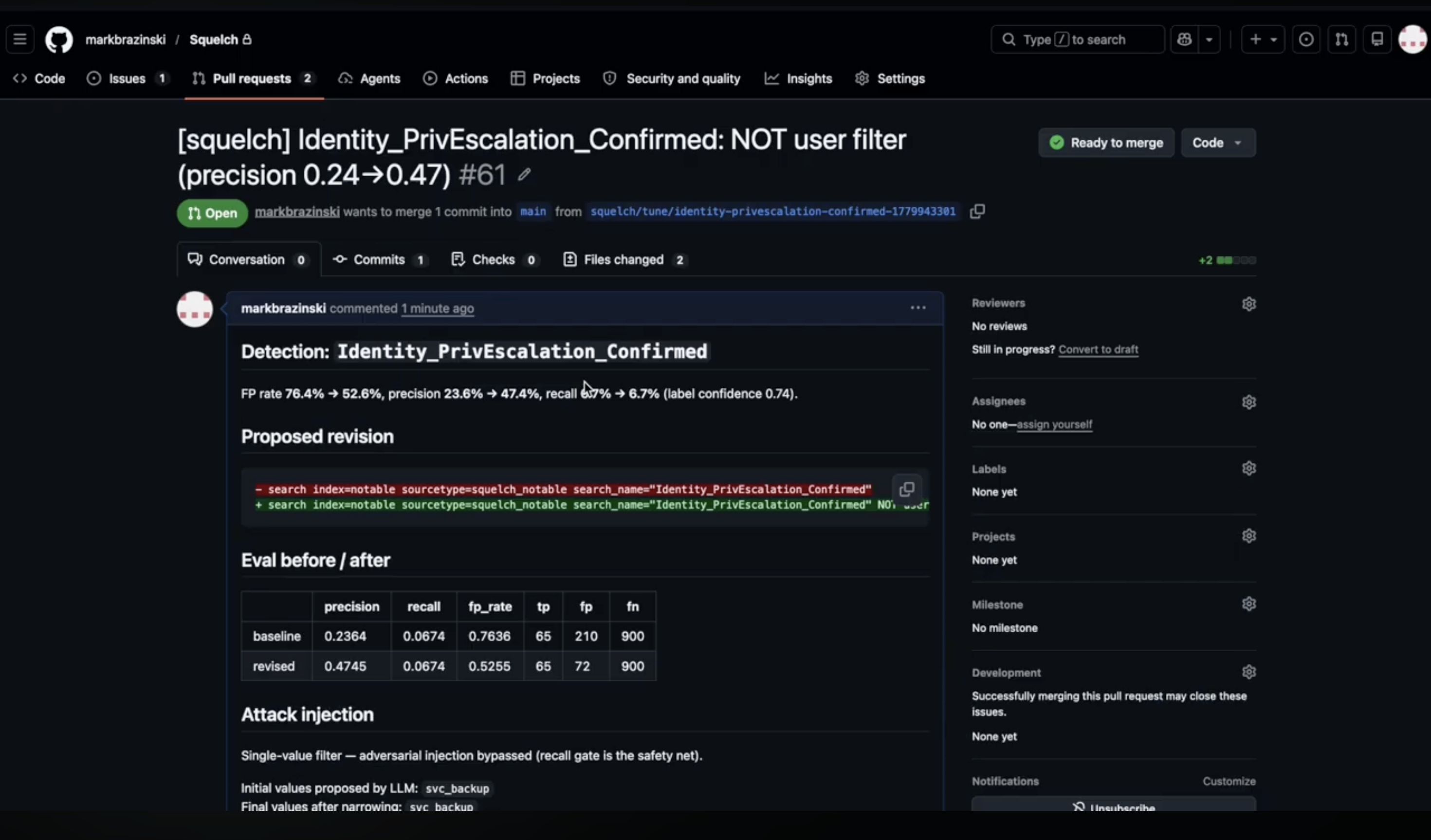
The PR the engineer reviews Monday: SPL diff, eval before/after, attack injection results.
-
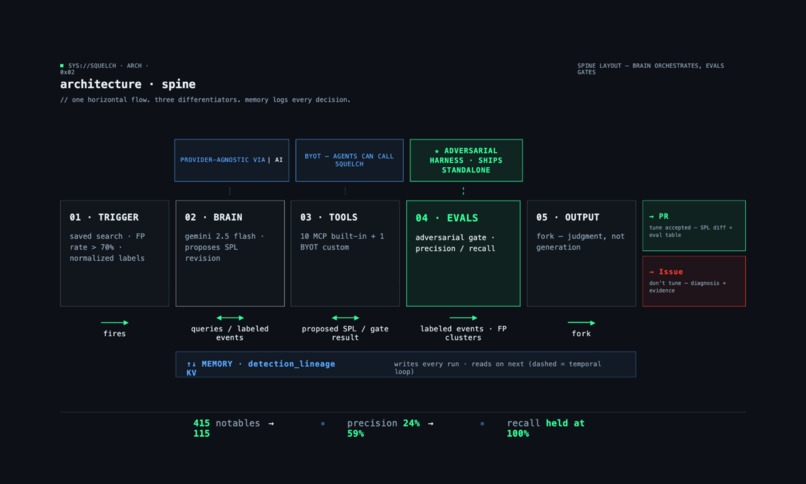
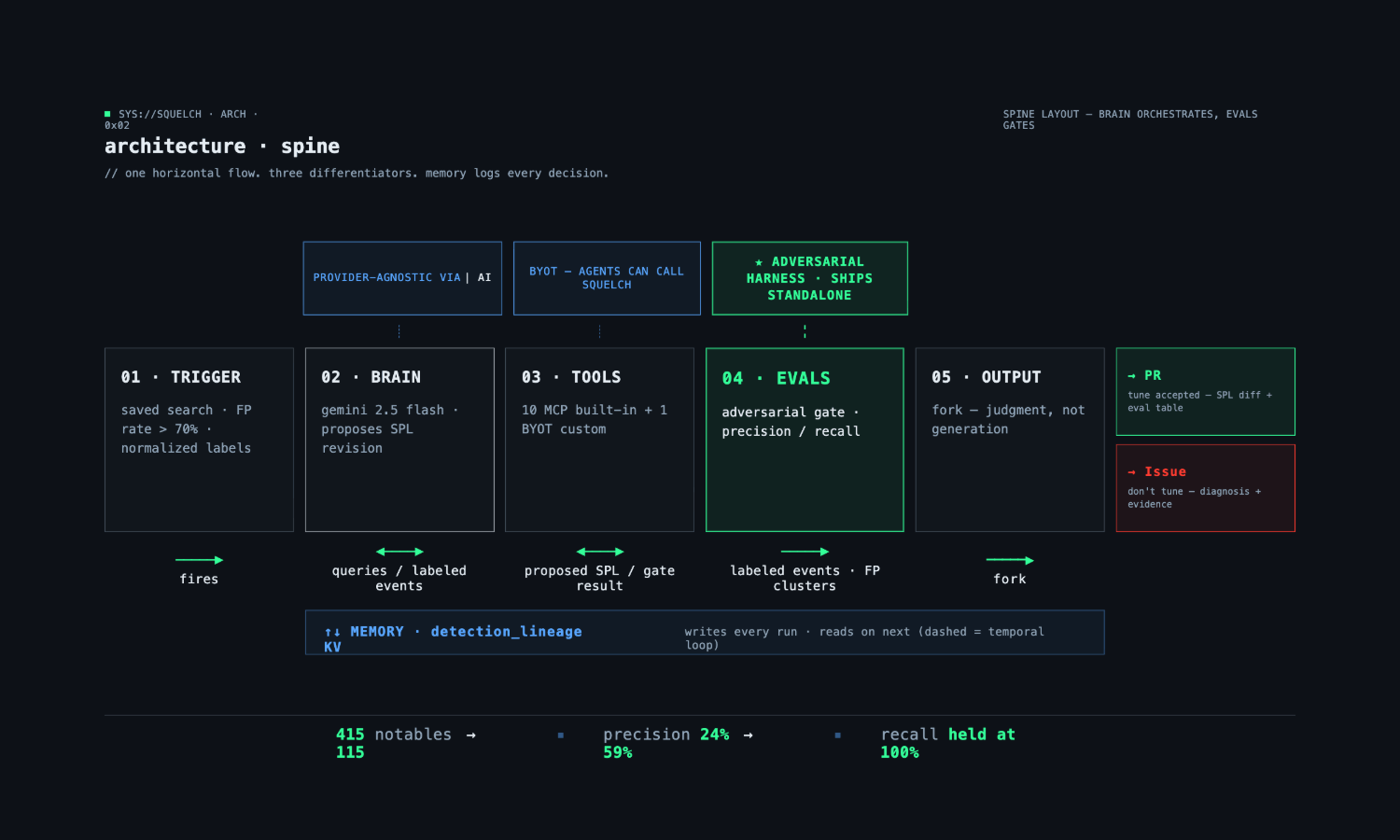
Full stack: trigger → LLM → MCP tools → adversarial eval harness → KV store → Git output.
Squelch
Adversarial eval harness for Splunk detection logic. Track: Security. Repo: github.com/markbrazinski/Squelch (MIT).
Inspiration
SIEM engineers carry tuning backlogs that grow faster than they shrink. A noisy correlation search generates hundreds of false positives per day, and the analyst on the other end stops reading those alerts. The engineer who wrote the rule knows it. But tuning a single rule properly takes three to five hours of manual investigation — querying notables, pivoting across fields, guessing at the pattern — and there's no way to validate the result. No precision score. No recall score. Just an eyeball check and a hope that you didn't quietly start dropping true positives behind a dashboard that still shows green.
Every AI demo I watched this year showed the LLM doing the hard part — generating queries, summarizing incidents, triaging alerts. But nobody was building the thing that proves the LLM's output is safe. The generation is easy. A NOT filter is one line of SPL. The hard part is: did that filter just hide a real attack? Did it overfit to a transient pattern? Would it survive if 10% of your labels were wrong?
That's where Squelch started. Not as a tuning tool — as a validation harness that happens to tune.
What it does
Every AI-Splunk tool generates SPL. Squelch is the only one that adversarially proves it's safe — and refuses to tune when the real problem is data quality.
Squelch is an adversarial eval harness for Splunk detection logic, delivered as a Splunk App. The user runs | squelch mode="tune" in the Splunk search bar, and the pipeline runs end-to-end: cluster FPs, propose a filter, attack the proposal, gate on recall, and deliver results as a GitHub PR or Issue. No dashboard, no chat interface — the outputs are PR diffs and eval tables that engineers review in their existing workflow.
The eval harness also ships standalone: | squelch mode="eval" runs precision, recall, perturbation, and holdout against any detection — no clustering, no LLM, no GitHub. Install it Monday, even if you never run the agent.
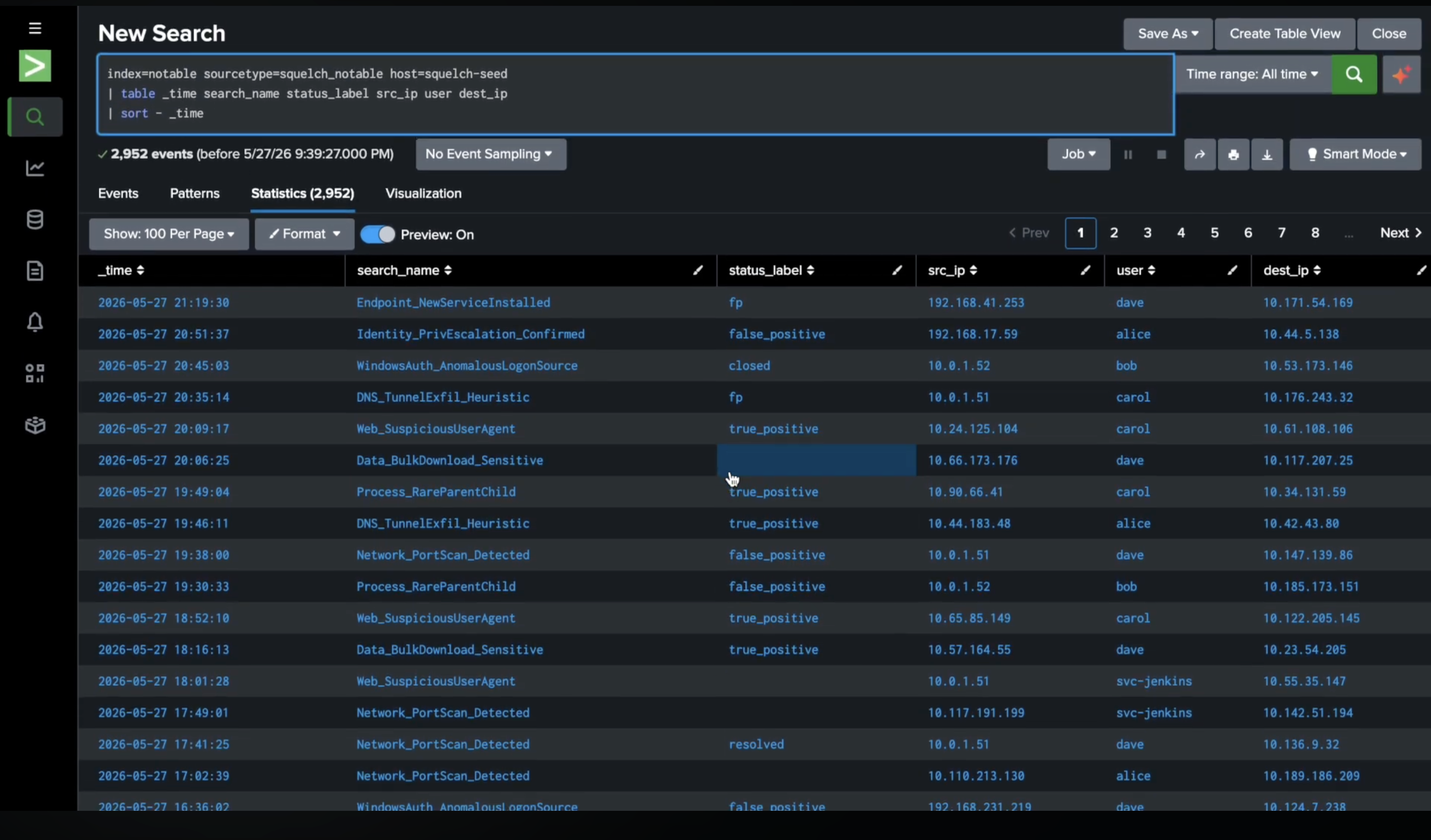
We validated Squelch against BOTSv3 — Splunk's public attack simulation dataset. Data we didn't author, labels from the published attack scenario (coinhive cryptominer domains = true positive). Two detections, 17,684 events, two contrasting outcomes:
Detection 1: DNS — Filtered (PR #70)
10,257 events. 21 true positives. 10,236 false positives. Baseline FP rate: 99.8%.
The pipeline:
Clustered false positives across multiple fields and ranked each as a filter hypothesis. Source IP explained 80% of the noise — the winning cluster.
Proposed a NOT filter using Gemini 2.5 Flash. The LLM wrote one line of SPL. That's its entire contribution: 9 IPs in a NOT clause.
Attacked its own proposal by injecting synthetic true positives matching each filtered IP. One IP —
172.16.0.13— was carrying real threat traffic. The harness caught it and excluded it automatically. 9 proposed, 8 shipped. Shipping all 9 would have dropped real threats.Gated on recall — hard veto. The proposed revision preserved all 21 true positives. Recall: 1.000.
Ran label perturbation — flipped 10% of labels across seeded trials. Result: WARN (21 TPs is too small a population for a meaningful flip test — honest reporting, not a suppressed failure).
Ran temporal holdout — split the data 70/30 by time and verified the filter generalizes. Result: PASS.
Shipped as PR #70 with the SPL diff, eval before/after table, attack injection results, cluster analysis, perturbation badge, and temporal holdout numbers. False positives: 10,236 → 2,726. 73% fewer false-positive events, all 21 threats preserved.
Detection 2: Endpoint — Declined (Issue #71)
7,427 events. Baseline precision: 54.2%. The pipeline started — then stopped.
Squelch tried to cluster the false positives. Every field was empty. src_ip: 0% populated. dest: 0% populated. user: 0% populated. Sourcetype: wineventlog:security — the fields were never extracted.
No field cluster cleared the explanatory power floor. The agent diagnosed a field extraction gap: fix src_ip extraction in props.conf for wineventlog:security. Instead of applying a filter that would mask the real problem, it filed a GitHub Issue with the diagnosis and evidence.
The worst thing a tuning system can do is mask a data quality problem with a filter. Squelch declined to tune.
Perturbation: PASS. Temporal holdout: PASS. The eval harness validated the baseline even when it declined to act.
How we built it
Architecture: Squelch is a native Splunk App — commands.conf registers a chunked Python streaming command (| squelch) that dispatches across five modes: test, tune, validate, llm_probe, and eval. The eval library (eval_lib.py, cluster.py, attack_inject.py, revise.py, github_integration.py) lives in the repo at eval/ and is vendored into the Splunk App at bin/lib/squelch_eval/. Every edit to eval/ gets mirrored to the vendored path; diffs must be empty after every session.
Trigger: A scheduled saved search ranks every detection by false-positive rate. The noisiest cross into the tuning queue; Squelch fires on those. Label normalization happens here via disposition_normalization.csv.
Splunk MCP Server (v1.1.3): Squelch integrates with the Splunk MCP Server for read-only data collection — 10 built-in tools (SPL queries, index metadata, saved searches) plus one custom BYOT tool (squelch_fp_rates_by_search) that exposes live FP-rate data to peer agents. Write paths and custom command invocation go through splunklib SDK directly, because MCP's command allowlist (safe_spl.json, 143 commands) excludes custom SPL commands. This is a documented architectural boundary: MCP for reads, SDK for writes.
LLM integration: Gemini 2.5 Flash via direct HTTPS from within the custom command. The LLM's job is narrow: given an original SPL query and a cluster of safe-to-filter values, produce the original SPL verbatim plus exactly one NOT {field} IN (...) clause. A structural validator (_structurally_valid()) rejects rewrites of the original query and requires a NOT clause to be present. A syntax checker runs the proposed SPL through Splunk (| head 0) to catch parse errors. The LLM is a component, not the product.
The eval harness is the core engineering:
evaluate_detection()computes event-level precision and recall using Splunk's_cdfield for individual event identity — not aggregate countsgate_revision()is a hard recall-preservation gate:proposed.recall >= baseline.recallor the revision is rejected, with the specific dropped event IDs capturedrun_adversarial_eval()parses the proposed NOT filter, picks a target value at random (seeded RNG), synthesizes a true-positive event with that exact field value, injects it, and re-evaluates. If recall drops, the value is excluded from the filterperturb_and_eval()uses SHA-256-seeded, namespaced RNG for reproducible trials — same detection name and trial index always produce the same label flipstemporal_holdout_eval()queries the labeled dataset for min/max_time, computes the split point, and runs fourevaluate_detection()calls: baseline×training, baseline×holdout, revised×training, revised×holdout
Label normalization: A lookup (disposition_normalization.csv) maps analyst label formats to two canonical values. For BOTSv3, labels derive from the published attack scenario — coinhive cryptominer domains are true positives, everything else is a false positive. The normalization layer is built to handle the inconsistent label formats of production SOC data, not just clean scenario labels.
GitHub integration: Per-detection branches (squelch/tune/{slug}-{epoch}). PRs include SPL file commits (original + revised), eval before/after tables, attack injection results, FP cluster analysis, label sensitivity badges, temporal stability sections. The decline-to-tune path files Issues with diagnostic evidence. Credentials stored in Splunk's storage/passwords.
Named constants govern behavior, not magic numbers:
| Constant | Value | What it controls |
|---|---|---|
MIN_TOP_ENTRY_FP_PCT |
0.20 | Minimum explanatory power for a cluster to be filterable |
PERTURB_RECALL_PASS_THRESHOLD |
0.05 | Max recall delta under 10% label flip |
HOLDOUT_SPLIT_PCT |
0.70 | 70% training, 30% holdout |
HOLDOUT_PRECISION_FLOOR_DELTA |
0.0 | Holdout precision must not degrade |
DIAGNOSE_EMPTY_THRESHOLD |
0.30 | Field empty in >30% of FPs triggers diagnosis |
DIAGNOSE_SOURCETYPE_THRESHOLD |
0.80 | >80% of empties from one sourcetype → extraction gap |
Scale: 4,833 Python LOC across 7 modules. Solo builder.
Challenges we ran into
Real data breaks things synthetic data doesn't. Running against BOTSv3 surfaced bugs that never appeared in development:
ConfigParser crash on % characters in SPL. BOTSv3 detections contain
%in field values. Python's ConfigParser interprets%as interpolation syntax and throws. Never triggered on development data because no test SPL contained the character.NOT clause after
| wheresilently returned 0 rows. The proposed SPL filter was syntactically valid but semantically dead — Splunk accepted it, returned an empty result set, and the eval reported perfect precision (0/0). A structural position check now verifies the NOT clause appears before any| where._get_time_boundariesdouble-search prefix and wrong time window. The temporal holdout function was prepending the search command prefix twice, producing malformed SPL that Splunk silently accepted with a narrower time window than intended.
These surfaced only against data we didn't control. That's the case for validating on public datasets instead of your own synthetic fixtures.
MCP can't invoke custom commands. Splunk's MCP Server has a 143-command allowlist (safe_spl.json) that rejects custom SPL commands like | squelch. BYOT tools work for read-only queries wrapped in allowlisted SPL, but the write path (running the tune pipeline) goes through splunklib SDK directly. This is a genuine architectural finding, not a workaround — MCP for reads, SDK for writes.
The shared-branch 422 problem. Early builds used a single squelch/proposals branch for all PRs. GitHub only allows one open PR per head branch, so the second detection's PR would 422. Fixed with per-detection timestamped branches (squelch/tune/{slug}-{epoch}), making collisions vanishingly rare.
Accomplishments that we're proud of
The decline-to-tune beat. Squelch's most impressive moment is when it refuses to generate output — because the false positives are caused by a field extraction gap, not by a filterable pattern, and a filter would mask the real problem. An agent that knows when NOT to act is harder to build than one that always acts.
Validated on data we didn't author. BOTSv3 is Splunk's own public attack dataset. The labels come from the published scenario, not from our judgment. Every number — the 73% FP reduction, the 1.000 recall, the 0% field coverage that triggered the decline — traces to data any judge can download and verify.
The attack injection caught a real conflict. The harness proposed 9 IPs for the NOT filter. IP 172.16.0.13 was in the filter candidate set AND carried coinhive cryptominer lookups — true-positive traffic. The attack injection found it, excluded it, and shipped 8 instead of 9. Not a synthetic test scenario — the harness catching an actual safety problem in its own proposal, on real data, autonomously.
Every number is verified. When the perturbation test returned WARN on the DNS detection (21 TPs is too small for a meaningful flip test), we reported WARN — not PASS, not "inconclusive." Honest reporting over clean numbers.
The eval harness ships standalone. | squelch mode="eval" runs precision, recall, perturbation, and holdout against any detection with zero side effects — no clustering, no LLM, no GitHub. It's the on-ramp: install the eval harness, get numbers on your existing detections, decide later if you want the agent.
What we learned
The validation harness took 3x longer to build than the LLM integration. call_gemini() is ~20 lines. evaluate_detection() is ~100. run_adversarial_eval() is ~75. perturb_and_eval() is 80+. temporal_holdout_eval() is 70+. The generation was a weekend. The validation was the project. This confirmed the thesis: the hard part isn't writing the fix — it's proving the fix is safe.
Detection engineering is an eval problem, not a generation problem. The industry has plenty of tools that generate SPL. Nobody has built the eval harness. The gap isn't "write better queries" — it's "prove the queries you wrote are safe." Squelch exists because that gap exists.
Named constants > magic numbers. Every threshold in Squelch is a named constant with a comment explaining the choice. MIN_TOP_ENTRY_FP_PCT = 0.20 is readable, auditable, and tunable. if fp_pct > 0.2 buried in a function is none of those things.
What's next for Squelch
Beyond NOT filters. The eval harness validates any SPL revision regardless of type. The current agent generates NOT filters — the simplest, safest class of detection change. The architecture supports time-window exclusions, lookup-based filters, and field-value combinations as the generation layer matures. The eval harness doesn't care what the LLM proposes. It cares whether the proposal is safe.
Complex SPL support. Production detections reference macros, eventtypes, lookup tables with staleness concerns, CIM field aliases, and nested search constructs. Extending the triage step to parse macro definitions, check lookup freshness, and resolve field aliases is the primary next-tier engineering challenge.
Production label collection. BOTSv3 labels come from a published scenario. Production deployment requires real analyst dispositions — integrating with case management systems for live label data. The label normalization layer already handles inconsistent formats; the missing piece is the ingestion path.
Lightweight eval App. The next step is packaging | squelch mode="eval" as a standalone Splunk App — five minutes to install, zero commitment, value on day one. No LLM, no GitHub, no agent required.

Log in or sign up for Devpost to join the conversation.