Inspiration
We're all passionate about sustainability and solving the food security crisis, so we wanted to work on something related to this at HackTech. When we thought about potential approaches and examined the technologies and products currently deployed, we noticed that they were all either directed towards industrial-scale farmers or experienced home-gardeners. We believe that bridging people with resources to create home gardens and learn about farming will drive the next revolution in agriculture.
What it does
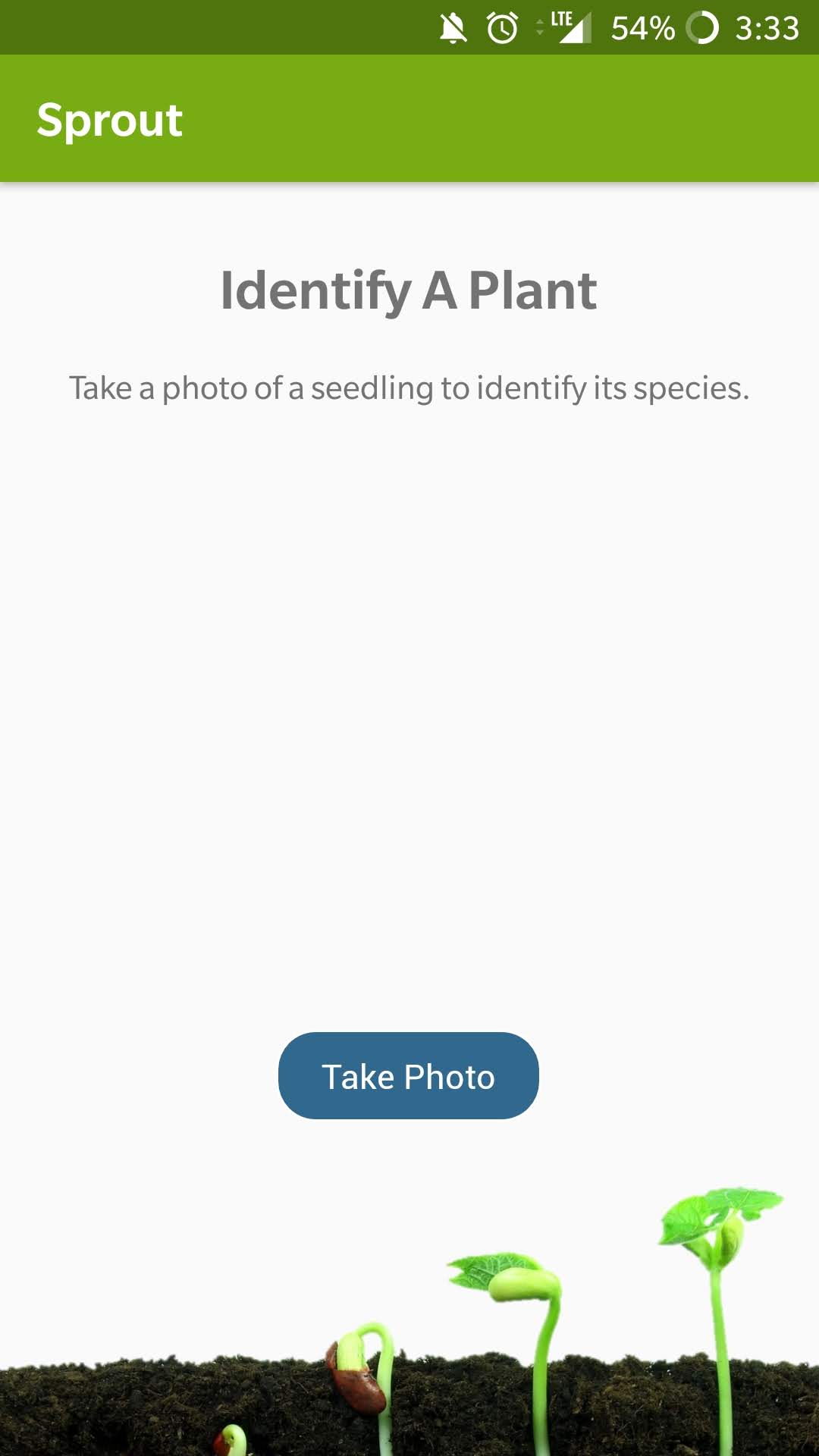
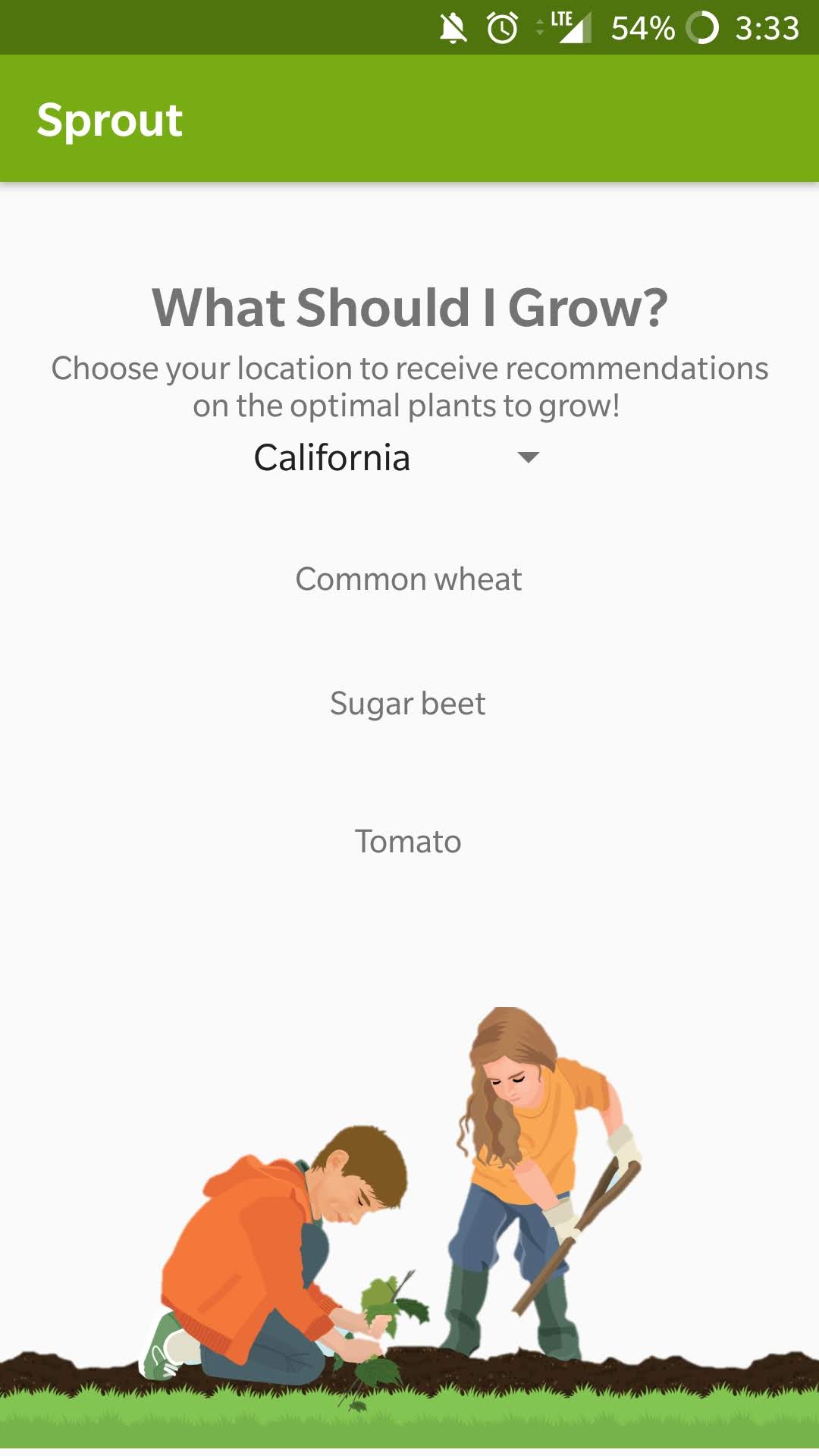
Our app has two main features. For one, we allow users to input their location and recommend the most optimal plants for them to grow based on a USDA open-source dataset. Our second feature is a seedling identification tool to help users become acquainted with different types of plants. It can be used to both distinguish desired crops from weeds and to give them ideas for plants to grow in their own garden.
How we built it
We've built out our application for Android. We parsed through and filtered thousands of lines of data to match locations and optimal home garden plants for our first feature. For the seedling identification tool, we implemented a convolutional neural network in Keras that takes in an image and classifies it into one of our categories. We trained the deep learning model on an open-source labeled dataset of seedling images. The app prompts the user to take a picture and processes it on-device using Google's TensorFlow Mobile architecture. This way, we do not need to interact with any cloud hosting platforms because our model is compressed and can run rapidly on a mobile device processor.
Challenges we ran into
We faced several issues with Android Studio, namely with our manifest file becoming corrupted and our neural net backend not cleanly integrating. Also, we struggled with the compatibility of some code due to Java/Kotlin updates which required us to constantly improvise and rethink our approach.
Accomplishments that we're proud of
We are proud that we were able to incorporate both core features of our application while also dedicating time to beautify the design and user interface. Although we are slightly limited by the data we had access to, we think we have laid a strong foundation for future deployment of this app.
What we learned
Naturally, we learned new libraries and development strategies, but the most valuable learning was in the process. We learned that even if we have written all of our back-end code and functionality, we need to constantly be aware of how we are integrating this into the front-end. Near the end of the hackathon, we raced to complete our design and the integration of our features, which may have been accelerated had we been more conscious about this starting out. Still, as most of our team's first hackathon experience, this was a very positive learning experience and we can't wait for the next one.
What's next for Sprout
We want to incorporate more data-driven insights into our application. We hope to expand our training dataset for the classifier to better our ability to identify various seedlings. Also, we will collect more data about the user and their preferences to optimize our recommendation system and take it beyond geography.
Built With
- android
- android-studio
- java
- kaggle
- keras
- kotlin
- open-source
- python
- tensorflow



Log in or sign up for Devpost to join the conversation.