-
-
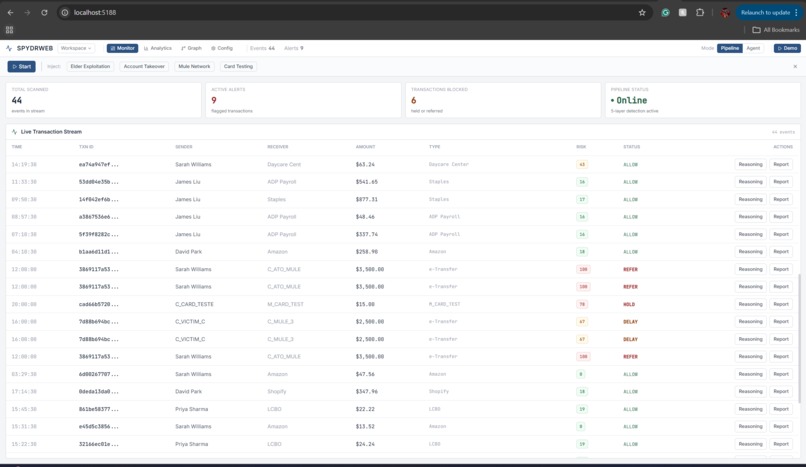
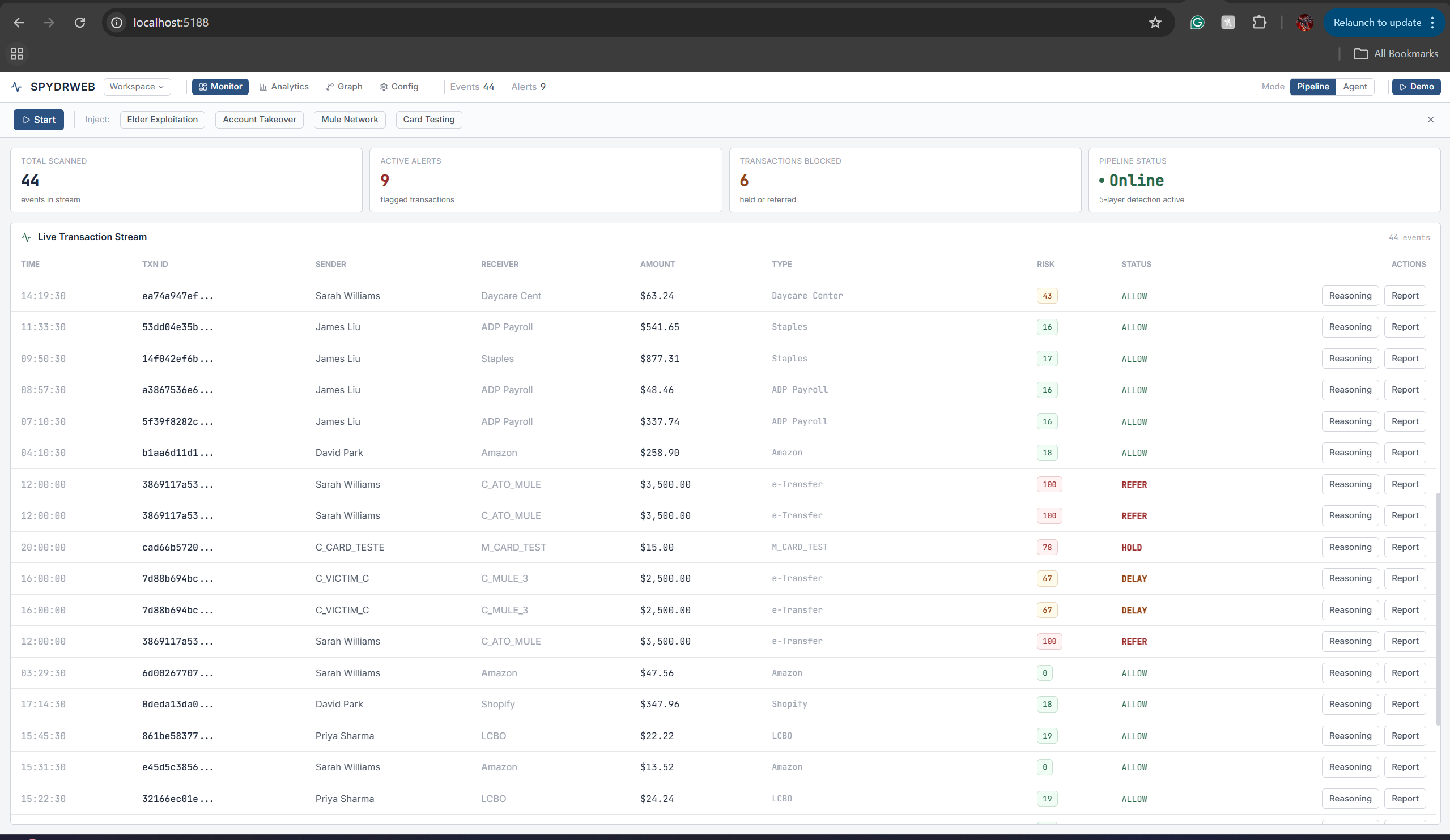
Main Dashboard with Demo and Transaction Logs
-
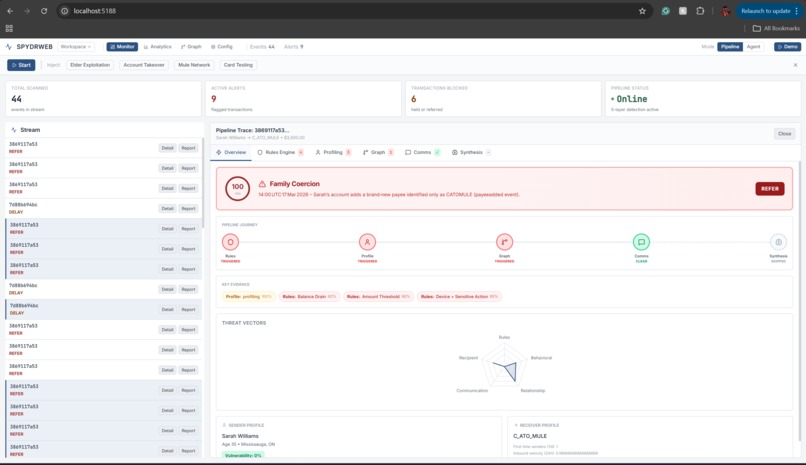
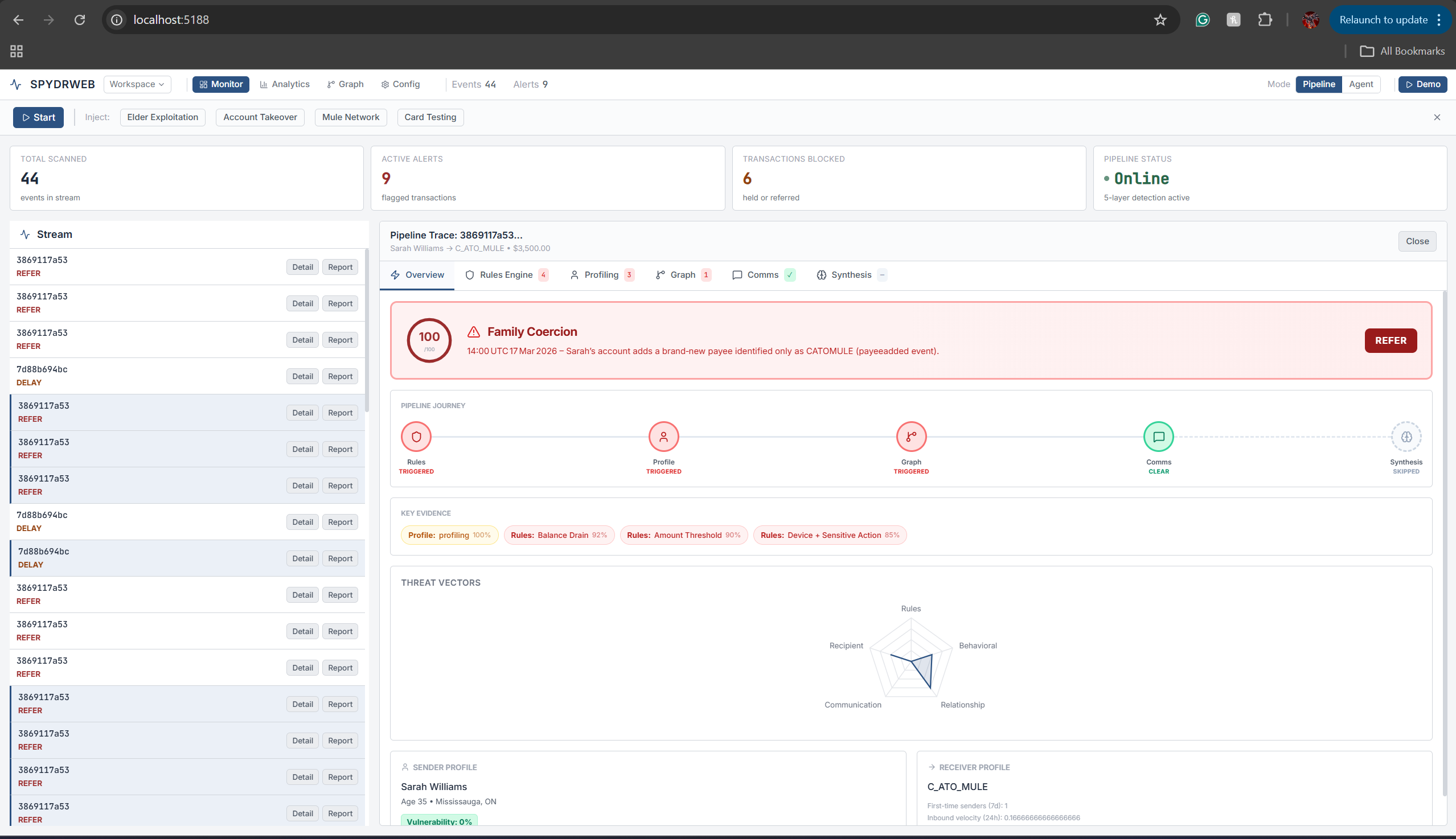
Reasoning for flagging
-
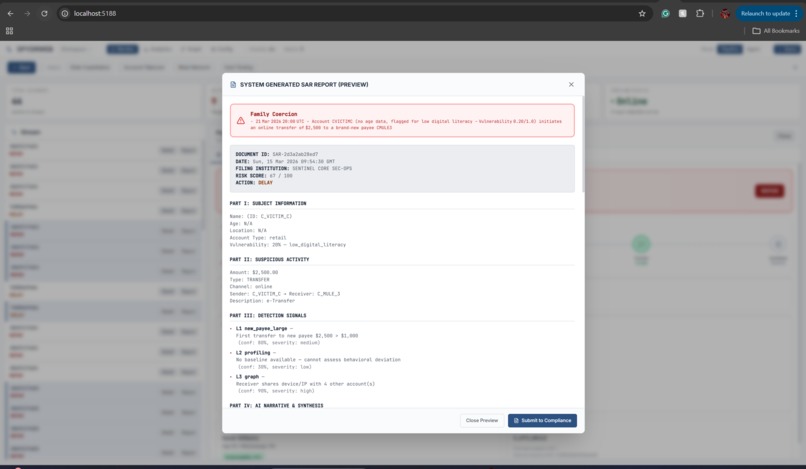
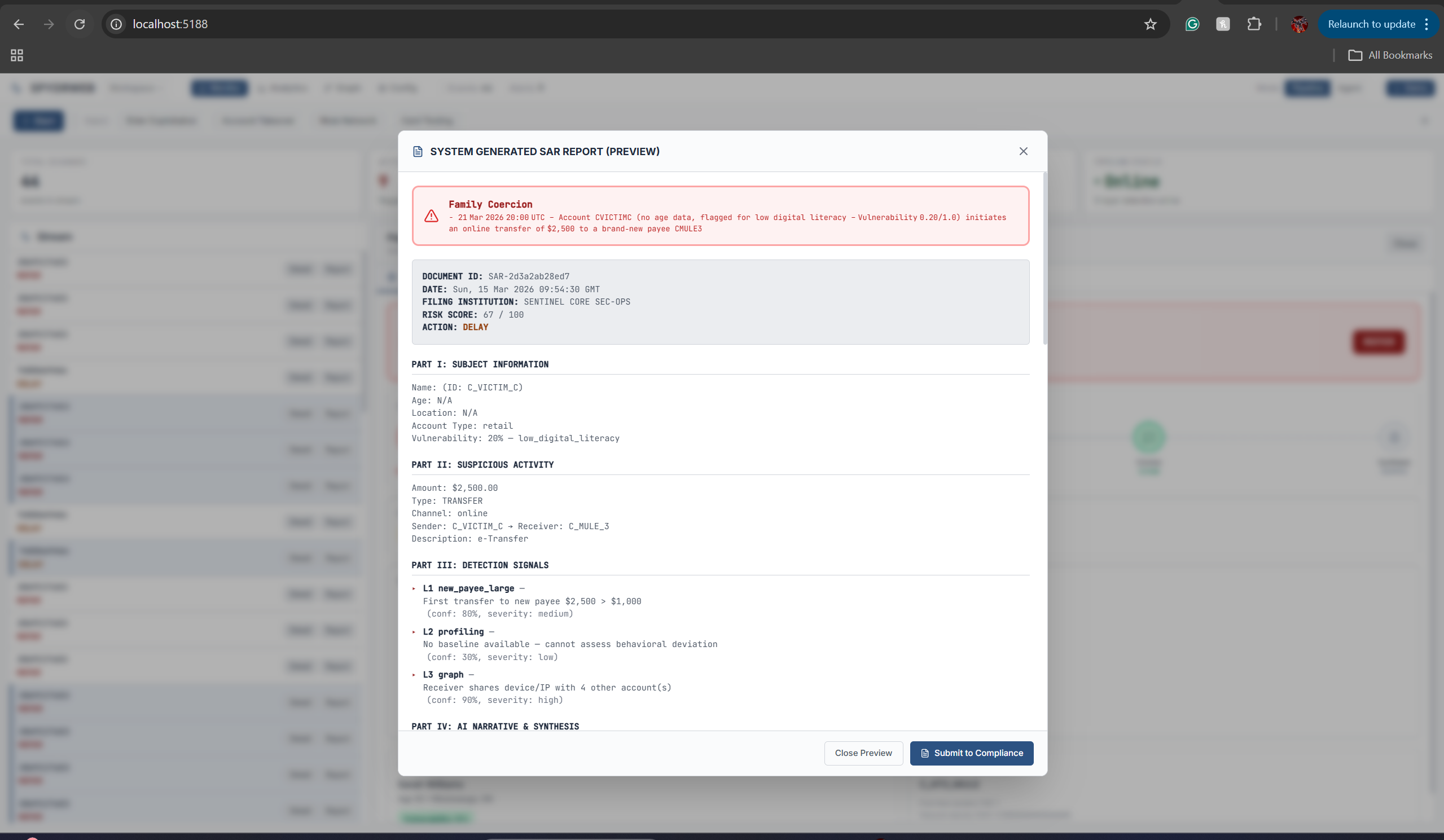
Report
-
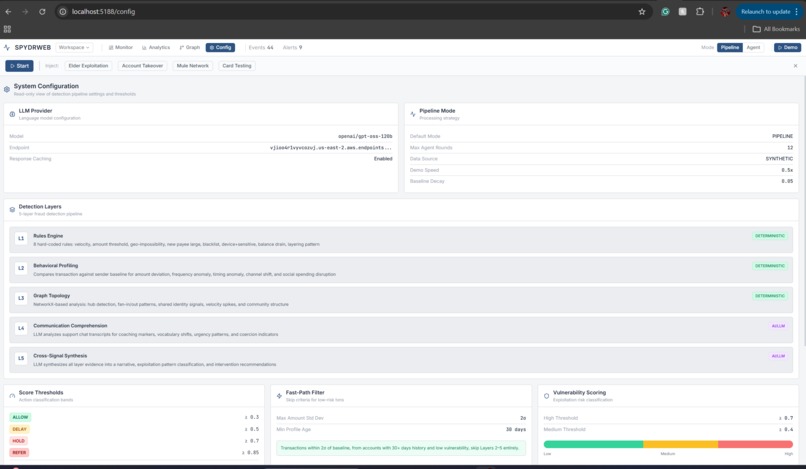
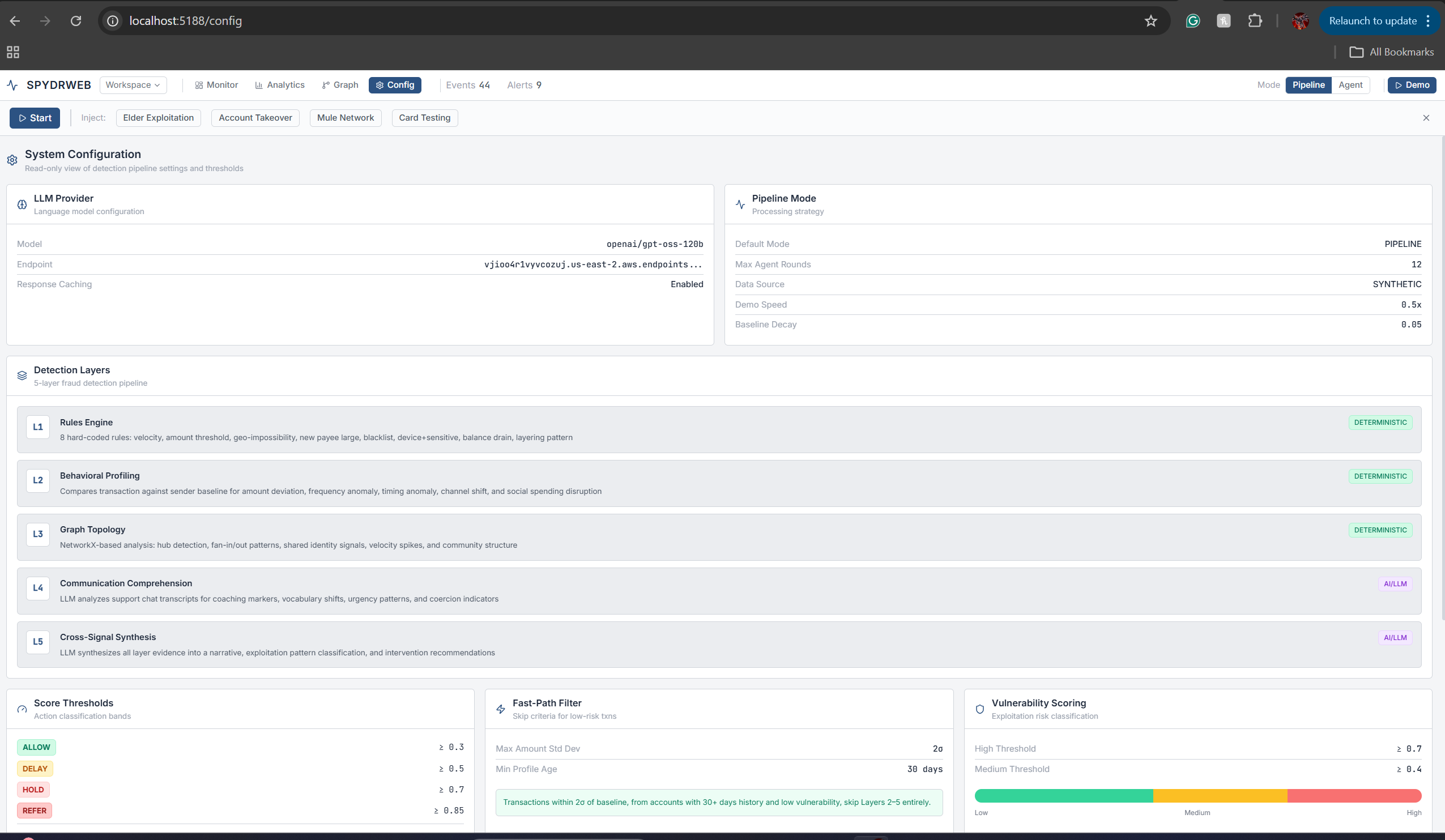
LLM/System Configuration
-
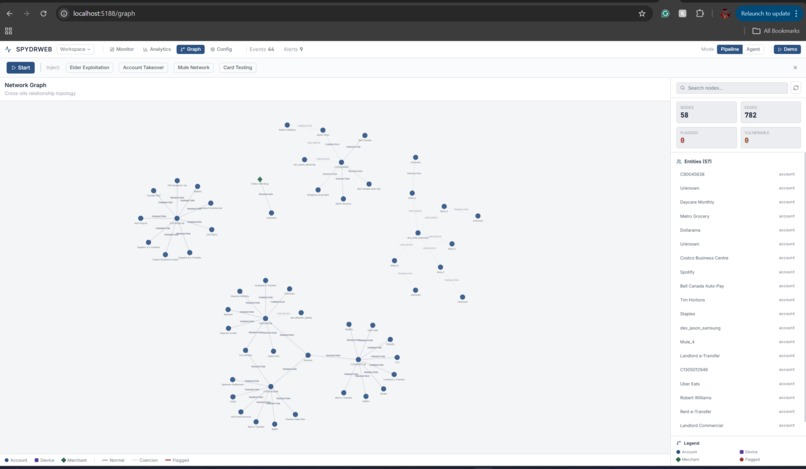
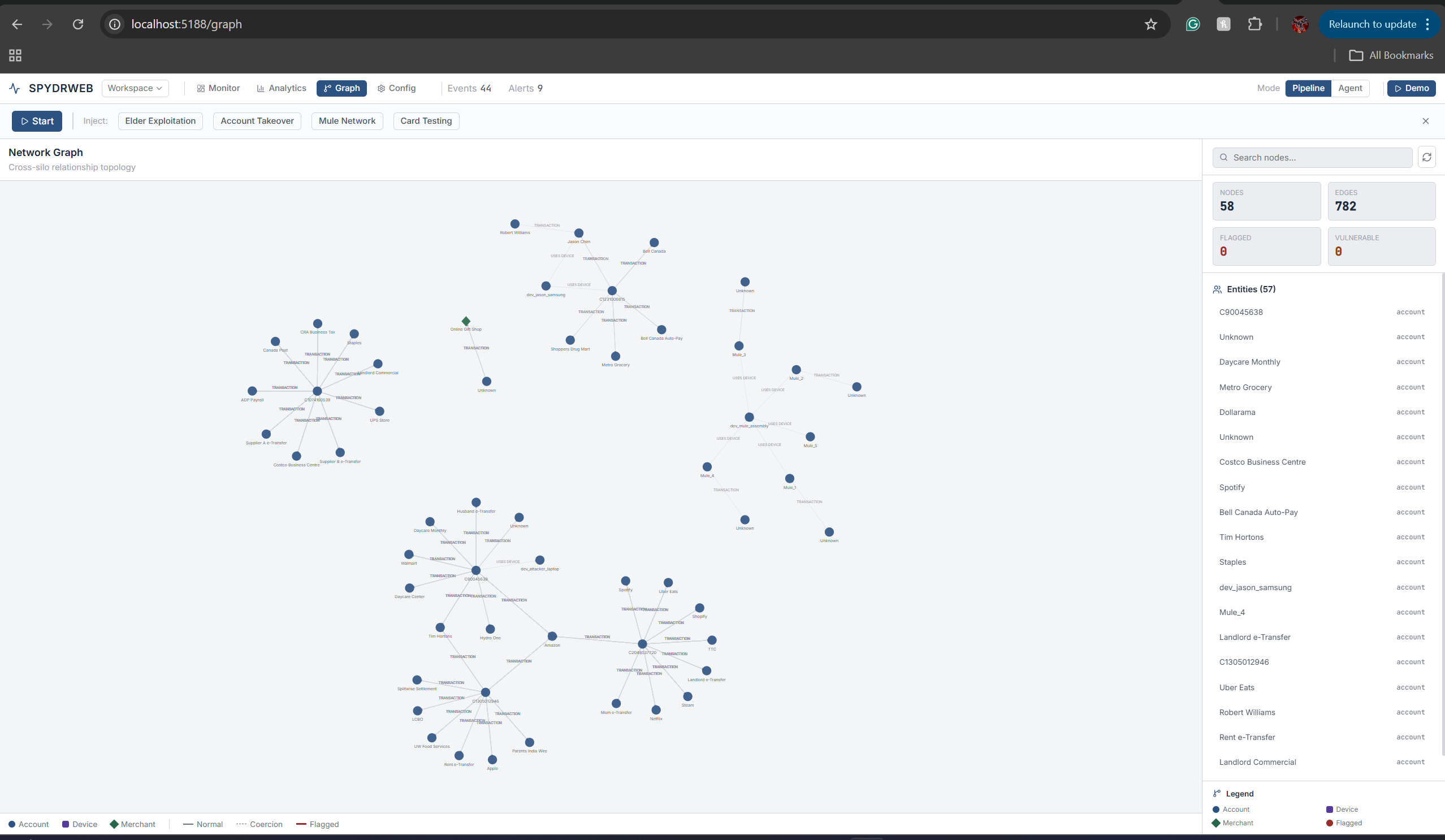
Graph Network
-
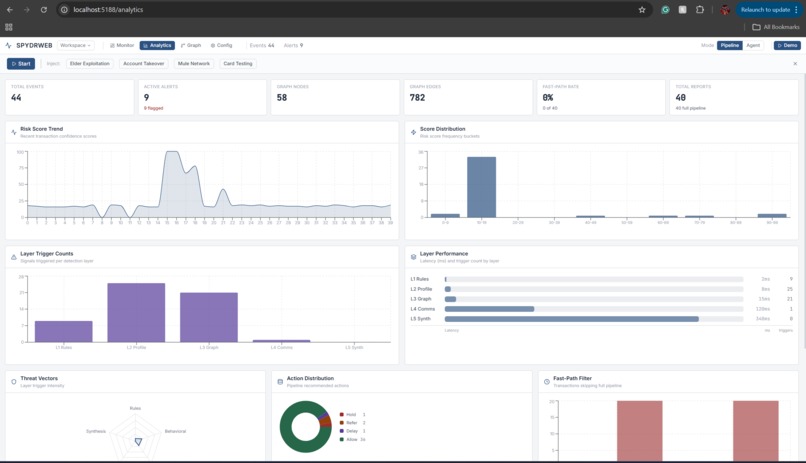
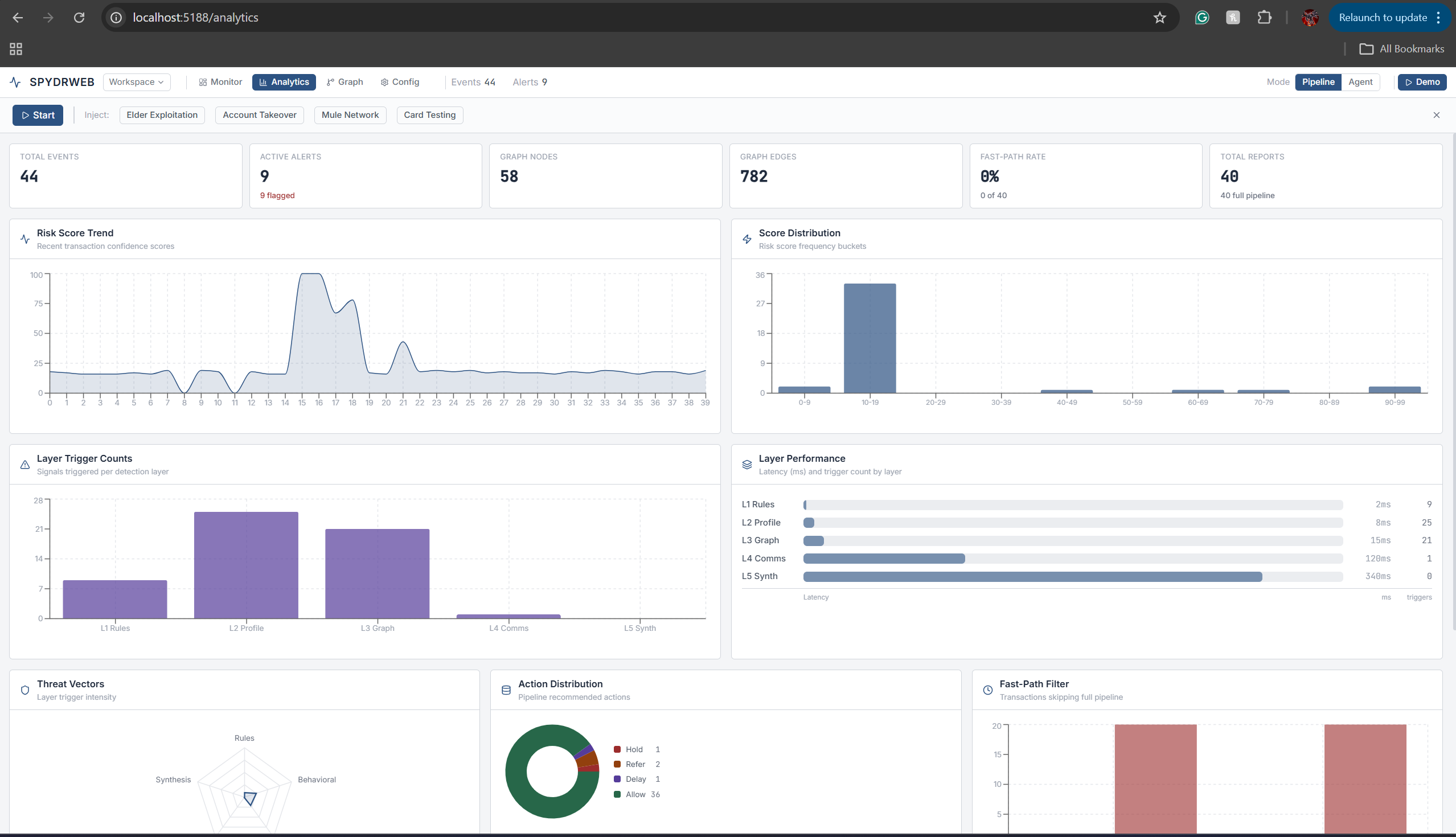
Analytics Page
Inspiration
Most fraud systems are black boxes: they flag transactions but don’t explain why. Analysts see a score and must dig through logs and dashboards to understand what happened. That slows investigations and makes it hard to trust the system.
We wanted a system that explains its reasoning, one that combines rules, behavioral baselines, graph analysis, and LLM reasoning into a single, interpretable pipeline. Practitioner-led fraud frameworks emphasize modularity, human-in-the-loop design, and auditability. SpydrWeb is built around those ideas: every decision can be traced back to specific signals and evidence.
What it does
SpydrWeb is an explainable fraud detection system that runs every transaction through a 12-step pipeline. It combines deterministic rules (velocity, balance drain, layering), behavioral profiling (baseline deviations, absence detection), graph analysis (hubs, bursts, mule patterns), and LLM reasoning (chat logs, branch notes) into a single flow. Each decision is tied to specific signals and evidence, so analysts see why something was flagged, not just that it was. A fast-path filter skips AI for clearly low-risk transactions to keep latency low, and alert bundling groups related accounts into single cases to reduce analyst fatigue.
How we built it
We built a FastAPI backend with Pydantic models and a React + Vite + Tailwind frontend. The pipeline is orchestrated by a central PipelineOrchestrator that runs each transaction through five detection layers, a shared LayerSignal contract, and a DetectionLayer ABC so layers can be swapped or extended without changing the orchestrator. The graph uses NetworkX; the frontend uses D3 for visualization. Synthetic data comes from persona-based generators (7 personas, 90 days of history) and four fraud scenarios: elder exploitation, account takeover, mule network, and card testing. We use an OpenAI-compatible LLM with a response cache for stable demo behavior.
- Event logging — Append to an immutable event stream
- Graph update — Add transaction edges to a NetworkX graph
- Profile resolution — Load or build sender/receiver profiles
- Vulnerability & recipient risk — Compute account and recipient scores
- Layer 1 (Rules) — Deterministic checks (velocity, balance drain, layering, device change)
- Fast-path check — Skip AI for clearly clean transactions
- AI fraud-type prediction — LLM suggests likely fraud types
- Layers 2–4 — Profiling, graph analysis, LLM comprehension
- Brain overlay — Structural context from the graph
- Layer 5 (Synthesis) — LLM combines signals into an evidence brief
- Scoring — Weighted formula with corroboration bonus: [ \text{score} = \min\left( \left( \text{weighted_sum} + \beta \cdot (n_{\text{triggered}} - 1) \right) \cdot \mu_{\text{vuln}} \cdot \mu_{\text{vel}}, 1 \right) ]
- Action & alert bundling — Recommend ALLOW/HOLD/REFER and group related alerts
Challenges we ran into
Integrating five layers cleanly. Each layer has different inputs and outputs. We introduced a shared LayerSignal contract and a DetectionLayer ABC so layers can be swapped or extended without changing the orchestrator.
LLM reliability in demos. LLM responses can vary and add latency. We added a response cache keyed by transaction context so repeated runs return stable results during demos.
Graph velocity at scale. Tracking edge velocity per node in real time can get expensive. We use a GraphVelocityMonitor with configurable time windows and baseline comparisons, and we only run it for transactions that pass the initial rules.
Balancing explainability and performance. More layers mean more context and better explanations, but also more compute. The fast-path filter lets us keep full explainability for suspicious transactions while keeping latency acceptable for the majority of traffic.
Accomplishments that we're proud of
We built a full end-to-end pipeline with all five detection layers wired and working. We added recipient risk scoring to surface collection accounts and mules that sender-only systems often miss. We implemented time-weighted baselines with exponential decay so recent behavior matters more than old history. We designed the system so every decision is traceable to the immutable event stream. We created a live demo with synthetic personas and four fraud scenarios that runs without external datasets. Our final system also accomplishes both the task of catching what humans miss and catching what traditional AI systems miss.
What we learned
Multi-layer detection beats single models: layering rules, profiling, graph analysis, and LLM comprehension gives better coverage and clearer explanations. Recipient-side analysis is essential—recipients that receive from many first-time senders with little outbound flow are often collection points. Time-weighted baselines matter for catching account takeover where an attacker’s behavior diverges from months of normal activity. Fast-path filtering is critical for keeping latency low while still running the full pipeline on suspicious cases. Practitioner-led design principles—modularity, human-in-the-loop, auditability—made the architecture easier to extend and reason about.
What's next for SpydrWeb
Agentic investigation mode — The plan includes an Investigator Agent that uses an LLM with tool-calling to explore events, graph, and baselines on demand. We’d wire this as an alternate mode so analysts can switch between the fixed pipeline and an agent-driven investigation.
PaySim integration — Add PaySim as a data backbone alongside synthetic generators, with calibration from public datasets (IEEE-CIS, Feedzai BAF) to ground the system in real transaction patterns.
Real-time WebSocket streaming — Push new transactions and alerts to the frontend as they’re processed, and broadcast alerts when fraud is detected so the dashboard updates live without refresh.
Transaction log redesign — Implement the master–detail layout with risk bands (green/yellow/red), expandable rows for LLM reasoning and reports, and links to the graph view for flagged transactions.
Analyst feedback loop — Use the feedback store to retrain or tune layer weights and thresholds based on analyst actions (confirm fraud, false positive, etc.).
Production hardening — Add persistence for the event stream and case reports, rate limiting, and deployment configs for cloud hosting.
Built With
- claude
- css
- cursor
- d3.js
- fastapi
- networkix
- openai
- pydantic
- python
- react
- tailwind
- typescript
- uvicorn
- vite
- websocket


Log in or sign up for Devpost to join the conversation.