-
-

Logo
-
Website

Inspiration
One of the emerging use cases for computer vision within cybersecurity is to detect heavily obfuscated malware. In a research paper published in 2021 titled "Malware Detection Using Frequency Domain-Based Image Visualization and Deep Learning", the authors achieved an accuracy of around 83.6% using after training a model to classify whether or not an executable was malware. They generated an greyscale image to represent the binary before passing it to the model. We wanted to expand on this research by looking instead at PDFs. Phishing attempts frequently rely on users downloading malicious attachments and then opening them on their machines, resulting in malware execution. Our goal was to create a proof of concept to see if we could detect malicious PDFs using a similar technique as the paper.
What it does
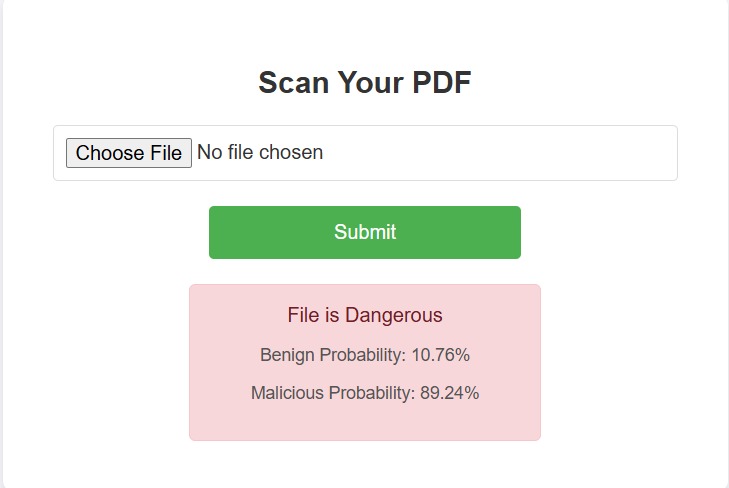
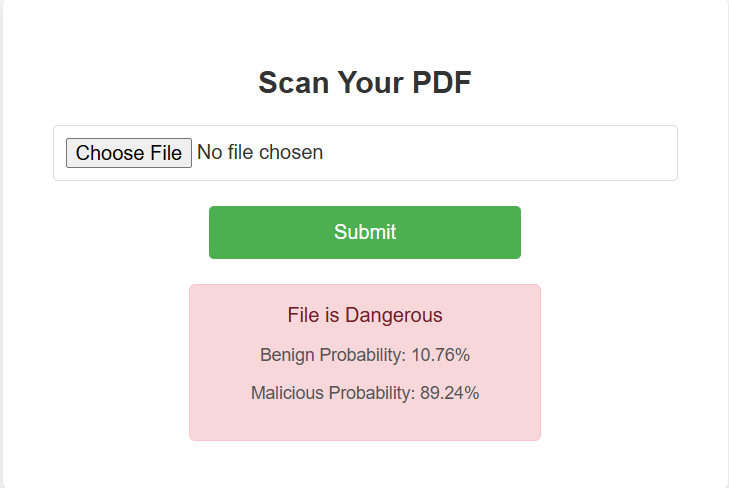
Our application is a Django application which allows users to upload a PDF. After uploading, the application will process the PDF, and then inform the user whether or not it contains a virus.
How we built it
We used over 1000 benign PDF records from the CIC-Evasive-PDFMal2022 dataset and malicious PDFs from the VirusShare dataset.
We trained a classification model on Edge Impulse using an 80/20 split, which achieved an accuracy of 85.2%. The model was then deployed using Edge Impulse's API and used to classify PDFs on a Django application which supports uploading PDFs. On being uploaded, the file is converted into a greyscale byte plot PNG. We then convert the PNG into a numpy array which is then passed to the model via an API. The model then classifies the image and the Django app displays the returned results to the user.
Challenges we ran into
One of the biggest challenges we ran into was extracting the features from an image. Edge Impulse represents the images as 65336 hex bytes. The methods to reach the processed hex bytes are not shown. We decided to represent the images as raw hex bytes as the model can still classify from this information, but we were having some trouble getting the hex bytes into a format the model would understand. Ultimately, we decided to use Edge Impulse's API to sidestep this issue. Another issue was the accuracy of results when testing safe PDFs on our own devices.
Accomplishments that we're proud of
One of the more interesting tasks we had to complete was converting over 1200 malicious PDFs into byte plots. Given the nature of the PDFs, we had to complete this process on a secure environment, which we did. We are also proud of our model's accuracy. It closely matches the paper we were inspired by and is exceptionally high given the amount of data we provided.
What we learned
We learned how to create a data pipeline analyzing malicious data.
What's next for Squeaky Clean PDF
We want users to easily be able to use Squeaky Clean PDF to protect their devices. The next step is to create a Google Chrome Extension to allow users to analyze PDFs before they download them. We would also want to extend this application to analyzing email attachments. Additional data from other sources is needed and would greatly improve the model. To address the accuracy issue of PDFs on our devices, we would increase the variety of PDFs in our dataset.




Log in or sign up for Devpost to join the conversation.