-
-
Home Page
-
Team Page
-

Mission Page

Inspiration
In the rapidly evolving world of academic research, staying updated with the latest papers and identifying trends is crucial. However, the process of finding connections between new research and older foundational work can be overwhelming. For people with disabilities, it can be even more difficult to read and interpret heavy academic papers.
As computer science students passionate about advancing research accessibility, we wanted to simplify this process. Spyder was born out of a need to streamline the research process by offering a visualization tool that shows the intricate web of citations, concept mappings, and potential collaborators. This enables researchers to see the ripple effects of any single paper and easily explore its impact.
Our main motivation is the idea of making research accessible to people from all backgrounds, particularly those who may have disabilities that prevent them from focusing on papers or those who might not have a research background but are looking to break down dense academic content in ways that are clear and actionable.
What It Does

Spyder allows users to input an arXiv article ID and instantly generates:
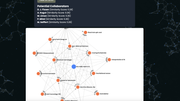
- A network visualization showing further work that has built upon the original article.
- A display of primary information such as the paper’s title, authors, abstract, and a breakdown of key ideas.
- A flowchart visualization of the core concepts, providing a simplified overview of the paper’s content.
- A feature for identifying potential collaborators by analyzing research methodologies and interests from the paper.
Additionally, for further accessibility, Spyder lets users upload images of physical research papers. Through optical character recognition (OCR) technology, it converts these documents into a series of visuals and a summarized, interpretable format. Our tool utilizes Perplexity’s AI to assist in summarizing the complex language of research papers, making them more digestible for a wider audience.
How We Built It
Spyder was developed using a robust tech stack:
- Backend: Python, FastAPI, Node.js, Express, MongoDB, Nginx, and Defang for secure backend functionality and database management.
- Frontend: React.js and TailwindCSS for a sleek, user-friendly interface.
- APIs and integrations: We employed the Perplexity API to leverage natural language processing and Tesseract for OCR capabilities.
- Deployment: The platform is hosted on Vercel, and we used Terraform for cloud infrastructure management.
- Domain: GoDaddy serves as our domain provider, ensuring that our platform is easily accessible with our domain name, spider.select.
Each of these technologies was carefully selected to optimize performance, scalability, and ease of use.
Sponsor Product Integrations:
- Defang: Deployed a Tesseract Python script as an API with three endpoints:
/create: Accepts a PDF, converts it into images, runs Tesseract, and outputs an OCR’d PDF./extract_text: Accepts a PDF, converts it into images, runs Tesseract, and outputs the OCR’d text as a string./clean: Cleans up all intermediary files created from the two POST requests.
- GoDaddy: Obtained the domain name, spider.select, for our branding.
- MongoDB: Each time a request is made to an arXiv paper or a physical paper is uploaded to our system through our OCR API, the data of these papers are added into our paper collection to cache previously searched papers and increase query speed. Here are the main functionalities we used:
- Query existing paper data in our collections when a user makes a search for an arXiv paper to reduce the waiting time and computational power
- Post paper data into collection when a user makes a search or uploads their physical paper in image/pdf formats
- Perplexity API: The Perplexity AI Pro API is fed the contents of the paper, either scraped from arXiv or generated by Tesseract, and returns a JSON response that is used to create a Mermaid.js flowchart of the inputted paper.
- Sauce Labs: Used for cross-browser and device testing for expected functionalities before hosting it on a cloud system.
Challenges We Ran Into
One of the biggest challenges was integrating Tesseract's OCR with Perplexity's language processing in a way that provides seamless, accurate summaries. We also ran into some difficulties when handling large citation networks, especially when visualizing papers with hundreds of references. Striking a balance between creating an intuitive user experience and maintaining the technical depth of the tool was also challenging, but we’re proud of where we landed.
Another challenge was ensuring accessibility for users unfamiliar with technical research terms, which required multiple iterations of UI/UX design.
Accomplishments That We're Proud Of
- Successfully implementing a network visualization of citation data that helps users instantly understand the scope of a paper’s impact.
- The OCR and language integration, allowing physical papers to be easily converted and understood digitally.
- We used TF-IDF (Term Frequency-Inverse Document Frequency) to analyze research papers, extracting key terms and concepts from the text. By applying this technique, we identified unique terms with high significance in a given paper, allowing us to match them with other researchers who have worked on similar topics.
- Creating a platform that democratizes research by being accessible to a broader audience, regardless of their technical background.
What We Learned
Through the workshops we attended, we learned about topics such as web/app development, LLM wrapping, databases, bioinformatics, and cybersecurity. To reinforce these concepts, we used some of them in our working project. For example, HTML/CSS/JS is used for our website, MongoDB is used to store and cache data, the Perplexity Pro API is used as an LLM wrapper for extracting meaningful information from raw articles, and data visualization is used with graphs to provide a more equitable ground for all scientists to interpret papers, regardless of their disabilities.
While building our product, we deepened our understanding of how to create tools that balance technical sophistication with accessibility. From integrating complex technologies like OCR and NLP to ensuring that our platform can scale for large datasets, every step was a learning experience. Collaboration was key, and we honed our ability to communicate effectively across team members with diverse skill sets.
What's Next for Spyder
As we are following a systematic issue-tracking system through GitHub, here are the next few task items we have in our list in the repository:
- Identify gaps in the current research based on the paper's content and its network.
- Analyze trends in the paper's field to suggest potential future research directions.
Apart from these improvements, in the future, we want to:
- Expand the network visualization capabilities to include cross-referencing from other research databases.
- Improve the collaborative feature by adding a recommendation system to suggest not just collaborators but related research areas based on user input.
- Develop a mobile-friendly version of Spyder.
- Continue refining our OCR process to make it more adaptable to non-standard formats.
Built With
- defang
- express.js
- fastapi
- godaddy
- javascript
- mermaid.js
- mongodb
- nginx
- node.js
- perplexity-api
- python
- react.js
- tailwind
- terraform
- tesseract
- vercel







Log in or sign up for Devpost to join the conversation.